【ReID论文阅读(二)】(2019CVPR)Bag of Tricks and a Strong Baseline for Deep Person
前言
第二篇:行人reid的tricks和一个strong baseline。
这才正式进入到了reid的学习。
(不对的地方请大佬指导啊!!!)
摘要
这篇文章旨在探索一个简单高效的baseline。最近很多的文章都达到了很好的效果,但是在论文或者源码中,都很少提到训练技巧。作者收集和验证了这些高效的训练技巧,并整合到了一起,所提模型仅仅利用global特征就达到了94.5% rank-1和85.9%map的效果,再Market1501。
(开源了代码,可以好好看一下了!
https://github.com/michuanhaohao/reid-strong-baseline)
介绍
作者比较了cvpr2018和eccv2018的所有方法在market1501和dukemtmc-reid数据集上,效果如下两图。

另外,作者发现很多研究是不公平的,因为一些提升主要靠的是训练tricks而不是方法的本身,并且读者很容易忽视这些技巧,所以他提议审稿人要多关注文章中这些技巧。
除了以上的原因,另一个考虑因素是,在工程上更加偏向于简单高效的模型热不是结合很多的local特征在推理阶段。很多高精度的工作结合了local特征或者是姿态估计的语义信息或者是实例分割模型,这些方法无疑带来了大量额外的计算,检索推理速度也随之下降。因此,作者考虑只用global特征和一些技巧达到好的表现(精度和速度)。
(不得不承认,这个作者很会写论文!要学习一下)
接下来,作者提了四点,此文研究的必要性之类的东西:
1.研究发现,很多方法有好的表现,但是它们的baseline效果都很差。
2.为了学术界,我们希望有一个strong baseline。
3.为了这个领域,我们希望提醒审稿人或者读者,一些tricks非常影响reid模型的表现。
4.为了工程界,我们希望提供一些高效的tricks去得到更高的表现(没有太多的额外计算量)。
具体的作者挑选了6个tricks,总结本文的工作,主要体现在3个方面:
1.设计了一个新的neck structure称作BNNeck。
2.用ResNet50作为backbone。
3.评估了图片输入大小和batch size对reid模型的影响。
2.基准baseline
ResNet50作为backbone,在训练阶段,主要包括一下几点:
1.使用imagenet预训练参数作为初始化,改变对应的全连接层输出维度。
2.取P个id,每个id有K个图片,所以一个batch,B=P×\times×K,这篇文章里,P=16,K=4。
3.每个图片输入,首先resize成256×128256\times128256×128。然后添零10个像素,再随机裁剪成256×128256\times128256×128。
4.水平随机翻转概率0.5。
5.图像像素转为32浮点数,然后归一化到[0,1],减0.485,0.456,0.406,再除以0.229,0.224,0.225。
6.模型输出reid feature(f)和id预测(p)。
7.f用triplet loss计算,p用cross entropy
loss计算,triplet loss边缘m参数设置为0.3。
8.Adam优化器,lr设置为0.00035,并且学习率衰减设置为0.1,40和70epoch执行衰减,共训练120epochs。
3.训练技巧
训练总体流程与技巧

3.1 warmup 学习率
这个比较常用,就不详细介绍了。作者也给了图,就是前几个epoch学习率从小到大,达到最大设定学习率,再执行衰减策略。

3.2 随机消除数据增强

这个也是防止过拟合的一个常用手断了。
3.3 标签平滑
在最后的输出,也就是id loss使用标签平滑。也是为了防止过拟合,防止模型过于依赖训练的ID。
3.4 最后的步长(last stride)
空间分辨率越高,就越能提高特征图的粒度。于是作者把最后一个降采样步长调整为1。比如原来的特征图大小是8×48\times48×4降采样步长为2,步长变为1以后,特征图大小就成了16×816\times816×8。这个方法只增加了一点点计算,并且没有增加需要训练的参数。高分辨率的特征图会带来更好的效果。
3.5 BNNeck
重点来了,我觉得这是这篇最创新的一点结构!!
大多数的研究只是结合了id loss和triplet loss。用这两个loss限制同一个特征图,然而,这两个loss的目的在空间上是不一致的(或者说矛盾)。
像下图所示,id loss创建几个超平面去把embedding space(embedding将大型稀疏向量转换为保留语义关系的低维空间)分割成不同的子空间。每个类别的特征在不同的子空间被区分。在这种情况下,cosine dis比Euclidean dis更加合适。

另一方面,triplet loss提升类内紧密度和类间分离程度,在Euclidean空间。由于triplet loss没有全局优化的限制,所以有时类间间距比类内间距还要小一点。
一种广泛使用的方法是结合两种loss一起训练模型,这个过程让模型学习到更多的区分特征。
然鹅,对于embedding space中的图像对来说,id loss主要作用于cosine dis,triplet loss主要作用于Euclidean dis。如果我们使用两个loss同时作用于同一个特征向量,它们的目标可能是相互矛盾的。在训练过程中可能出现的一种情况就是,一个loss在降,另一个在震荡甚至增加。
为了克服这个问题!作者提出了BNNeck结构。
就是在特征图后全连接层前加入一个BN层,BN前的特征图叫ft,后的叫fi。我们让ft穿过BN层得到归一化的特征fi。在训练阶段,ft和fi分别的被用于计算triplet loss和id loss。归一化平衡了fi的每一个维度。fi特征按照高斯分布靠近在一个超球面的表面。这种分布使得id loss更容易聚集。另外,BNNeck减少了ft对id loss的限制。这种更少的限制同样也使得triplet loss更容易聚集。第三点,归一化使属于同一个人的特征更加紧凑。
因为超球面几乎是关于原点对称的,所以另一个技巧是把FC层的bias去掉,这样限制了分类的超平面通过坐标系原点。(FC层用kaiming初始化权重法)

在推理阶段,我们选择fi去做reid任务。Cosine dis比Euclidean dis达到更好的效果。实验证明在表1,BNNeck能大幅度提升reid模型的表现能力。
3.6 center loss
这里他先提到了triplet loss的两个缺点,首先是不能保证图像对距离比较小,它是由两个id的样本随机决定的,并且也很难保证所有数据集中positive对距离总是小于negative对。
center loss一方面学习了每一类深度特征的中心,另一方面惩罚了深度特征和类中心的距离,弥补了triplet loss的不足。(这里稍微有点一知半解,随着读更多的论文,再慢慢研究吧)

上面是公式。yj是batch中第j张图片,cyj是第yj类的深度特征的中心。B是batch size,这个公式高效的描述了类内的变化,最小化center loss增加了类内的紧凑程度。最终loss包含三部分。(Lid、Ltriplet、bLc(b设为了0.0005))
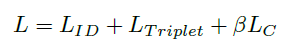
4.实验结果
4.1 每个trick的影响(同一领域)
直接上图表。

4.2 BNNeck的分析
这一部分,我们评估了ft、fi两个不同的特征分别用E距离和C距离的表现。所有模型都没用center loss,我们观察到对于ft特征来说,C距离表现要比E距离好。

因为id loss直接约束了BN层的特征,所以fi能被用很少的几个超平面清楚的分割开。C距离可以测量两个向量的角度,所以C距离对于fi来说更加合适。
然鹅,ft是被id loss和triplet loss共同约束的,所以两种距离达到了相似的效果。整体看来,BNNeck显著的提升了reid模型的表现,在推理阶段,我们使用C距离去做检索。
4.3 每个技巧的跨领域影响

同样,直接上表,M-D表示M数据集训练的模型用D评估,反之同理。
4.4 和SOTA模型比较

直接上表。
5.补充实验
作者补充了batch size和input size对实验结果的影响。
bs:没有非常清晰的结论,只是有一点微小的趋势,大的bs表现好一点,我们推断是:大的K帮助减少困难的positive样本对,大的P帮助减少困难的negative对。

input:同样,没有大的变化,基本表现一致。


- 【论文阅读】行人重识别算法优化技巧:Bags of Tricks and A Strong Baseline for Deep Person Re-identification
- 1607.CVPR-Joint Learning of Single-image and Cross-image Representations for Person ReID 论文笔记
- 【ReID论文阅读(三)】(2019CVPR)Masked Graph Attention Network for Person Re-Identification
- PifPaf: Composite Fields for Human Pose Estimation - CVPR 2019 论文解读- (Based on: G-RMI and PersonLab)
- 论文阅读:Joint Learning of Single-image and Cross-image Representations for Person Re-identification
- MSCAN:Learning Deep Context-aware Features over Body and Latent Parts for Person ReID阅读笔记
- 【论文阅读】Bag of Tricks for Image Classification with Convolutional Neural Networks
- CVPR 论文阅读与翻译2:图像检索、哈希编码学习、深度哈希:Deep Learning of Binary Hash Codes for Fast Image Retrieval-2015
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H
- 论文阅读(Zhuoyao Zhong——【aixiv2016】DeepText A Unified Framework for Text Proposal Generation and Text Detection in Natural Images)
- 论文阅读理解 - Deep Learning of Binary Hash Codes for Fast Image Retrieval
- 论文阅读《Joint Learning of Single-image Cross-image Representations for Person Re-identification》
- 论文解读: | (CVPR2019)《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels》
- 【论文阅读笔记】CVPR2015-Long-term Recurrent Convolutional Networks for Visual Recognition and Description
- CVPR2012文章阅读(1)-What AreWe Looking For: Towards Statistical Modeling of Saccadic Eye Movements and Visual Saliency
- [论文阅读]Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks
- 1604.Joint Detection and Identification Feature Learning for Person Search论文阅读笔记
- 论文阅读:CVPR 2015 FaceNet: A Unified Embedding for Face Recognition and Clustering
- 【医学+深度论文:F11】2018 A deep learning model for the detection of both advanced and early glaucoma using
- 1703.In Defense of the Triplet Loss for Person Re-Identification 论文阅读笔记