数据分析之pandas(三)-数据合并篇

前言

数据分析和建模都是基于数据准备工作的,数据规整化包括加载、清理、转换以及重塑,本篇推文主要讲通过pandas库对数据格式进行专门处理。如果你是小白,对pandas库的基础知识还不够了解,则需要先阅读下面两篇推送:
今日推荐歌曲,pink的try,希望在困境中的大家都能不断尝试。尽管遇到一些糟心的人,没事,森林中毕竟还有一群没有变成人的猴子
TryP!NK - The Truth About Love (Fan Edition)

首先,导入相关的库:import pandas as pd
1
合并数据集(merge)
pandas对象中的数据可以通过一些内置的方式进行合并,例如函数pandas.merge可以根据一个或多个键将不同DataFrame中的行连接起来。
先从一个实例了解一下merge函数:


利用DataFrame创建两个表格,然后利用merge函数将两个表格合并一下:

通过观察,发现只有两个表格重叠列的部分被合并,而表格dfL中的键为D和dfR中的键为C的那一行消失了。这是因为默认情况下,merge做的是inner连接,合并后的键是之前表格的键的交集。
根据官方文档中merge的参数设置如下:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)其中各个参数的介绍如下:
left 参与合并的左侧DataFrame
right 参与合并的右侧DataFrame
how 包括inner、outer、left、right,默认为inner
on 用于连接的列名
sort 根据连接键对合并后的数据进行排列,默认为True
suffixes 字符串值元组,用于追加到重叠列名的末尾
left_on (right_on) 左侧(右侧)DataFrame中用作连接键的列
left_index (right_index ) 将左侧(右侧)的行索引用作其连接键
copy 设置为False,可以在某些特殊情况下避免将数据复制到结果数据结构中。默认总是复制。
看到这块,各位读者肯定只是对merge函数有个概念性的认识,对参数的使用也不是很清楚,下面将更加详细的介绍。
1
how 指的是合并连接方式,包括inner、outer、left、right,默认为inner,因为上面的例子可以看出默认情况下,inner连接求取的是键的交集,那么显然outer是键的并集。

dfL里有2个A,2个B,1个D,dfR里有1个A,2个B,1个C,从上图可以清楚理解采用outer连接方式的原理。

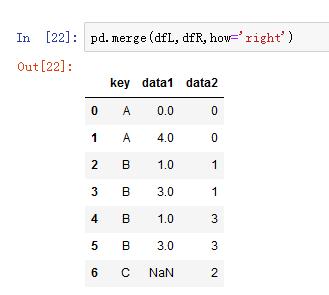
而left和right分别是左连接和右连接,不要简单的以为这两种方式是按某一边的键合并。因为涉及到多对多的合并,所以连接产生的是行的笛卡尔积,例如左边dfL里有2个A,2个B,1个D,而右边dfR里有1个A,2个B,1个C,所以按右连接的话最终的结果是2个A,4个B,1个C。
2
left 和right分别是参与合并的左侧DataFrame和右侧DataFrame,on 是用于连接的列名,上面的例子都没有指明要用哪个列进行连接,但是最好要用on显示指定一下。

要根据多个键进行合并,传入一个由列名组成的列表即可。因为有重复列名data1的存在,merge函数默认给它们加上了后缀_x和_y。但是,merge有一个更实用的选项suffixes,用于指定附加到重复列名上的后缀字符串,下一节会介绍到。
3
suffixes是字符串值元组,用于追加到重叠列名的末尾,默认为(‘_x’和‘_y’),我们也可以自行设置,例如将字符串设置为(‘_left’,‘_right’):

4
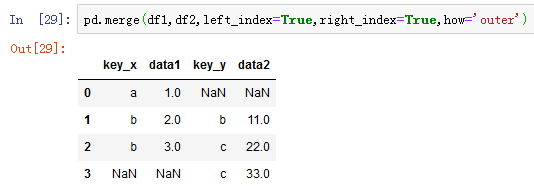
on 是用于连接的列名,必须存在于左右两个DataFrame对象中,left_on和right_on分别指左侧和右侧DataFrame中用作连接键的列。当DataFrame中的连接键位于其索引中,可以传入left_index=True或right_index=True(或两个都传)。

可以看到,这里right表格的索引正好是left表格的某一列的值,通过参数left_index=True或right_index=True来连接。

这里用到的left_on参数是指用左侧DataFrame中连接键的列,读者需要注意。
还有一种dataframe内置的join方法可以快速合并,它默认以index作为对齐的列,后面会详细介绍。
2
合并数据集(join)
join可以更为方便地按索引合并,它可以用于合并多个带有相同或相似索引的DataFrame对象。例如接着上面的例子:

和merge函数类似,join的参数设置如下:
join(self,other,on=None,how='left',lsuffix=' ',rsuffix=' ',sort=False):
其中参数的意义与merge方法基本相同,只是join方法默认为左外连接how='left',通过lsuffix=' ', rsuffix=' ' 区分相同列名的列。
3
合并数据集(concat)
通过concat可以实现轴向连接,即沿着一条轴将多个对象堆叠到一起。
concat的参数设置如下:
concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False)
objs 需要拼接的pandas对象的列表或字典,唯一必须的参数
axis 指明连接的轴向,默认为0
join 有inner和outer两种,默认为outer
其他参数不常用,暂时先不介绍。
1
在默认情况下,axis=0 为纵向拼接,axis=1时为横向拼接。举例如下:
先创建两个表格:

当axis=1时,横向拼接,此时pd.concat([df1,df2],axis=1)类似于pd.merge(df1,df2,left_index=True,right_index=True,how='outer')

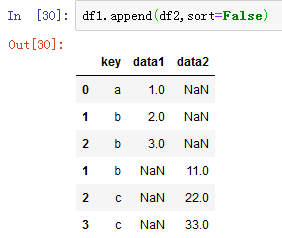
默认情况下,当axis=0,纵向拼接,此时pd.concat([df1,df2])类似于df1.append(df2)

上面例子中表格的索引没有实际意义,可以采用ignore_index参数,使合并的两个表根据字段对齐合并,重新整理一个索引。
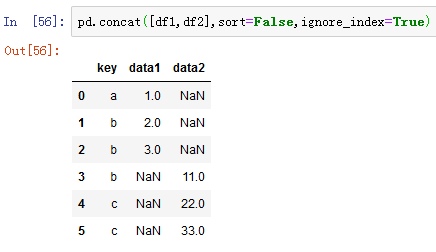
2
join参数的设置有inner(两表交集)和outer(两表并集)两种,默认为outer。当将join设置为inner,则取得是两个表格索引的交集:

可以通过join_axes设置要在连接轴上使用的索引:
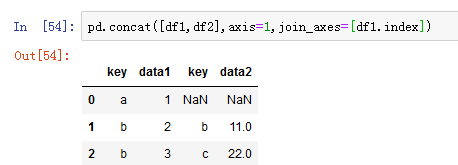
3
拼接之后不知道数据来自哪个表格,可以通过设置keys参数,即在连接轴上增加一个层次化索引。
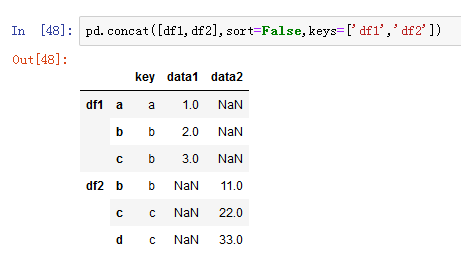
也可以传入字典来增加分组键:

4
总结
pd.merge( )方法是数据库风格的合并;pd.concat( )方法是轴向拼接,即沿着一条轴将多个对象堆叠到一起;join主要用于索引上的合并。具体采用什么方法,需要读者在实践中总结归纳。
大家可以去官方文档网址查阅更多信息:
http://pandas.pydata.org/pandas-docs/stable/merging.html

- 利用 Python 进行数据分析(十二)pandas:数据合并
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)...
- 利用Python进行数据分析(12) pandas基础: 数据合并
- 利用 Python 进行数据分析(十二)pandas:数据合并
- python/pandas数据分析(十三)-数据清理、转换、合并,重塑
- 利用Python进行数据分析(12) pandas基础: 数据合并
- 利用Python进行数据分析——第二章 引言(2):利用pandas对babynames数据集进行简单处理
- Pandas数据分析⑤——数据分组与函数使用(Groupby/Agg/Apply/mean/sum/count)
- 数据分析处理库Pandas-数据预处理
- 数据分析之Pandas-01Series和DataFrame
- Python数据分析模块 | pandas做数据分析(三):统计相关函数
- python基于pandas数据分析实例——FIFA球员数据简单分析
- python数据分析初探小结(matplotlib,Numpy,Pandas)简单分析下IMDB250电影情况
- 数据分析之Pandas(一):Series、DataFrame基本操作及索引对象
- 数据分析之Pandas(一) 学习资料汇总
- Python数据分析入门(一)-Pandas数据结构(Series)
- pandas (七)数据合并
- Python 数据分析-pandas 基础
- Python操作Mysql数据库入门——数据导入pandas(数据分析准备)
- Python数据分析Pandas库方法简介(一)