Hadoop平台搭建使用系列教程(2)-预定义集群环境
2013-06-04 10:51
781 查看
雪影工作室版权所有,转载请注明【http://blog.csdn.net/lina791211】
采用4台安装Linux环境的机器来构建一个小规模的分布式集群。
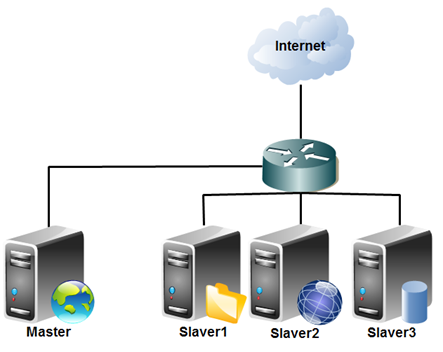
【本图来源:虾皮工作室】
Tips: * 代表序号,例如1,2,3,4…..
a、Master节点的机器名称、个数、IP分配。
b、Slave节点个数、 ip分配、机器名称。
(1)四个节点上均是ubuntu-12.04.1-desktop-i386系统,并且有一个相同的用户hadoop。
(2)Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;
(3)3个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行;
(4)其实应该还应该有1个Master机器,用来作为备用,以防止Master服务器宕机,还有一个备用马上启用。后续经验积累一定阶段后补上一台备用Master机器。
文章下载
1、物理分布图
采用4台安装Linux环境的机器来构建一个小规模的分布式集群。【本图来源:虾皮工作室】
2、集群机器详细信息
2.1 Master服务器
Master服务器详细信息
| 名称 | 详细信息 |
| 机器名称 | namenode |
| 机器IP地址 | 10.196.80.90 |
| 最高用户名称(Name) | root |
| 最用用户密码(PWD) | hadoop(全小写) |
| 一般用户名称(Name) | hadoop(全小写) |
| 一般用户密码(PWD) | hadoop(全小写) |
2.2 Slave*服务器
Tips: * 代表序号,例如1,2,3,4…..Slave*服务器详细信息
| 名称 | 详细信息 |
| 机器名称 | datanode* |
| 机器IP地址 | 10.196.80.9* |
| 最高用户名称(Name) | root |
| 最用用户密码(PWD) | hadoop(全小写) |
| 一般用户名称(Name) | hadoop(全小写) |
| 一般用户密码(PWD) | hadoop(全小写) |
2.3 总结
a、Master节点的机器名称、个数、IP分配。b、Slave节点个数、 ip分配、机器名称。
机器、节点、IP映射表
| 机器名称 | 节点作用 | IP地址 |
| namenode | Namenode & jobtracker | 10.196.80.90 |
| | | |
| datanode1 | datanode1 & Tasktracker | 10.196.80.91 |
| datanode2 | datanode2 & Tasktracker | 10.196.80.92 |
| datanode3 | datanode3 & Tasktracker | 10.196.80.93 |
| | | |
| | | |
(2)Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;
(3)3个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行;
(4)其实应该还应该有1个Master机器,用来作为备用,以防止Master服务器宕机,还有一个备用马上启用。后续经验积累一定阶段后补上一台备用Master机器。
3、文章PDF下载
| 网站 | 地址 |
|---|---|
| 百度云 | http://pan.baidu.com/share/link?shareid=529700&uk=4010661479 |
| CSDN | http://download.csdn.net/detail/lina791211/5514087 |

相关文章推荐
- Hadoop平台搭建使用系列教程(2)-预定义集群环境
- Hadoop平台搭建使用系列教程(3)-预定义软件下载
- Hadoop平台搭建使用系列教程(3)-预定义软件下载
- Hadoop平台搭建使用系列教程(5)- 网络以及初始统一环境配置
- Hadoop平台搭建使用系列教程(5)- 网络以及初始统一环境配置
- Hadoop平台搭建使用系列教程(4)-操作系统安装
- Hadoop平台搭建使用系列教程(7)- SSH无密码验证
- Hadoop平台搭建使用系列教程(7)- SSH无密码验证
- Hadoop平台搭建使用系列教程(终)- 致歉与全部发布
- Hadoop平台搭建使用系列教程(6)- JDK的安装
- Hadoop平台搭建使用系列教程(1)-资源目录
- Hadoop平台搭建使用系列教程(7)- SSH无密码验证
- Hadoop平台搭建使用系列教程(终)- 致歉与全部发布
- Hadoop平台搭建使用系列教程(1)-资源目录
- Hadoop平台搭建使用系列教程(6)- JDK的安装
- Hadoop平台搭建使用系列教程(4)-操作系统安装
- 电商用户行为分析大数据平台相关系列2-HADOOP环境搭建
- 大数据平台 Hadoop 的分布式集群环境搭建
- Windows 7平台利用Vmware Workstation 11虚拟机搭建Hadoop 2.7.4基于Ubuntu kylin 14.04集群环境
- hadoop系列教程第二讲:环境搭建