图解大数据 | 分布式平台Hadoop与Map-reduce详解

作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-detail/168 声明:版权所有,转载请联系平台与作者并注明出处
1.Hadoop快速入门
1)Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中;
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce;
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力;
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、微软、字节跳动、美团点评、淘宝等,都支持Hadoop。
关于 Hadoop的搭建与应用案例 欢迎大家关注ShowMeAI下列文章:
2)Hadoop发展简史
Hadoop现在已经广泛地应用在大数据任务中,而它最初其实只是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。下面是它的发展历程。

Hadoop源自始于2002年的Apache Nutch项目——一个开源的网络搜索引擎,也是Lucene的一部分。
2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身。
2004年,谷歌公司又发表了另一篇具有深远影响的论文,阐述了MapReduce分布式编程思想。
2005年,Nutch开源实现了谷歌的MapReduce。
2006年2月,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎。
2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用。
2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒。
2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。
Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准。
2.Hadoop特性与应用现状
1)Hadoop特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的。它具有以下几个方面的特性:

2)Hadoop应用现状
Hadoop凭借其突出的优势,已经在各个领域得到了广泛的应用,而互联网领域是其应用的主阵地。

雅虎2007年在Sunnyvale总部建立了M45——一个包含了4000个处理器和1.5PB容量的Hadoop集群系统。
Facebook作为全球知名的社交网站,Hadoop是非常理想的选择,Facebook主要将Hadoop平台用于日志处理、推荐系统和数据仓库等方面。
国内主流的互联网及信息公司,包括百度、淘宝、网易、字节、美团点评、华为、中国移动等都采用了Hadoop。
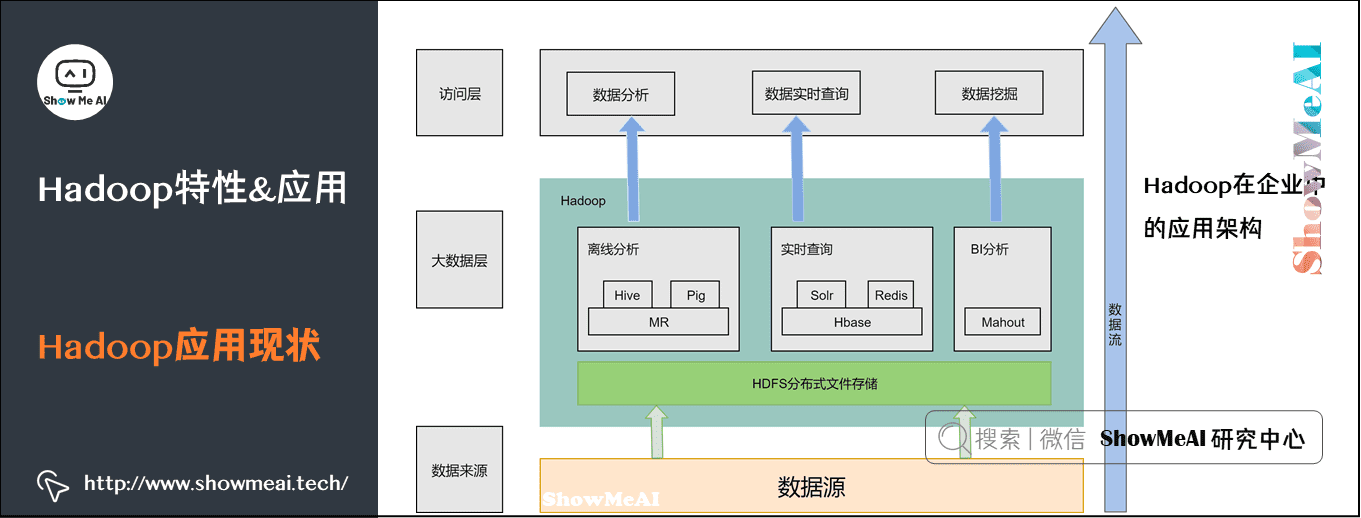
3)Hadoop版本演进
Apache Hadoop版本分为两代:第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。
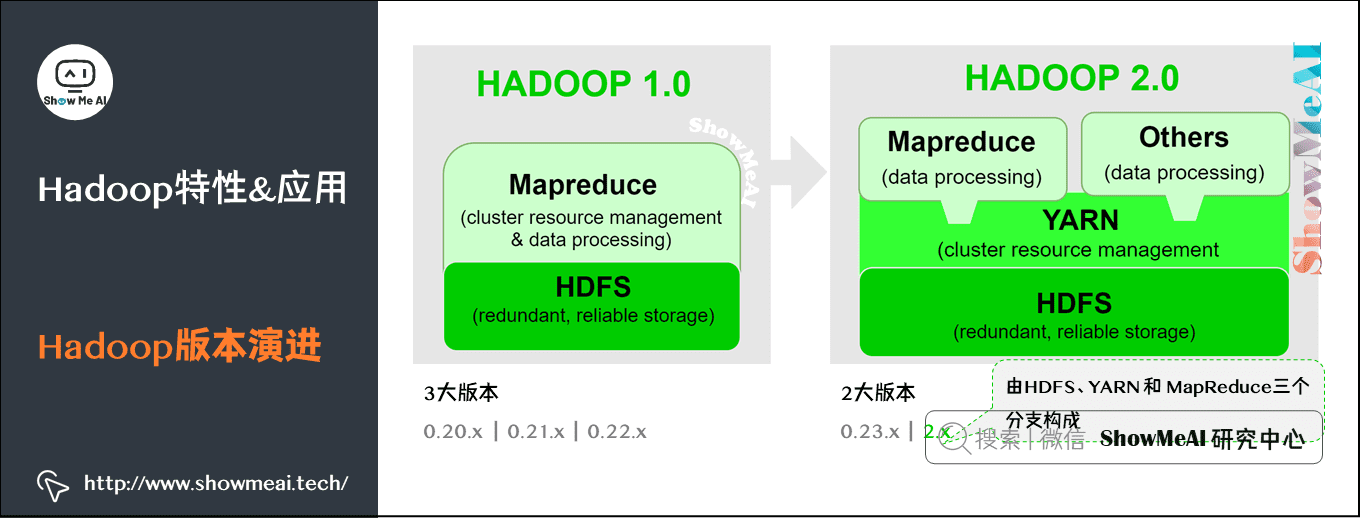
第一代Hadoop包含三个大版本,分别是0.20.x、0.21.x、0.22.x。
- 0.20.x最后演化成1.0.x,变成了稳定版。
- 0.21.x和0.22.x则增加了NameNode HA等新的重大特性。
第二代Hadoop包含两个大版本,分别是0.23.x、2.x。
- 它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统。
- 相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。
3.Hadoop生态项目架构

如上图罗列了Hadoop生态的项目架构,包含以下组件,层级结构与核心功能见图。
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
4.HDFS介绍
1)分布式文件系统
分布式文件系统,把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。与之前使用多个处理器和专用高级硬件的并行化处理装置不同的是,目前的分布式文件系统所采用的计算机集群,都是由普通硬件构成的,这就大大降低了硬件上的开销。

2)HDFS的优点与局限
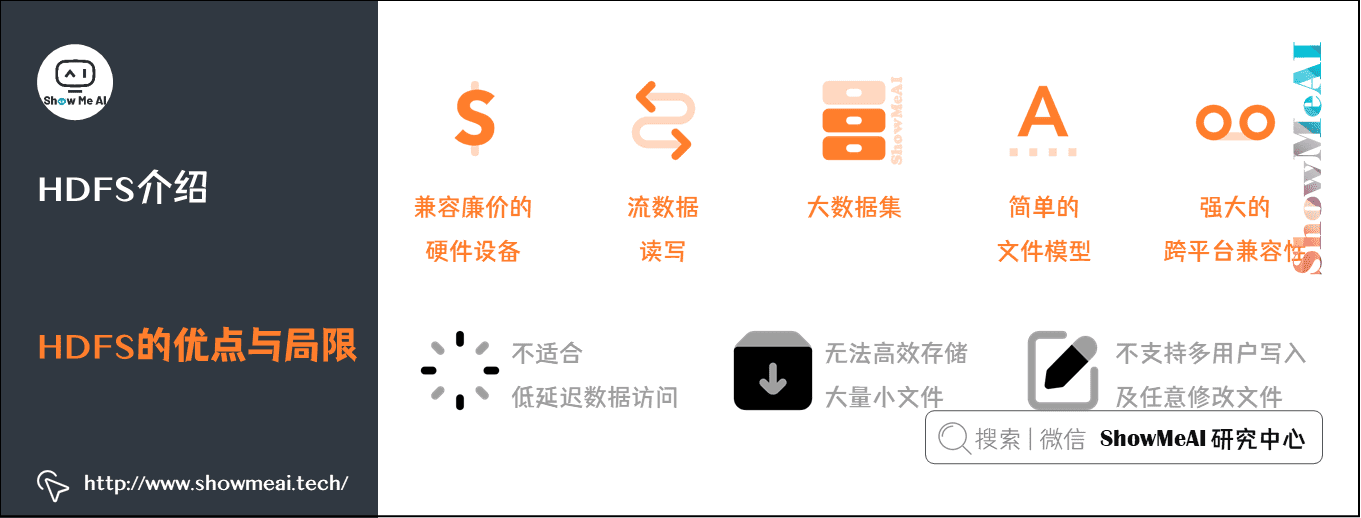
总体而言,HDFS要实现以下目标:
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
HDFS特殊的设计,在实现上述优良特性的同时,也使得自身具有一些应用局限性,主要包括以下几个方面:
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
3)HDFS块及其优势
块(Block):HDFS默认一个块64MB,一个文件被分成多个块,以块作为存储单位。块的大小远远大于普通文件系统,可以最小化寻址开销。
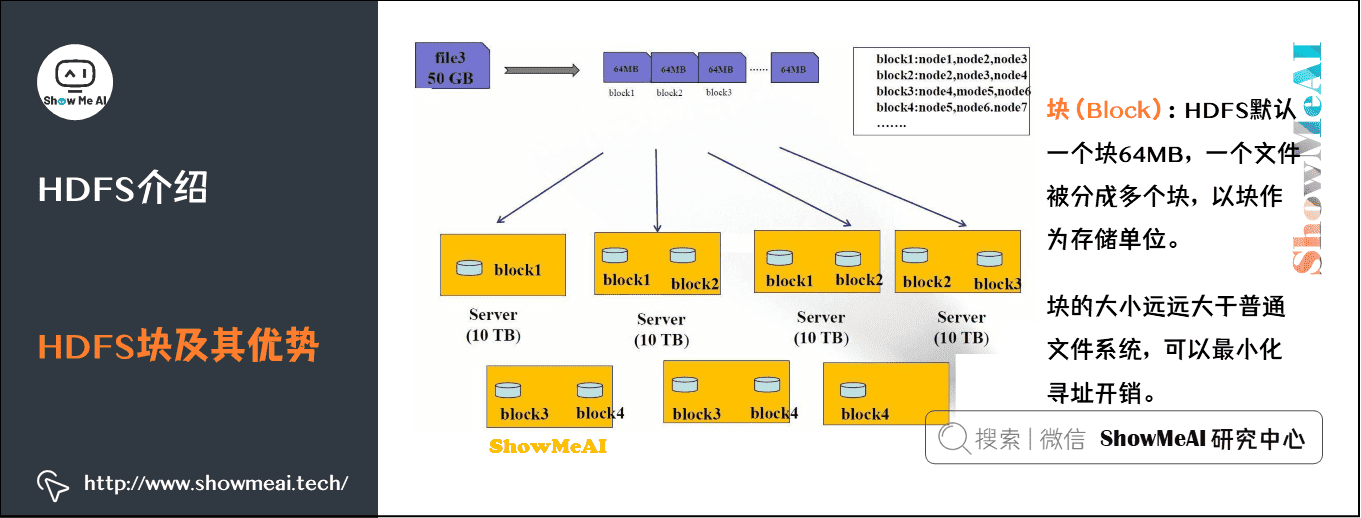
HDFS采用抽象的块概念可以带来以下几个明显的好处:

- 支持大规模文件存储:文件以块为单位进行存储,一个大规模文件可以被分拆成若干个文件块,不同的文件块可以被分发到不同的节点上,因此,一个文件的大小不会受到单个节点的存储容量的限制,可以远远大于网络中任意节点的存储容量。
- 简化系统设计:首先,大大简化了存储管理,因为文件块大小是固定的,这样就可以很容易计算出一个节点可以存储多少文件块;其次,方便了元数据的管理,元数据不需要和文件块一起存储,可以由其他系统负责管理元数据。
- 适合数据备份:每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性。
4)HDFS主要组件的功能
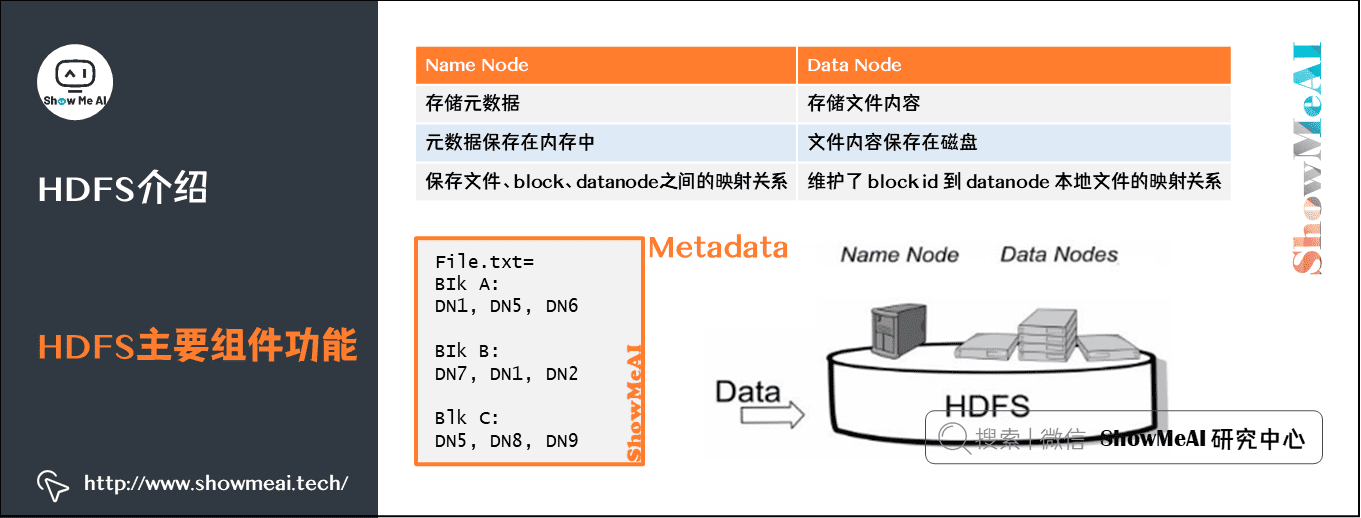
HDFS包含Name Node和Data Node,具体的功能和特点对比如上图所示。
| Name Node | Data Node |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘 |
| 保存文件、block、datanode之间的映射关系 | 维护了 block id 到 datanode 本地文件的映射关系 |
5.Map-Reduce分布式数据处理
HDFS很好地解决了分布式文件存储的问题,而hadoop利用一套Map-Reduce的计算框架,也解决了大数据处理的难题。下面整理了大数据计算所面对的问题,以及一些解决思路(也是map-reduce的核心思想)。
我们后面的内容会以实操的方式,带大家一起看hadoop的组件与Map-Reduce应用的案例,这里大家先做一个简单了解,具体的应用实操接着看ShowMeAI后续内容哦~
集群计算面对的问题&方案

问题1:节点故障。如何保持数据的持续性,即在某些节点故障的情形下不影响依旧能够使用数据?在运行时间较长的集群运算中,如何应对节点故障呢?
解决方法:在多节点上冗余地存储数据。分布式文件存储系统提供全局的文件命名空间,冗余度和可获取性。例如:Google的GFS、Hadoop的HDFS。

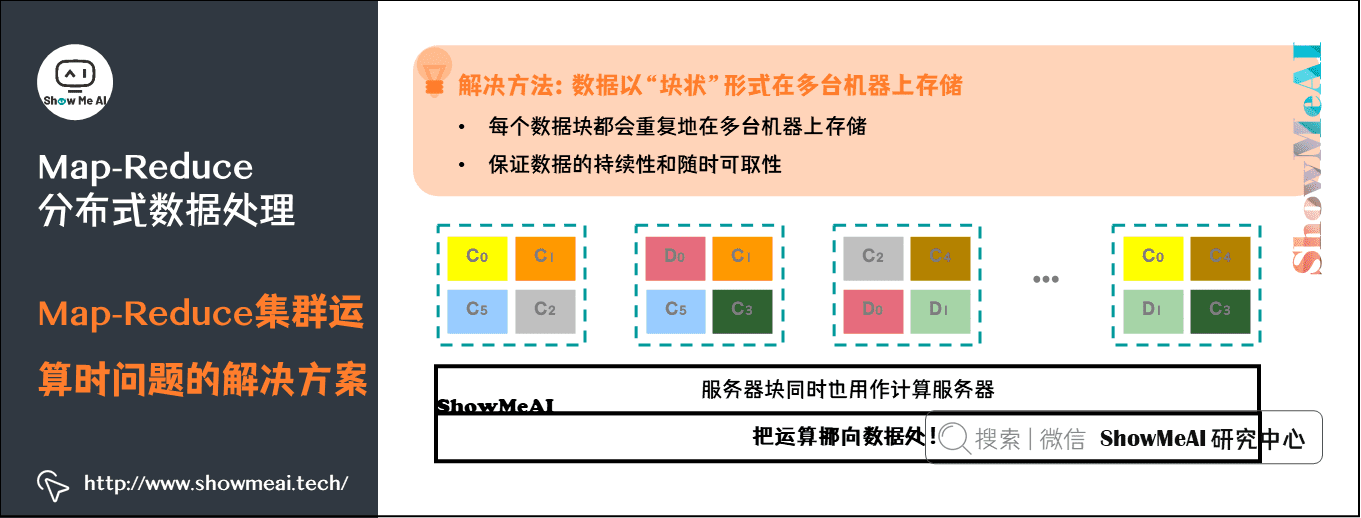
问题2:网络带宽瓶颈。
解决方法:数据以“块状”形式在多台机器上存储。每个数据块都会重复地在多台机器上存储,保证数据的持续性和随时可取性。
问题3:分布式编程非常复杂。需要一个简单的模型能够隐去所有的复杂性。
解决方法:简单的程序模型隐藏所有的复杂度。

6.参考资料
- [美] 汤姆,怀特(Tom White),《Hadoop权威指南:大数据的存储与分析(第4版)》,清华大学出版社,2017
- [美] Donald Miner,Adam Shook 著,《MapReduce设计模式》,人民邮电出版社,2014
- Hadoop集群搭建教程(详细): https://blog.csdn.net/fanxin_i/article/details/80425461
- 总结:详细讲解MapReduce过程(整理补充): https://www.geek-share.com/detail/2713010316.html
ShowMeAI相关文章推荐
- 图解大数据 | 导论:大数据生态与应用
- 图解大数据 | 分布式平台:Hadoop与Map-reduce详解
- 图解大数据 | 实操案例:应用map-reduce进行大数据统计
- 图解大数据 | 实操案例:Hive搭建与应用案例
- 图解大数据 | 海量数据库与查询:Hive与HBase详解
- 图解大数据 | 大数据分析挖掘框架:Spark初步
- 图解大数据 | Spark操作:基于RDD的大数据处理分析
- 图解大数据 | Spark操作:基于Dataframe与SQL的大数据处理分析
- 图解大数据 | 综合案例:使用spark分析美国新冠肺炎疫情数据
- 图解大数据 | 综合案例:使用Spark分析挖掘零售交易数据
- 图解大数据 | 综合案例:使用Spark分析挖掘音乐专辑数据
- 图解大数据 | 流式数据处理:Spark Streaming
- 图解大数据 | Spark机器学习(上)-工作流与特征工程
- 图解大数据 | Spark机器学习(下)-建模与超参调优
- 图解大数据 | Spark GraphFrames:基于图的数据分析挖掘
ShowMeAI系列教程推荐


- Hadoop1.x: 详解Shuffle过程---map和reduce数据交互的关键
- 完全分布式或者伪分布式的hadoop中map和reduce的System.out与System.err的输出去哪儿啦?
- 【hadoop】Hadoop学习笔记(二):从map到reduce的数据流
- Hadoop MapReduce执行过程详解及MR中job参数及设置map和reduce的个数(带hadoop例子)
- 程序员必备大数据技能之分布式云平台Hadoop
- HadoopMapReduce --Map-Reduce具体实现详解
- hadoop学习(四)Map/Reduce数据分析简述-示例-电话通讯清单
- hadoop学习之:Map、Reduce详解
- hadoop学习(Map、Reduce、日志分析和数据挖掘、大数据处理)
- Hadoop完全分布式搭建过程、maven和eclipse配置hadoop开发环境、配置Map/Reduce Locations、简单wordcount测试!
- Hadoop大数据批处理 -Map/Reduce
- Hadoop学习笔记(二):从map到reduce的数据流
- hadoop之数据分片(split)详解以及map数量控制
- 分布式处理与大数据平台(RabbitMQ&Celery&Hadoop&Spark&Storm&Elasticsearch)
- MapReduce:详解Shuffle过程---map和reduce数据交互的关键
- Hadoop分布式平台的大数据的视频下载
- 【hadoop2.2(yarn)】基于yarn成功执行分布式map-reduce,记录问题解决过程。
- 大数据平台 Hadoop 的分布式集群环境搭建
- 基于Greenplum Hadoop分布式平台的大数据解决方案及商业应用案例剖析视频教程
- 基于Greenplum Hadoop分布式平台的大数据解决方案及商业应用案例剖析