Hadoop集群搭建及Hive的安装与使用
1、集群安装与配置
以centos为例,首先创建4台虚拟机,分别命名为hp001、hp002、hp003、hp004。
安装成功后,然后分别修改主机名(hp002、hp003、hp004同hp001)。
vim /etc/sysconfig/network # 编辑network文件修改
hostname hp001
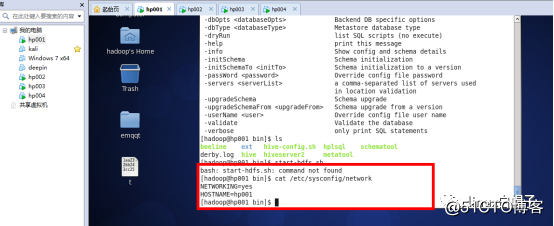
cat /etc/sysconfig/network
cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hp001
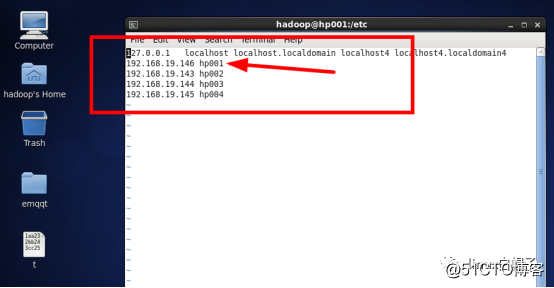
再修改/etc/hosts文件(hp002、hp003、hp004同hp001),本机IP对应主机名。
二、shell脚本编写
1、配置ssh
注意在root账号下创建,否则没有权限。
1)安装ssh
yum apt-get install ssh
2)生成密钥对
ssh-keygen –t rsa –P ‘’ –f ~/.ssh/
cd ~/.ssh
3)导入公钥数据到授权库中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp /root/.ssh/* hp002@:/root/.ssh/
scp /root/.ssh/* hp003@:/root/.ssh/
scp /root/.ssh/* hp004@:/root/.ssh/
4)登录其他机器:
ssh hp002
Ifconfig
2、scp
3、rsync 远程同步工具 主要备份和镜像支持链接,设备。
rsync –rvl /soft/* hadoop@hp002:/soft
4、自定义脚本xsync,在集群上分发文件,循环复制文件到所以节点的相同目录下,
在hp001主机上/usr/loca/bin下创建xsync文件
然后 vi xsync编写如下代码保存
#!/bin/bash
pcount=$#
if(( pcount<1 )) ; then
echo no args;
exit;
fi
#获取文件名称
p1=$1;
fname=`basename $p1`;
dname=`cd -P $(dirname $p1) ; pwd`
curse=`whoami`;
for(( host=2 ; host<5; host=host+1 )) ; do
echo ===================== copy to hp00$host ============
rsync -rvl $dname/$fname $curse@hp00$host:$dname;
done
echo ========================== end =====================
4、编写/usr/local/bin/xcall脚本,在所有主机上执行相同的命令。
例如:xcall rm –rf /soft/jdk
在hp001主机上/usr/loca/bin下创建xcall文件
然后 vi xcall编写如下代码保存
#!/bin/bash
pcount=$#
if(( pcount<1 )) ; then
echo no args;
exit;
fi
#
echo =========== localhost =========
$@
for(( host=2 ; host<5; host=host+1 )) ; do
echo ===================== exe hp00$host ============
ssh hp00$host $@
done
echo ========================== end =====================
三、各主机jdk安装
1、下载jdk上传到hp001上
jdk_1.8.0_131.tar.gz
tar -zxvf jdk_1.8.0_131.tar.gz到/usr/local/jdk目录下
然后用xsync命令分别在hp002、hp003、hp004创建/usr/local/jdk目录,用xcall
命令分别复制到hp002、hp003、hp004。
2、配置jdk环境变量,etc/profile文件中
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
用xcall命令分别复制到hp002、hp003、hp004的etc/profile文件中。
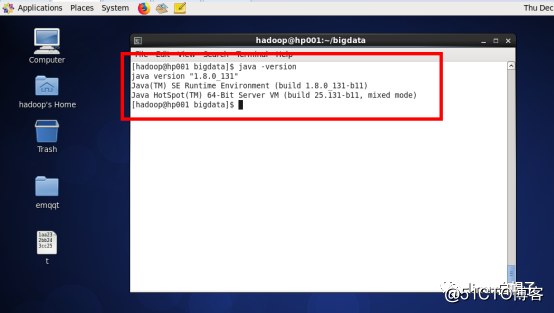
3、验证安装是否成功
四、Hadoop集群搭建
1、本机集群机器:四台对应hadoop1、hadoop2、hadoop3、hadoop4
hadoop1 node1作为名称节点
hadoop2 node2作为辅助名称节点
hadoop3 node3作为数据节点
hadoop4 node4作为数据节点
2、安装hadoop
创建目录/home/hadoop/bigdata/,下载hadoop-2.7.2.tar.gz,上传解压tar -zxvf hadoop-2.7.2.tar.gz。用xcall命令分别复制到hp002、hp003、hp004。
3、配置环境变量etc/profile文件中
export HADOOP_HOME=/home/hadoop/bigdata/hadoop-2.7.2
export PATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
用xcall命令分别复制到hp002、hp003、hp004的etc/profile文件中。
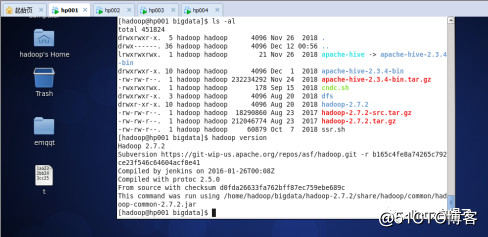
4、验证安装成功
hadoop version
5、hadoop集群配置
完全分布式配置方式:配置文件/home/hadoop/bigdata/hadoop-2.7.2/etc/hadoop/下的四个xml文件。
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hp001</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/bigdata</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hp002:50090</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hp001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
/home/hadoop/bigdata/hadoop-2.7.2/etc/hadoop/slaves文件修改为
hp003
hp004
在集群上分发以上5个文件
cd /home/hadoop/bigdata/hadoop-2.7.2/etc/hadoop
xsync core-site.xml
xsync hdfs-site.xml
xsync mapred-site.xml
xsync yarn-site.xml
xsync slaves
6、首次启动hadoop
1)格式化文件系统
$>hadoop namenode -format
2)启动所有进程
$>start-all.sh
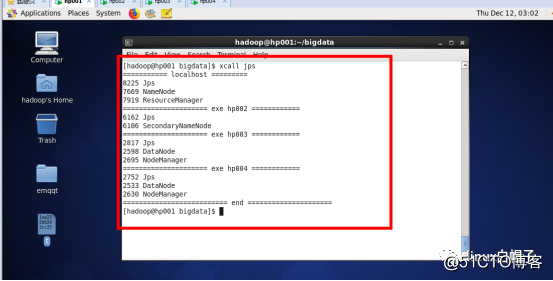
3)查询进程
$>xcall jps
4)停止所有进程
$>stop-all.sh
5)查看文件系统
$hadoop fs -ls
6)创建文件系统
$>hadoop fs –mkdir –p /user/Ubuntu/data
$>hadoop fs –ls –R /
7、Hadoop包含三个模块
1)Hadoop common:
支持其他模块的工具模块
2)Hadoop Distributed File System (HDFS)
分布式文件系统,提供了对应用程序数据的高吞吐量访问。
进程:
NameNode 名称节点NN
DataNode 数据节点DN
SecondaryNamenode 辅助名称节点2ndNN
3)Hadoop YARN:
作业调度与集群资源管理的框架。
进程
ResourceManager 资源管理 — RM
NodeManager 节点管理器—NM
4)Hadoop MapReduce:
基于yarn系统的对大数据集进行并行处理技术。
8、使用webui访问hadoop hdfs
1) hdfs http:/hp001:50070
2) dataNode http://hp003:50075
3) 2nn http://hp002:50090
五、hive安装与使用
1、下载hive
下载apache hive -2.3.4.bin.tar.gz
2、安装hive
cd /home/hadoop/bigdata/
tar -zxvf Apache Hive -2.3.4.bin.tar.gz
ln -s apache hive -2.3.4.bin apache hive
3、配置环境变量etc/profile文件中
export HIVE_HOME=/home/hadoop/bigdata/apache-hive
export PATH=.:$HIVE_HOME/bin:$PATH
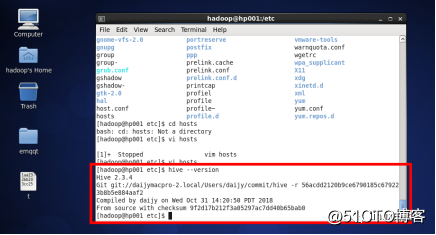
4、查看是否安装成功
hive --version
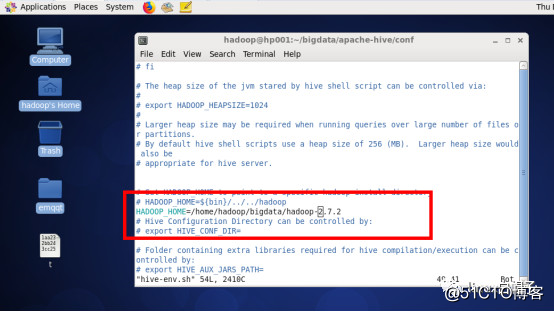
6、配置hive
修改/home/hadoop/bigdata/apache-hive/conf/hive-env.sh文件指定hadoop目录
/home/hadoop/bigdata/apache-hive/conf/hive-default.xml.template 默认配置文件不要修改,创建hive-site.xml:/home/hadoop/bigdata/apache-hive/conf/hive-site.xml,替换hive-site.xml中${system:java.io.temp.dir}=/home/hadoop/bigdata/apache-hive。
7、配置Hive元数据库
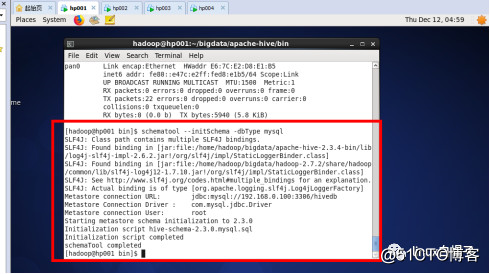
Hive使用rdbms存储元数据,内置derby数据库。在/home/hadoop/bigdata/apache-hive/bin/目录下初始化schema库,要启动hadoop集群:
Schematool --initSchema -dbType derby
8、hive启动
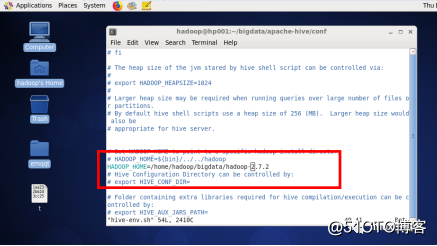
1、进入hive shell
$hive启动后如下图。
2、Hive元数据库mysql使用及常用命令
Hive配置
Hive常见命令类似于mysql,本例子用mysql作为hive元数据库,首先配置hive-sxit.xml的mysql数据库驱动信息。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.0.100:3306/hivedb</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456789</value>
<description>password to use against metastore database</description>
</property>
</property>
Mysql数据库配置
1)创建数据库hivedb
2)赋予hive连接mysql用户的权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456789' WITH GRANT OPTION
3) 将mysql的驱动包放到hive下
放在/home/hadoop/bigdata/apache-hive/lib/下
4)使用schematool初始化元数据。
schematool --initSchema -dbType mysql
HDFS存储位置配置
Hive配置文件里要用到HDFS的一些路径,需要先手动创建。
hadoop fs -mkdir -p /soft/hive/warehouse
hdfs dfs -mkdir -p /soft/hive/tmp
hdfs dfs -mkdir -p /soft/hive/log
hdfs dfs -chmod g+w /soft/hive/warehouse
hdfs dfs -chmod g+w /soft/hive/tmp
hdfs dfs -chmod g+w /soft/hive/log
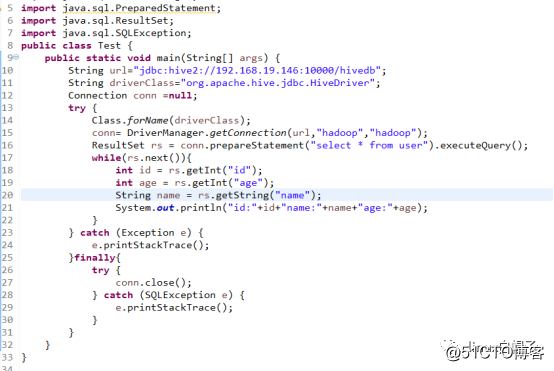
3、java连接hive
1)启动hive服务
/home/hadoop/bigdata/apache-hive/bin目录下执行命令$hive --service hiveserver2 start。
2) java代码连接hive到mysql中查询数据
Hive.server2.enable.doAs =false;
Hive.meatstroe.saslenabled=false;
Hive.server2.authentication=none
六、关于电脑配置
电脑配置低了带不动啊!12GB内存都快用满了。
电脑配置如下都还可以,但是至少比下图中的要高才行。

- 使用CentOs7(VirtualBox)搭建集群安装程序(jdk、hadoop、mysql、hive、hbase)
- Hadoop 2.6.0-cdh5.4.0集群环境搭建和Apache-Hive、Sqoop的安装
- CentOS 7使用本地仓库安装ambari 2.4,搭建hadoop集群环境(一)
- hadoop集群搭建之hive安装
- 搭建3个节点的hadoop集群(完全分布式部署)--2安装mysql及hive
- Hadoop集群搭建---step4(Hive、Flume、Azkaban、Sqoop的安装以及环境搭建)
- hadoop集群安装以及Hive、sqoop的使用
- Hadoop集群搭建与MySQL搭建和Hive安装
- Hadoop 2.6.0-cdh5.4.0集群环境搭建和Apache-Hive、Sqoop的安装
- CenOS7 Hadoop集群搭建(四):Hive安装
- Hadoop平台搭建使用系列教程(4)-操作系统安装
- 集群环境下Hadoop2.5.2+Zookeeper3.4.6+Hbase0.98+Hive1.0.0安装目录总汇
- Hadoop集群安装&Hbase实验环境搭建【1】
- 使用expect命令实现远程管理集群和一键安装Hadoop集群
- 【hadoop 2.6】hadoop 2.6集群环境搭建及文件系统使用
- Windows上运行Eclipse使用virtualbox搭建的Ubuntu的hadoop集群服务
- Hadoop平台搭建使用系列教程(2)-预定义集群环境
- 图文讲解基于centos虚拟机的Hadoop集群安装,并且使用Mahout实现贝叶斯分类实例 (1)
- CentOS6.5下使用Ambari安装Hadoop集群
- Hive使用一段时间后Hadoop集群占用空间暴增的原因