pandas数据分析实例(pandas、matplotlib)
本人喜欢数据分析,接触数据分析也接近两年的时间了,最近在学习pandas。学习最好的方法是使用它,所以,根据这个文章,做了一些练习,并记录下我练习的轨迹。
本篇文章是练习文,输出的观点以及技术比较少。
文章链接:https://mp.weixin.qq.com/s/RcrQmqty1FHEDbQfxv2XTQ
感谢作者!!!
主要是四部分:数据读取,数据概述,数据清洗和整理,分析和可视化
一、数据读取
df = pd.read_csv(r'F:\python学习\DataAnalyst.csv',encoding='gb2312') print(df)
结果如下:

read_csv()函数虽然用起来非常简单,但其实里面包含了很多参数,详细参数可以看这篇
官方文档:https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#io-read-csv-table
二、数据概述
df.info()#数据里字段的格式 df.head()#取数据的前5行 df.tail()#取数据的最后5行
df.info()的结果:
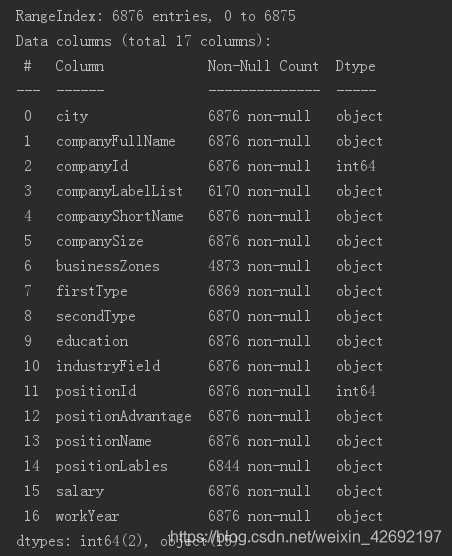
这里可以看到数据集包含的字段,以及字段不为null的记录数,以及字段类型。可以知道,数据集一共有16个字段,6876条数据,其中有部分数据统计中出现null数据。
df.head()的结果:

df.tail()的结果:
这一部分主要是用来查看数据集,了解数据集的概况。
三、数据清洗和整理
1、查重&去重
使用unique()函数筛选不重复的positionId数,len()统计
drop_duplicates(subset=‘x’,keep=‘first’,inplace=False)
参数:
(1)subset:列名,默认为none
(2) keep:有三个值为:first: 保留第一次出现的重复行,删除后面的重复行;
last: 删除重复项,除了最后一次出现;
False: 删除所有重复项
(3) inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。 (inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。)
#1、查重 len(df.positionId.unique())# #结果为5031条不重复的记录数 #2、去重 df_duplicates=df.drop_duplicates(subset='positionId',keep='first')#按照positionId去重,保留第一次出现的重复行
2、取最低工资和最高工资&转换数据类型
在执行下面代码时不会出错,但是会抛出警示:SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame,解决这个警示的方案为:
在代码前加上:df_duplicates=df_duplicates.copy(),也就是对数据框进行复制,后续新增列都是对复制的数据框进行操作。
df_duplicates=df_duplicates.copy()#解决SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame
#3、取最低工资&最高工资:
def cut_word(word,method):
position=word.find('-') #find()函数:寻找某字符串是否在该字符串中出现,如果出现,返回第一次出现的索引,没有的话返回-1
length=len(word)
if position !=-1:
bottomSalary=word[:position-1]
topSalary=word[position+1:length-1]
else:
bottomSalary=word[:word.upper().find('K')]
topSalary=bottomSalary
if method=='bottom':
return bottomSalary
else:
return topSalary
df_duplicates['bottomSalary']=df_duplicates.salary.apply(cut_word,method='bottom')
df_duplicates['topSalary']=df_duplicates.salary.apply(cut_word,method='top')
#数据类型转换:需要通过赋值才能转换成功
df_duplicates['bottomSalary']=df_duplicates['bottomSalary'].astype('int')
df_duplicates['topSalary']=df_duplicates['topSalary'].astype('int')
(1)函数定义def
apply()函数:apply函数中可以来使用自定义的函数(func);对于func中传递的参数,如果axis =0 应用于每一列上, 如果axis=1应用于每一行上
(2)find():寻找某字符串是否在该字符串中出现,如果出现,返回第一次出现的索引,没有的话返回-1
(3)数据类型转换:
astype基本也就是两种用作,数字转化为单纯字符串,单纯数字的字符串转化为数字,含有其他的非数字的字符串是不能通过astype进行转化的。
注:需要通过赋值才能转换成功
3、获取平均薪资
#4、平均薪资 df_duplicates['avgSalary']=df_duplicates.apply(lambda x:(x.bottomSalary+x.topSalary)/2,axis=1)#求平均薪资 df_clean=df_duplicates[['city','companyShortName','companySize','education','positionName','positionLables','workYear','avgSalary']]#获取后续需要进行分析的字段
在Python中,lambda的语法是唯一的。其形式如下:
lambda argument_list: expression
其中,lambda是Python预留的关键字,argument_list和expression由用户自定义。
四、数据可视化
1、城市分布情况
#1、城市分布情况 print(df_clean.city.value_counts())#统计各个城市的数据分布
value_counts():value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。
结果展示:

2、描述统计
#2、描述统计 df_clean.describe()
结果如下:
统计记录数为5031条,平均薪资为17.11K,中位数为15.00K,两者相差不大,最高薪资达到75.00K,最低薪资为1.500K.

3、平均薪资直方图
直方图是为了表明数据分布情况,其中横轴是数据,纵轴是出现的次数(也就是频数)。
#3、制作平均薪资的直方图
plt.style.use('ggplot')
df_duplicates.avgSalary.hist()
plt.show()#展示图表(在pycharm中使用show()来呈现图表)
结果如下:
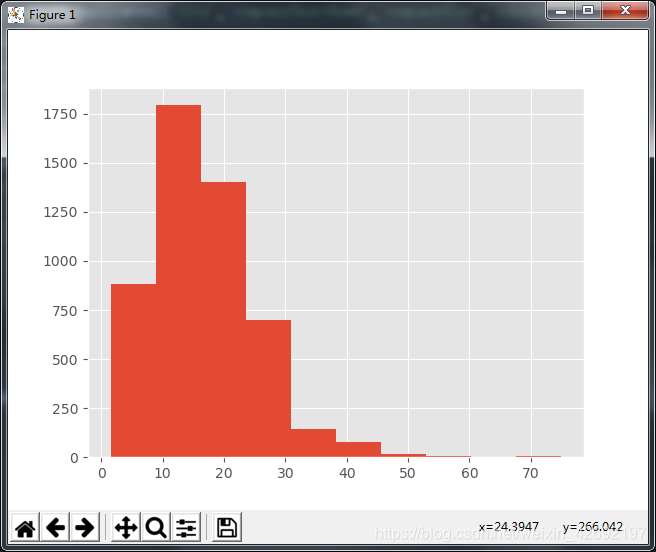
这个图表太过于粗暴,且没有比较实质性的信息,我们尝试下对这个图表进行修改:
将直方图的宽距进行缩小,bins=20
df_duplicates.avgSalary.hist(bins=20)
结果如下:
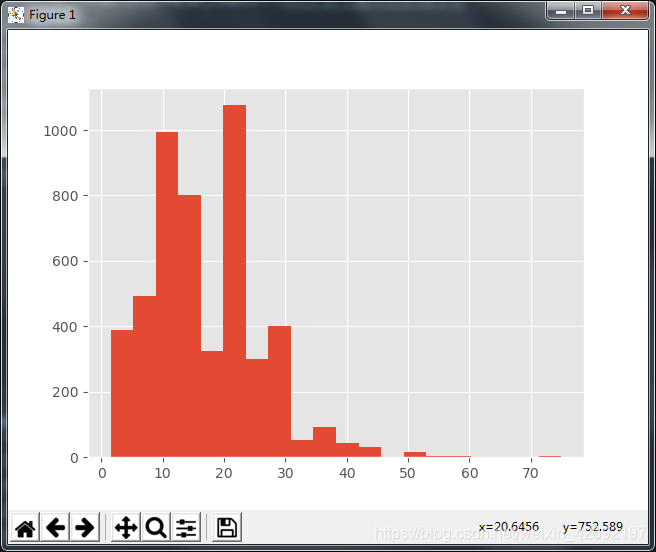
我们可以看到平均薪资会呈现一个比较有意思的分布,10K到20K之间有一个区间是凹进去的,这个区间的频数较低。数据分析师的薪资会呈现一种不均匀分布。
4、箱线图:城市、学历、工作年限(细分维度)
数据分析中一个非常重要的思维就是细分思维,通过多个维度来观察数据的变化情况。这块主要是从城市、学历这两个维度来看对薪资的影响。
(1)城市
df_clean.boxplot(column='avgSalary',by='city',figsize=(9,7))
结果如下:
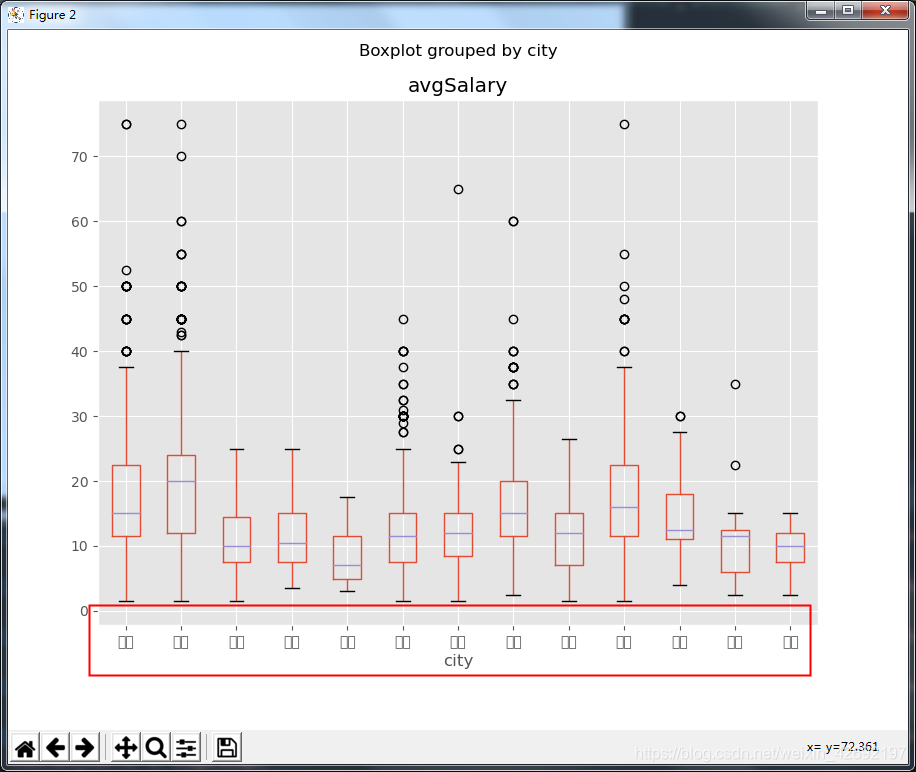
图表的标签没能正常显示,出现了白框。并且抛出警示:RuntimeWarning: Glyph 28145 missing from current font. font.set_text(s, 0, flags=flags)
解决方案如下:
代码如下:新增 plt.rcParams[‘font.sans-serif’]=[‘SimHei’]#显示中文标签
plt.rcParams[‘axes.unicode_minus’]=False
两行代码即可解决抛出警示以及箱线图出现白框的问题
plt.rcParams['font.sans-serif']=['SimHei']#显示中文标签 plt.rcParams['axes.unicode_minus']=False df_clean.boxplot(column='avgSalary',by='city',figsize=(9,7))plt.show()
结果如下:
从下图我们可以看到。北京的薪资高于其他城市,接下来是深圳,上海、杭州,广州甚至比杭州、苏州都要低。相应的,北京、深圳、上海、杭州的薪资波动也较大。

(2)学历
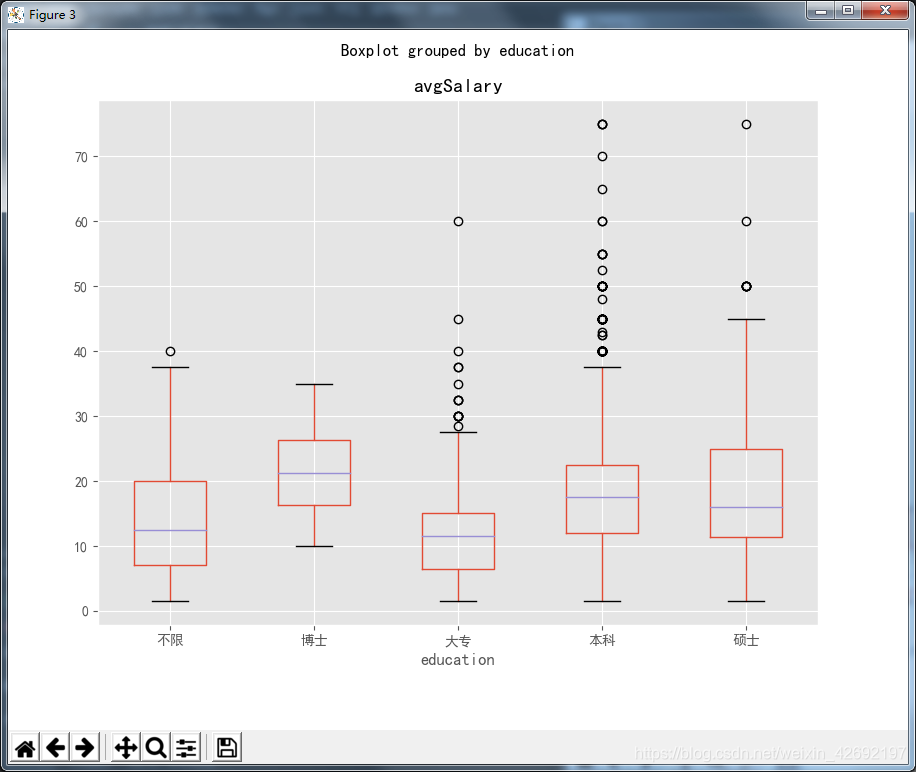
df_clean.boxplot(column='avgSalary',by='education',figsize=(9,7))
结果如下:
从学历上看,博士的薪资最高的,其次是本科,然后到硕士,这个与我们一开始的假定有点出入,且本科这块的异常值也较多,博士的最高工资低于本科和硕士等与假定想法都有一定的出入,后续具体情况原因还需要继续深入分析。
(3)工作年限
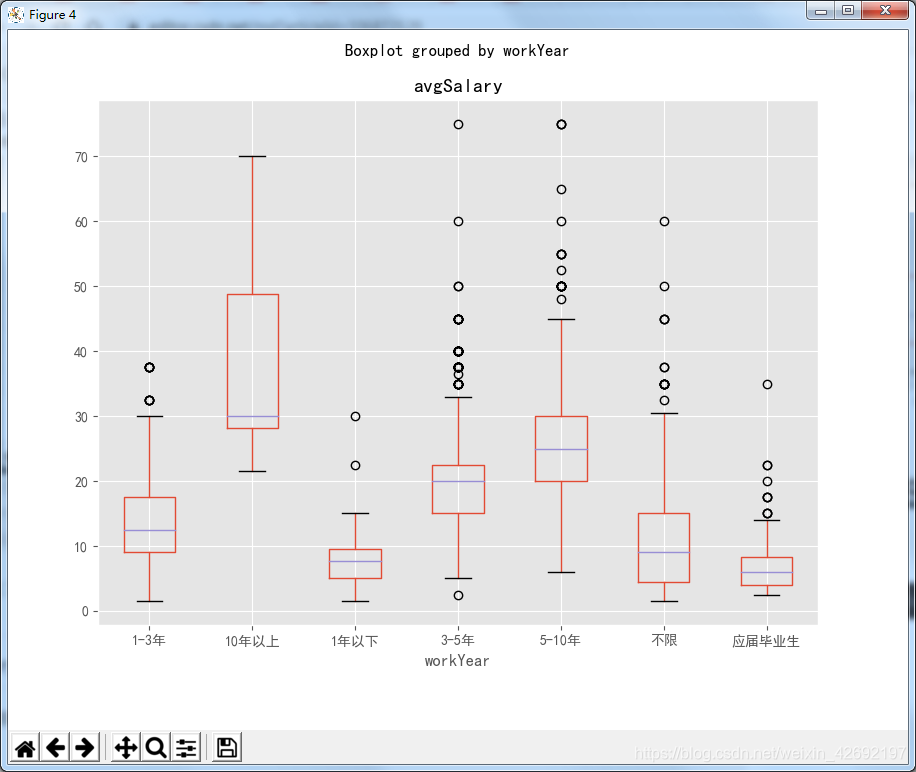
df_clean.boxplot(column='avgSalary',by='workYear',figsize=(9,7))
结果如下:
从工作年限来看,应届毕业生和一年以下的薪资差距不大。应届毕业生与工作年限超过1年相比较,有一个非常明显的薪资增长变化。想做一个对箱线图的X轴按照:不限、应届毕业生、1年以下,1-3年,3-5年,5-10年,10年以上这个顺序进行排序,但目前没有找到较好的解决方案,找到的同学欢迎沟通交流。这样排序能够更清晰的看到,随着工作年限的增加,薪资水平也是不断在增加的,并且增加的比例都较大。说明这个职位未来的发展是非常清晰且有价值的。
(4)学历、城市双维度
上面是单一变量对薪资的影响,我们从两个维度来在看下薪资的变化,选择学历和城市,城市主要选择上海和北京。
选择这部分数据:
df_sh_bi=df_clean[df_clean['city'].isin(['上海','北京'])]
制作箱线图
df_sh_bi.boxplot(column='avgSalary',by=['education','city'],figsize=(9,7))
结果如下:
从下图可以看到,除了大专,在其他的学历背景下,北京的薪资都要高于上海。在博士这个学历中,北京、上海的薪资差距较大,我们可以继续找下相关原因。
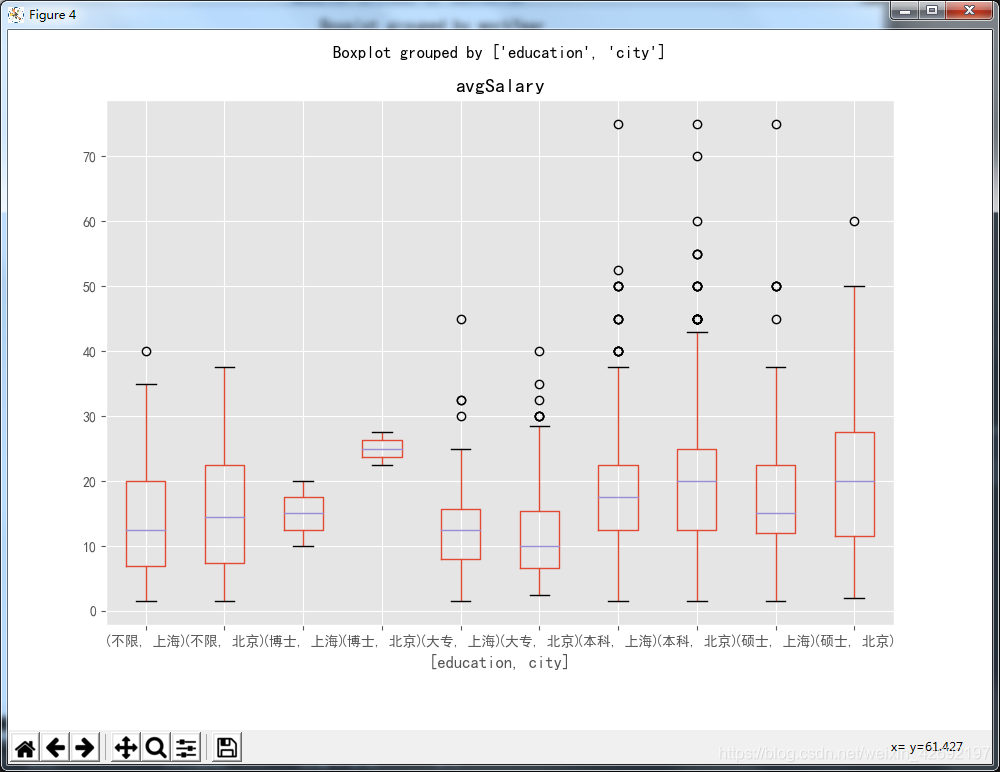
5、分组统计(group相关)
在pandas中,需要同时用到多个维度分析时,可以用groupby函数。它和SQL中的group by差不多,能将不同变量分组。
df_clean.groupby('city')
上图是标准的用法,按city列,针对不同城市进行了分组。不过它并没有返回分组后的结果,只返回了内存地址。这时它只是一个对象,没有进行任何的计算,现在调用groupby的count方法

它返回的是不同城市的各列计数结果,因为没有NaN,每列结果都是相等的。现在它和value_counts等价。
df_clean.groupby('city').count()#与value_counts等价
结果如下:
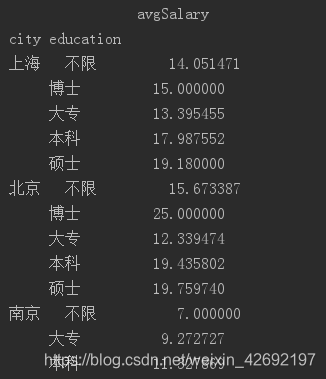
换成mean,计算出了不同城市的平均薪资。因为mean方法只针对数值,而各列中只有avgSalary是数值,于是返回了这个唯一结果。
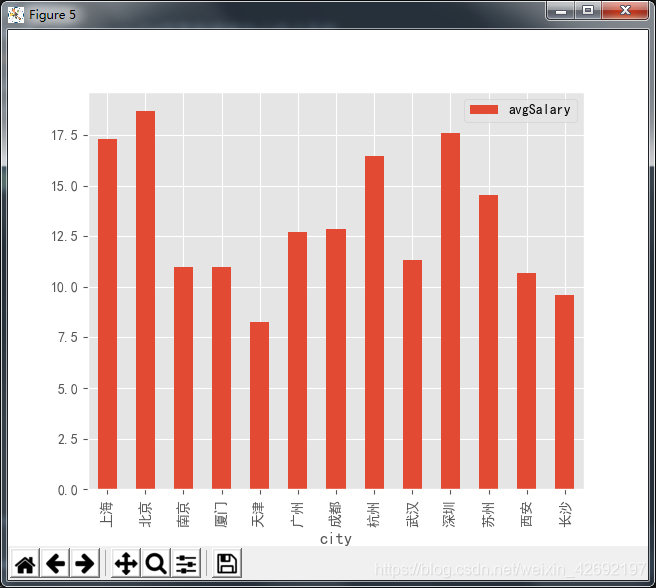
df_clean.groupby('city').mean()
结果如下:

groupby可以传递一组列表,这时得到一组层次化的Series。按城市和学历分组计算了平均薪资。
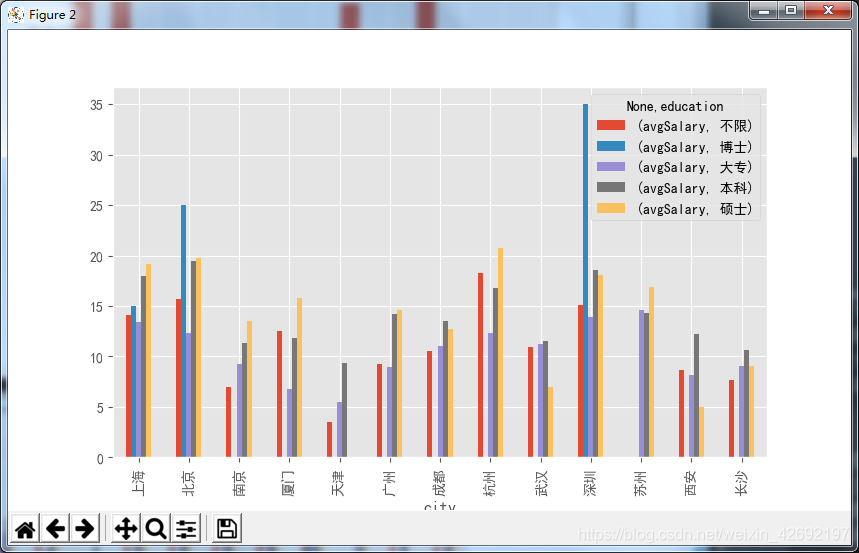
df_clean.groupby(['city','education']).mean()
结果如下:
后面再调用unstack方法,进行行列转置,这样看的就更清楚了。在不同城市中,博士学历最高的薪资在深圳,硕士学历最高的薪资在杭州。北京综合薪资最好。
df_clean.groupby(['city','education']).mean().unstack()
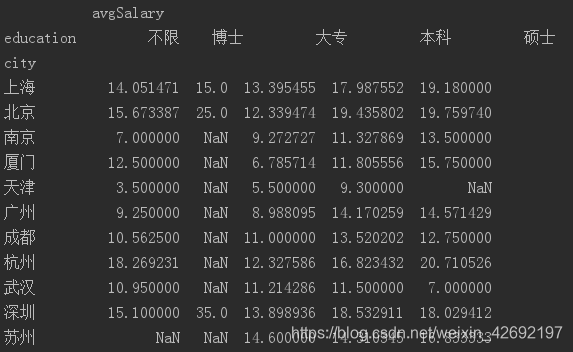
这个分析结论有没有问题呢?不妨先看招聘人数。
这次换成count,我们在groupby后面加一个avgSalary,说明只统计avgSalary的计数结果,不用混入相同数据。图上的结果很明确了,要求博士学历的岗位只有6个,所谓的平均薪资,也只取决于公司开出的价码,波动性很强,毕竟这只是招聘薪资,不代表真实的博士在职薪资。这也解释了上面几个图表的异常。
df_clean.groupby(['city','education']).count().unstack()

groupby是不是和数据透视表比较像?pandas其实有专门的数据透视函数,在另外一方面,groupby确实能完成不少透视工作。
6、分维度统计平均数
接下来计算不同公司招聘的数据分析师数量,并且计算平均数。
这里使用了agg函数,同时传入count和mean方法,然后返回了不同公司的计数和平均值两个结果。所以前文的mean,count,其实都省略了agg。
print(df_clean.groupby('companyShortName').avgSalary.agg(['count','mean']).sort_values(by='count',ascending=False))
结果如下:
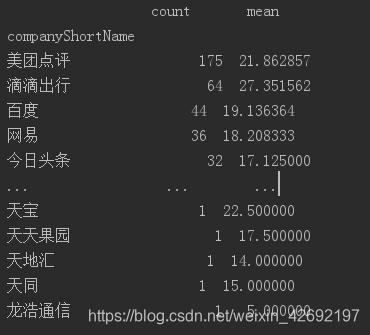
agg除了系统自带的几个函数,它也支持自定义函数。
上图用lamba函数,返回了不同公司中最高薪资和最低薪资的差值。agg是一个很方便的函数,它能针对分组后的列数据进行丰富多彩的计算。但是在pandas的分组计算中,它也不是最灵活的函数。
print(df_clean.groupby('companyShortName').avgSalary.agg(lambda x:max(x)-min(x)))
结果如下:

现在我们有一个新的问题,我想计算出不同城市,招聘数据分析师需求前5的公司,应该如何处理?agg虽然能返回计数也能排序,但它返回的是所有结果,前五还需要手工计算。能不能直接返回前五结果?当然可以,这里再次请出apply。
自定义了函数topN,将传入的数据计数,并且从大到小返回前五的数据。然后以city聚合分组,因为求的是前5的公司,所以对companyShortName调用topN函数。
def topN(df,n=5):
counts=df.value_counts()#获取数据框的分组记录数
return counts.sort_values(ascending=False)[:n] #按照记录数降序排序
print(df_clean.groupby('city').companyShortName.apply(topN))
结果如下:

同样的,如果我想知道不同城市,各职位招聘数前五,也能直接调用topN。
可以看到,虽说是数据分析师,其实有不少的开发工程师,数据产品经理等。这是抓取下来数据的缺点,它反应的是不止是数据分析师,而是数据领域。不同城市的需求不一样,北京的数据产品经理看上去要比上海高。
print(df_clean.groupby('city').positionName.apply(topN))

7、group by 作图
运用group by,我们已经能随意组合不同维度。接下来配合group by作图。
(1)
df_clean.groupby('city').mean().plot.bar()
(2)多重聚合在作图上面没有太大差异,行列数据转置不要混淆即可。
df_clean.groupby(['city','education']).mean().unstack().plot.bar(figsize=(14,6))
上述的图例我们都是用pandas封装过的方法作图,如果要进行更自由的可视化,直接调用matplotlib的函数会比较好,它和pandas及numpy是兼容的。
这里有一个需要注意的点,之前的库是用的normed,但库更新了之后normed这个属性没有了,不过有网友提醒可以用density替代,故这里的代码是用density。
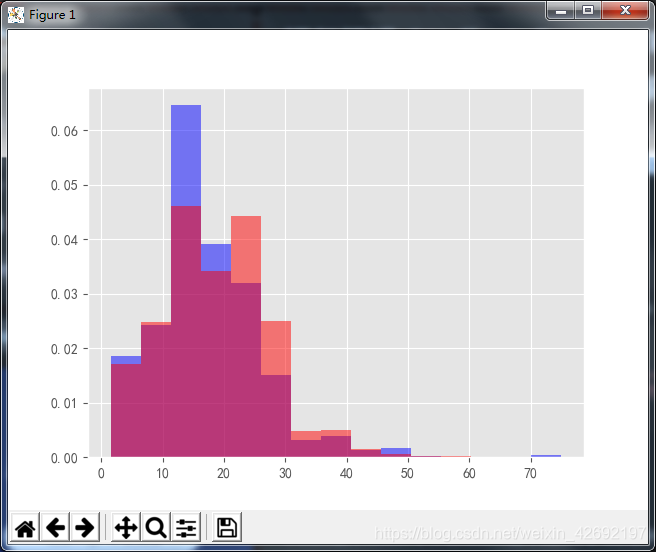
plt.hist(x=df_clean[df_clean.city=='上海'].avgSalary,bins=15,density=1,facecolor='blur',alpha=0.5) plt.hist(x=df_clean[df_clean.city=='北京'].avgSalary,bins=15,density=1,facecolor='red',alpha=0.5)
结果如下:
下图将上海和北京的薪资数据以直方图的形式进行对比。因为北京和上海的分析师人数相差较远,所以无法直接对比,需要用normed参数转化为密度。设置alpha透明度,它比箱线图更直观。
8、对薪资进行划分等级
bins=[0,3,5,10,15,20,30,100] level=['0-3','3-5','5-10','10-15','15-20','20-30','30+'] df_clean['level']=pd.cut(df_clean['avgSalary'],bins=bins,labels=level) df_clean[['avgSalary','level']]
结果如下:
cut的作用是分桶,它也是数据分析常用的一种方法,将不同数据划分出不同等级,也就是将数值型数据加工成分类数据,在机器学习的特征工程中应用比较多。cut可以等距划分,传入一个数字就好。这里为了更好的区分,我传入了一组列表进行人工划分,加工成相应的标签。

df_level=df_clean.groupby(['city','level']).avgSalary.count().unstack()
#print('aa',df_level)
df_level_prop=df_level.apply(lambda x:x/x.sum(),axis=1)
#print('bb',df_level_prop)
ax=df_level_prop.plot.bar(stacked=True,figsize=(14,6))
plt.show()
结果如下:
用lambda转换百分比,然后作堆积百分比柱形图(matplotlib好像没有直接调用的函数)。这里可以较为清晰的看到不同等级在不同地区的薪资占比。它比箱线图和直方图的好处在于,通过人工划分,具备业务含义。0~3是实习生的价位,3~6是刚毕业没有基础的新人,整理数据那种,6~10是有一定基础的,以此类推。
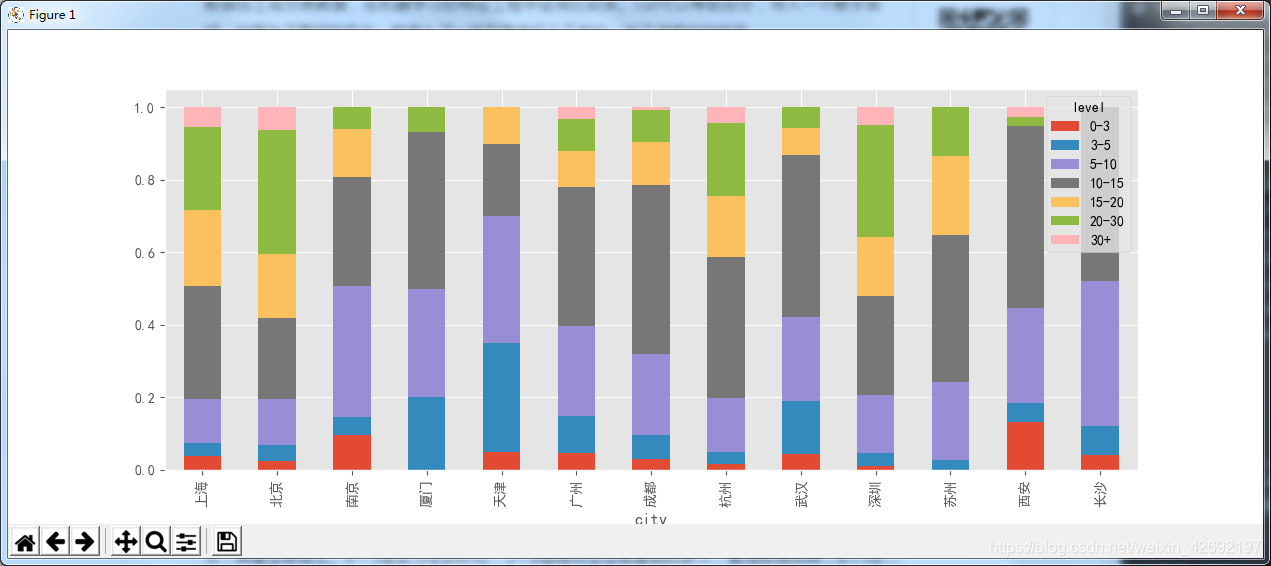
9、标签数据
我们先来看下数据中的标签数据positionLables
df_clean.positionLables
结果如下:

现在的目的是统计数据分析师的标签。
(1)我们先对标签数据做一些简单的处理
word=df_clean.positionLables.str[1:-1].str.replace(' ','')#处理方括号和空格,并将处理过的数据赋给word
df_word=word.dropna().str.split(',').apply(pd.value_counts)#按照','将词进行分割,并统计次每次出现的情况
df_word.unstack()#行列转换

(2)再次处理
df_word.unstack().dropna().reset_index()#删除空值
结果如下:
将空值删除,并且重置为DataFrame,此时level_0为标签名,level_1为df_index的索引,也可以认为它对应着一个职位,0是该标签在职位中出现的次数,之前我没有命名,所以才会显示0。部分职位的标签可能出现多次,这里忽略它。

(3)统计标签数
df_word_counts=df_word.unstack().dropna().reset_index().groupby('level_0').count()#用groupby计算标签出现的次数
结果如下:

(4)词云显示
要先下载wordcloud,在命令提示符中输入一下代码,安装wordcloud.

代码:
df_word_counts.index=df_word_counts.index.str.replace("'","")#将引号处理掉
wordcloud=WordCloud(font_path="C:\Windows\Fonts\simhei.ttf",#使用的字体,有部分字体是不能显示中文的
width=900,height=400,background_color='white')
f,axs=plt.subplots(figsize=(15,15))
wordcloud.fit_words(df_word_counts.level_1)
axs=plt.imshow(wordcloud)#正常显示词云
plt.axis('off')#关闭坐标轴
plt.show()
结果如下:
我们是使用数据分析相关岗位的数据,positionLables是关于这些岗位的一些标签,从下图我们可以看到,数据、大数据、数据分析、分析师是最为重要的关键词,产品经理与数据库是较为关键的,说明在数据相关岗位中,产品也是较为重要的。(数据产品越来越显现其重要性)


- Python程序设计与科学计算精录&总结Episode.7 Python进阶:数据分析库Pandas、Matplotlib与Scikit-learn(基于VS2019)
- python数据分析初探小结(matplotlib,Numpy,Pandas)简单分析下IMDB250电影情况
- Python+pandas+matplotlib数据分析与可视化案例(附源码)
- Python数据分析-初识numpy、pandas、scipy、matplotlib和Scikit-Learn等数据处理库
- 【python数据挖掘课程】十二.Pandas、Matplotlib结合SQL语句对比图分析
- Python点滴(三)—pandas数据分析与matplotlib画图
- 【Matplotlib】数据可视化实例分析
- matplotlib绘图及pandas数据分析小总结
- Python数据分析与挖掘实战(Pandas,Matplotlib常用方法)
- 【Matplotlib】数据可视化实例分析
- Ubuntu16.04安装Python的数据分析库numpy,pandas,scipy,matplotlib
- 利用python中的pandas和matplotlib进行电影数据分析
- 学习Python数据分析(1)----numpy,Pandas,matplotlib,scipy 的安装
- python数据挖掘课程 十一.Pandas、Matplotlib结合SQL语句可视化分析
- pandas,numpy,matplotlib --python数据分析三剑客和数据预处理理论
- python数据挖掘课程 十二.Pandas、Matplotlib结合SQL语句对比图分析
- pandas数据分析及matplotlib画图常用命令
- 【python数据挖掘课程】十二.Pandas、Matplotlib结合SQL语句对比图分析
- 动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题
- 爬虫数据分析------Pandas和Matplotlib