论文阅读《Joint Learning of Single-image Cross-image Representations for Person Re-identification》
2017-04-15 10:46
781 查看
简介
person re-identification是一个越来越热门的研究领域,其研究的问题是辨别从两个摄像头中捕获到的两张行人图片是否是同一个目标对象的。个人理解,reid问题与人脸识别存在的差异主要在于人脸识别主要通过脸部特征进行识别,而reid问题的两个输入图像则更关注于人的整体,由于监控摄像头的角度等问题,无法给到像人脸一样的正面特写,所以我们只能通过其他的一些特征来进行判断。做reid问题常见的两种思路分别如下:SIR: Single-Image Representation,即对两张图片分别提取一个特征,然后通过l2 距离,cosine相似度等指标计算两个特征之间的距离并与阈值对比以完成reid问题
CIR: Cross-Image Representation,即对两张输入图片提取一个共同的特征,然后用神经网络,SVM等分类器对这个特征进行二分类问题以解决reid问题
本文尝试通过SIR和CIR的融合,来提神模型在reid问题上的精确度。
待解决问题
两种基本的解决思路中,SIR的优势在于效率,当特征提取方法(模型)确定后,我们对gallery中的图片只需要事前提取一次特征,每次拿到probe的图片再对其提取一次特征,然后计算相似度即可。而CIR呢则需要每次拿到一个probe图片都根据probe和gallery中的每张图片计算两张图片的一个共同特征,所以效率上SIR是更加好的。虽然效率上CIR较SIR差,但是CIR更加善于发现两张图片之间的潜在相关关系,所以可以说CIR在准确度上更为出色。本文尝试通过分析SIR和CIR两种方法之间的关系,以融合两种方法,使得新方法在效率(efficiency)以及准确度(effectiveness)上都能得到保证。
解决方法
分析SIR和CIR之间的关系
作者认为SIR是特殊形式的CIR,下面以l2 距离为例。记SCIR(xi,xj)=wTg(xi,xj)−b,SSIR=||f(xi),f(xj)||22。其中g(xi,xj) 为两个输入图像的共同特征,而f(xi) 则为单张图像的特征。当CIR中的w=[I]vec,b=tS,g(xi,xj)=[(f(xi)−f(xj))(f(xi),f(xj))T]vec 的时候,CIR即为SIR。由此可以看出,SIR是CIR的一种特例,而CIR是SIR的一种抽象表达。文章在第三章中介绍了当SIR使用其他几种不同的距离度量时,如何用CIR来表示。设计loss
这里不知道为什么作者前面用了一些篇幅分析SIR和CIR之间的关系,反正最后作者用到的loss函数还是只是将SIR的loss和CIR的loss相加而已,难道前面的分析是为了说明这两个loss可以直接相加?作者用了pairwise和triplet两种方法来跑这个网络,两种方法的loss分别如下:
LPSIR=∑i,j[1+hi,j(||f(xi)−f(xj)||22−bSIR)]+
LPCIR=αP2||w||22+∑i,j[1+hi,j(wTg(xi,xj)−bCIR)]+
LP=LPSIR+ηPLPCIR
其中LPSIR 是SIR的loss,LPCIR 为CIR的loss。hi,j 是指两个输入图像xi 和 xj是否是同一个对象,如果是则为1,不是则为-1。bSIR 和 bCIR 为阈值。
triplet loss的loss function太长了不打了,直接看论文就有,不过也是类似的。
获取输出
输出分为两个部分,第一部分是获取两张输入图片的特征,然后计算l2 距离。其次是直接将两张图片输入CIR的部分,获取CIR网络的输出。然后根据以下公式将两个loss融合,即得到最后这两个输入图片是否是同一对象的score。S(xi,xj)=||f(xi)−f(]mathbbxj)||22+λwTg(xi,xj)
其中λ 在pairwise loss中取0.7,在triplet loss中取1.0。
网络结构
文章使用的网络结构比较简单,只有三个卷积pooling层。在第二个pooling结束后将两张图片的pooling输出逐通道加权求和,以一边卷积一边融合。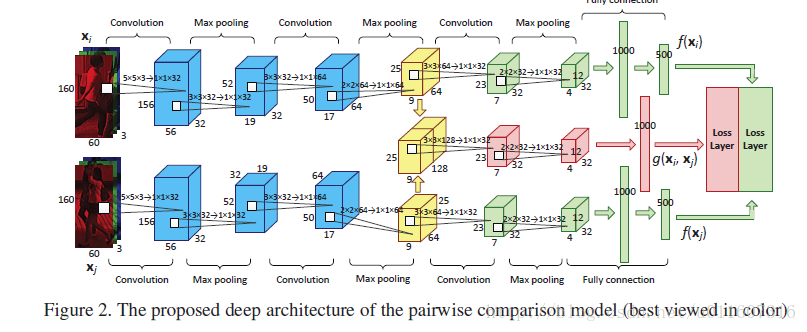
Figure 2. pairwise 网络结构
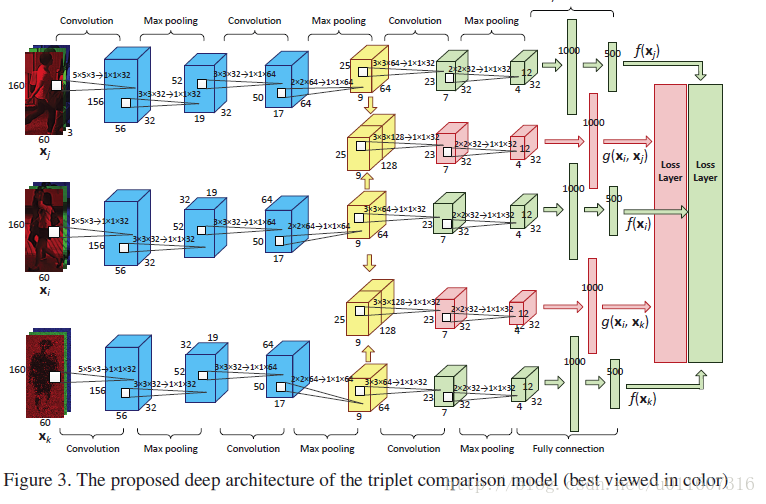
Figure 3. triplet网络结构
在两个网络中,蓝色部分的网络是pretrain的cnn网络用来提取图片特征,pretrain结束后,后面的训练过程不再更新这部分的权重,后面的训练过程都是从黄色的部分开始训练的。绿色的部分是SIR的网络,绿色的部分有多个branch,每个branch的参数是共享的。而红色的部分则是CIR网络。
网络结构很简单,但是看完后仍然有一点小疑惑,就是作者这种将两张图片的feature map加权求和的方法,不会导致说输入的两张图片改变一下顺序后CIR的输出就发生变化了这样的问题吗?以后如果搞懂了为何作者这样设计的话在回来更新。

相关文章推荐
- 论文阅读:Joint Learning of Single-image and Cross-image Representations for Person Re-identification
- Joint Learning of Single-image and Cross-image Representations for Person Re-identification
- [Paper note] Joint Learning of Single-image and Cross-image Representations for Person Re-id.
- 1607.CVPR-Joint Learning of Single-image and Cross-image Representations for Person ReID 论文笔记
- 1505.Deep Ranking for Person Re-identification via Joint Representation Learning论文笔记
- 论文研读--Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identification
- 1604.Joint Detection and Identification Feature Learning for Person Search论文阅读笔记
- 1703.In Defense of the Triplet Loss for Person Re-Identification 论文阅读笔记
- 论文笔记之---Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identificatio
- 1705.Person Re-Identification by Deep Joint Learning of Multi-Loss Classification 论文阅读笔记
- 论文阅读:Multi-Scale Triplet CNN for Person Re-Identification
- 论文阅读理解 - Deep Learning of Binary Hash Codes for Fast Image Retrieval
- 论文笔记(一)Deep Ranking for Person Re-Identification via Joint Representation Learning
- 论文笔记之---Joint Detection and Identification Feature Learning for Person Search
- Deep Ranking for Person Re-identification via Joint Representation Learning
- 1705.Person Re-Identification by Deep Joint Learning of Multi-Loss Classification 论文阅读笔记
- 论文笔记(一)Deep Ranking for Person Re-Identification via Joint Representation Learning (续)
- Query-Adaptive Late Fusion for Image Search and Person Re-identification阅读笔记
- 【论文笔记】In Defense of the Triplet Loss for Person Re-Identification
- 论文阅读:An Enhanced Deep Feature Representation for Person Re-identification