第10讲:Flink Side OutPut 分流
Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
关注公众号:
大数据技术派,回复资料,领取1024G资料。
这一课时将介绍 Flink 中提供的一个很重要的功能:旁路分流器。
分流场景
我们在生产实践中经常会遇到这样的场景,需把输入源按照需要进行拆分,比如我期望把订单流按照金额大小进行拆分,或者把用户访问日志按照访问者的地理位置进行拆分等。面对这样的需求该如何操作呢?
分流的方法
通常来说针对不同的场景,有以下三种办法进行流的拆分。
Filter 分流
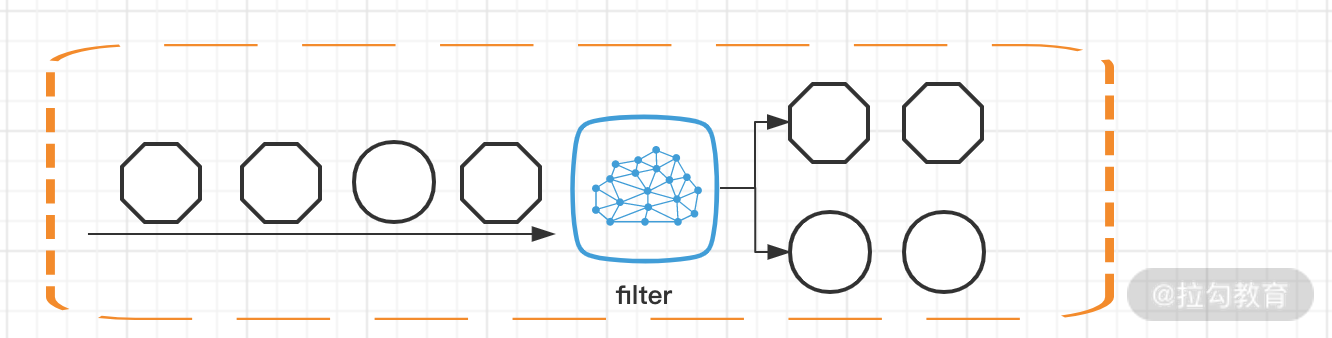
Filter 方法我们在第 04 课时中(Flink 常用的 DataSet 和 DataStream API)讲过,这个算子用来根据用户输入的条件进行过滤,每个元素都会被 filter() 函数处理,如果 filter() 函数返回 true 则保留,否则丢弃。那么用在分流的场景,我们可以做多次 filter,把我们需要的不同数据生成不同的流。
来看下面的例子:
复制代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> zeroStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == 0);
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> oneStream = items.filter((FilterFunction<Tuple3<Integer, Integer, Integer>>) value -> value.f0 == 1);
zeroStream.print();
oneStream.printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
在上面的例子中我们使用 filter 算子将原始流进行了拆分,输入数据第一个元素为 0 的数据和第一个元素为 1 的数据分别被写入到了 zeroStream 和 oneStream 中,然后把两个流进行了打印。
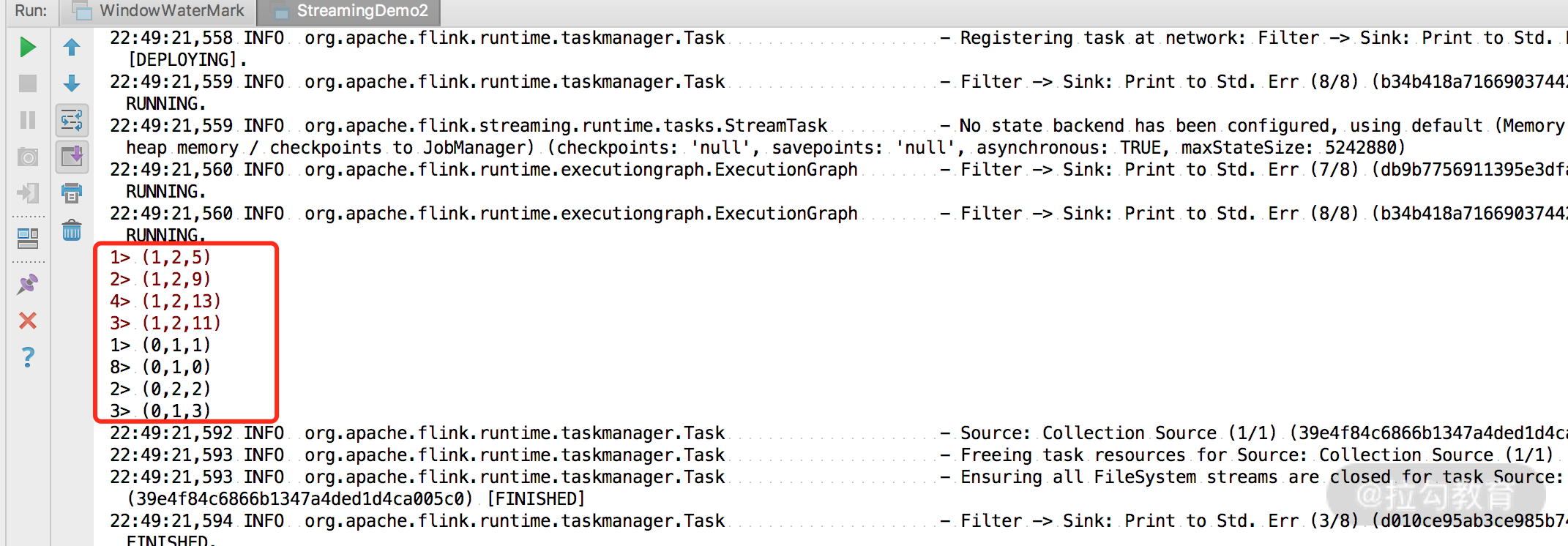
可以看到 zeroStream 和 oneStream 分别被打印出来。
Filter 的弊端是显而易见的,为了得到我们需要的流数据,需要多次遍历原始流,这样无形中浪费了我们集群的资源。
Split 分流
Split 也是 Flink 提供给我们将流进行切分的方法,需要在 split 算子中定义 OutputSelector,然后重写其中的 select 方法,将不同类型的数据进行标记,最后对返回的 SplitStream 使用 select 方法将对应的数据选择出来。
我们来看下面的例子:
复制代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
SplitStream<Tuple3<Integer, Integer, Integer>> splitStream = items.split(new OutputSelector<Tuple3<Integer, Integer, Integer>>() {
@Override
public Iterable<String> select(Tuple3<Integer, Integer, Integer> value) {
List<String> tags = new ArrayList<>();
if (value.f0 == 0) {
tags.add("zeroStream");
} else if (value.f0 == 1) {
tags.add("oneStream");
}
return tags;
}
});
splitStream.select("zeroStream").print();
splitStream.select("oneStream").printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
同样,我们把来源的数据使用 split 算子进行了切分,并且打印出结果。

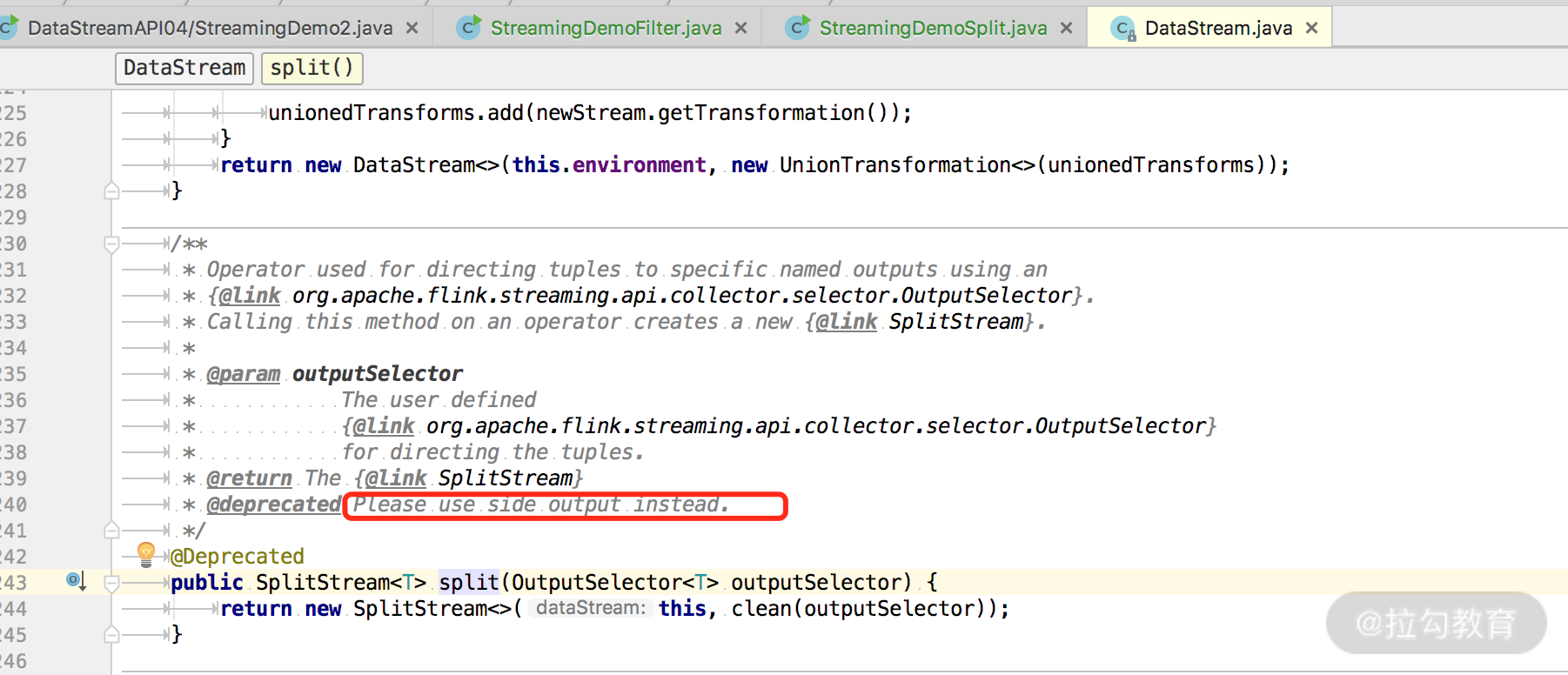
但是要注意,使用 split 算子切分过的流,是不能进行二次切分的,假如把上述切分出来的 zeroStream 和 oneStream 流再次调用 split 切分,控制台会抛出以下异常。
复制代码
Exception in thread "main" java.lang.IllegalStateException: Consecutive multiple splits are not supported. Splits are deprecated. Please use side-outputs.
这是什么原因呢?我们在源码中可以看到注释,该方式已经废弃并且建议使用最新的 SideOutPut 进行分流操作。
SideOutPut 分流
SideOutPut 是 Flink 框架为我们提供的最新的也是最为推荐的分流方法,在使用 SideOutPut 时,需要按照以下步骤进行:
- 定义 OutputTag
- 调用特定函数进行数据拆分 ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
在这里我们使用 ProcessFunction 来讲解如何使用 SideOutPut:
复制代码
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
List data = new ArrayList<Tuple3<Integer,Integer,Integer>>();
data.add(new Tuple3<>(0,1,0));
data.add(new Tuple3<>(0,1,1));
data.add(new Tuple3<>(0,2,2));
data.add(new Tuple3<>(0,1,3));
data.add(new Tuple3<>(1,2,5));
data.add(new Tuple3<>(1,2,9));
data.add(new Tuple3<>(1,2,11));
data.add(new Tuple3<>(1,2,13));
DataStreamSource<Tuple3<Integer,Integer,Integer>> items = env.fromCollection(data);
OutputTag<Tuple3<Integer,Integer,Integer>> zeroStream = new OutputTag<Tuple3<Integer,Integer,Integer>>("zeroStream") {};
OutputTag<Tuple3<Integer,Integer,Integer>> oneStream = new OutputTag<Tuple3<Integer,Integer,Integer>>("oneStream") {};
SingleOutputStreamOperator<Tuple3<Integer, Integer, Integer>> processStream= items.process(new ProcessFunction<Tuple3<Integer, Integer, Integer>, Tuple3<Integer, Integer, Integer>>() {
@Override
public void processElement(Tuple3<Integer, Integer, Integer> value, Context ctx, Collector<Tuple3<Integer, Integer, Integer>> out) throws Exception {
if (value.f0 == 0) {
ctx.output(zeroStream, value);
} else if (value.f0 == 1) {
ctx.output(oneStream, value);
}
}
});
DataStream<Tuple3<Integer, Integer, Integer>> zeroSideOutput = processStream.getSideOutput(zeroStream);
DataStream<Tuple3<Integer, Integer, Integer>> oneSideOutput = processStream.getSideOutput(oneStream);
zeroSideOutput.print();
oneSideOutput.printToErr();
//打印结果
String jobName = "user defined streaming source";
env.execute(jobName);
}
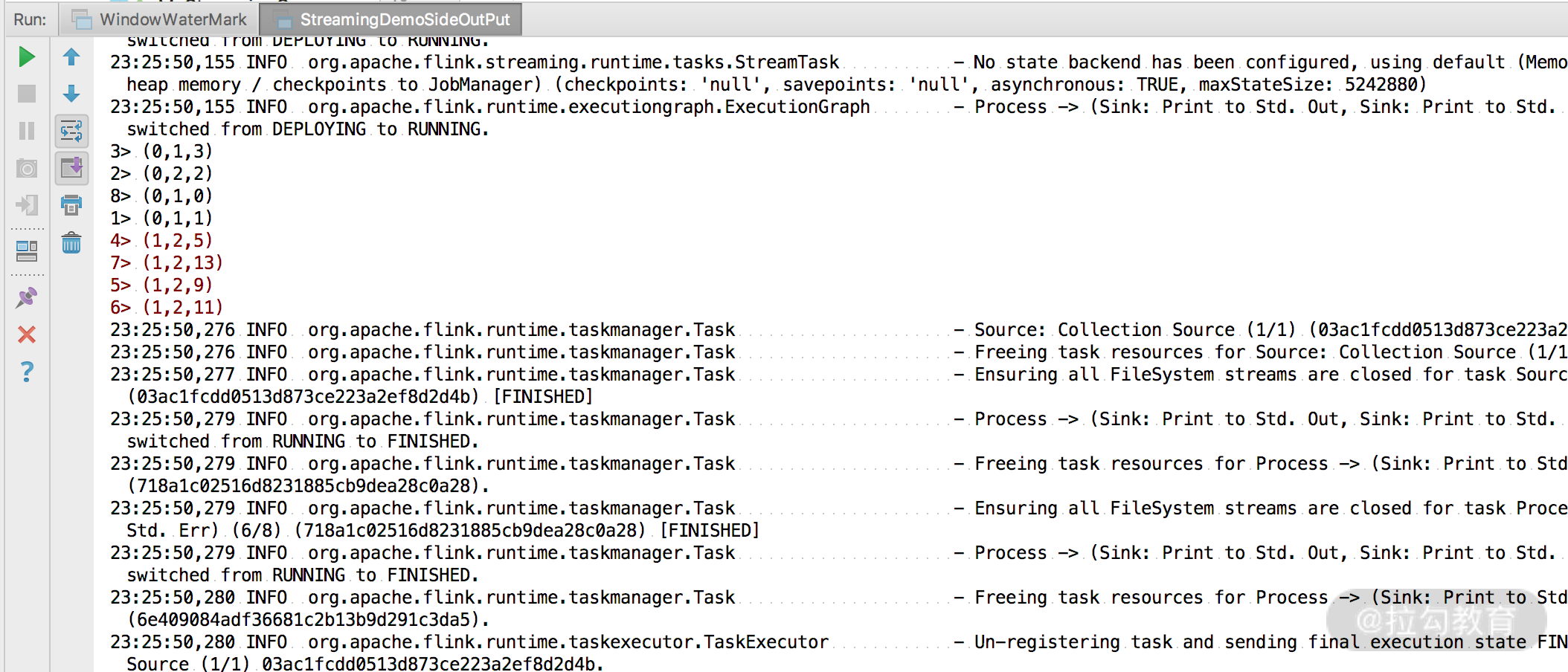
可以看到,我们将流进行了拆分,并且成功打印出了结果。这里要注意,Flink 最新提供的 SideOutPut 方式拆分流是可以多次进行拆分的,无需担心会爆出异常。
总结
这一课时我们讲解了 Flink 的一个小的知识点,是我们生产实践中经常遇到的场景,Flink 在最新的版本中也推荐我们使用 SideOutPut 进行流的拆分。
关注公众号:
大数据技术派,回复资料,领取1024G资料。

- 同网关多条ADSL线路分流实现
- 恒御分流器作为前端分流设备的解决方案
- Linux下多网卡同网段多IP网络分流设定方法
- log4z 多线程下日志分流 使用范例
- Linux多网卡绑定(多网卡分流)
- nginx根据cookie分流
- flink akka scala
- 织梦调用友情链接的调用及样式,文件位置为:\\include\\taglib\\flink.lib.php
- Flink如何应对背压问题
- Apache Flink源码解析之stream-transformation
- 06_Flink Streaming State
- Apache Flink fault tolerance源码剖析完结篇
- Flink - DataStream
- Flink流计算编程--Flink sink to Oracle
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
- Flink流处理之迭代任务
- 函数防抖和函数分流
- Flink架构、原理与部署测试
- Flink – submitJob