python 爬豆瓣TOP250电影练习
未写def,此代码按步执行的,有的只需运行一次,有的需循环执行:
多个#print作为测试用的,可参考:
步骤:
#1. 确定list[page,url]
#2. open html,save html.save path in page.
#3. for page文件夹 for 每个html 保存 数据:
#
# # 爬#
# # https://movie.douban.com/top250
# # 后一页:
# #
# # https://movie.douban.com/top250?start=08&filter=
# # https://movie.douban.com/top250?start=25&filter=
#1. 确定list[page,url] --> TODO 1
#2. open html,save html.save path in page. --> TODO 2-3 运行一次
#3. for page文件夹 for 每个html 保存 数据:
# 重命名文件
# #TODO:1 ************* list[page,ur]**********
page,ur=[],[]
ur.append('https://movie.douban.com/top250?start=08&filter=')
for a in range(25,226,25):
url='https://movie.douban.com/top250?start='+str(a)+'&filter='
ur.append(url)
# print(a)
a+=25
for i in range(1,11):
pg='page'+str(i)
page.append(pg)
i+=1
print(page)
print(ur)
#
# # TODO:2 *************2 传网址 写文件***** 2-3运行一次
from urllib.request import urlopen, Request
for i in range(10):
# print(page[i])
# print(str(ur[i]))
url = ur[i]
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'} # 1
ret = Request(url, headers=headers) # 2
res = urlopen(ret)
aa = res.read().decode('utf-8')
# # 写: #*******************
pg=page[i]+'.html'
f=open(pg,'w',encoding='utf-8')#必须参数 a追加模式,w写人,先清楚后写人 r只读
print('Downloading page %s...' % url)
f.write(aa)
f.close()
# ********************
# # TODO:3 Save page1-page10 PATH to ./TopMovie/
# Save the image to ./xkcd.
import os
path=str('TopMovie/' + str(page[i]) + '/')
os.mkdir(path)
# TODO:6 control page1-page10 :split page saved dict and img files..
for p in range(len(page)):
# # TODO:3 Open files and BeautifulSoup 模块解析.
# ! python3
# downloadXkcd.py - Downloads every single XKCD comic.
#--snip--
# Find the URL of the content img.open
import requests, os, bs4
html=page+'.html'
f = open(html,encoding='utf-8')
Soup = bs4.BeautifulSoup(f,'lxml') #用 BeautifulSoup 模块解析 HTML
t=Soup.select('#content img')
if t == []:
print('Could not find content img.')
else:
# print(type(t), len(t), type(t[0]), t[0])
# print(len(t))
s1=t[0].get('alt') # s=t[0].attrs {'width': '100', 'alt': '盗梦空间', 'src': 'https864.jpg', 'class': []}
# print(s)
# s2 = t[0].get('src') #jpg 网址
# print(s)
for i in range(len(t)):
# f=open("page1_data",'a')
# dr=f.write()
# f.close()
s1 = t[i].get('alt')
s2 = t[i].get('src') #jpg 网址
# comicUrl = 'http:' comicElem[0].get('src')
# Download the image.
print('Downloading image %s...' % (s2))
res = requests.get(s2)
res.raise_for_status()
# TODO:4 Save the image to ./TopMovie
# Save the image to ./xkcd.
path = 'TopMovie/'+str(page[p])+'/'
# print(path)
imageFile = open(os.path.join(str(path), os.path.basename(str(s2))), 'wb')
#s2=https://img9.doubanio.com/view/photo/s_ratio_poster/public/p513344864.jpg
for chunk in res.iter_content(100000): #二进制
imageFile.write(chunk)
imageFile.close()
#TODO:5 rename *.jpg. erro except:
# 重命名:错误,不让程序崩溃
try:
# path = 'TopMovie/' + str(page[p])+'/'
imgName = s2[59:]
os.rename(path + imgName, path + str([i]) + s1 + '.jpg')
except FileNotFoundError as exc:
print('There was a problem: %s' % (exc))
# TODO: NOTES:
# 文件及文件夹改名
# encoding=utf-8
# import os
#
# path = "TopMovie/"
# filelist = os.listdir(path) # 该文件夹下所有的文件(包括文件夹)
# count = 0
# for file in filelist:
# print(file)
# os.renames("aa\\bb", "aaa\\bbb")
# Get the Prev button's url.
# prevLink = soup.select('a[rel="prev"]')[0]
# url = 'http://xkcd.com' + prevLink.get('href')
# TODO: Get the Prev button's url.
print('Done.')
# import bs4
# f = open('example.html')
# Soup = bs4.BeautifulSoup(f,'lxml')
# print(type(Soup))
# t=Soup.select('#author')
# print(type(t),len(t),type(t[0]),t[0]) #<span id="author">Al Sweigart</span> # len(elems)告诉我们列表中只有一个 Tag 对象
# print(t[0].getText()) # Al Sweigart 调用 getText()方法,返回该元素的文本,
# print(t[0].attrs) #{'id': 'author'} attrs 给了我们一个字典,包含该元素的属性'id',以及id 属性的值'author'
#
# t=Soup.select('p')
# print(t,'\n',type(t),'\n',len(t),'\n',t[0])
# for i in range(len(t)):
# s=t[0].getText()
# print(s)
# url='http://quotes.toscrape.com'
# response=request.urlopen(url)
# html=response.read().decode('utf-8')
#
#
# #*******************
# f=open('名言.html','w',encoding='utf-8')#必须参数 a追加模式,w写人,先清楚后写人 r只读
# f.write(html)
# f.close()
# #********************
[p]结果:
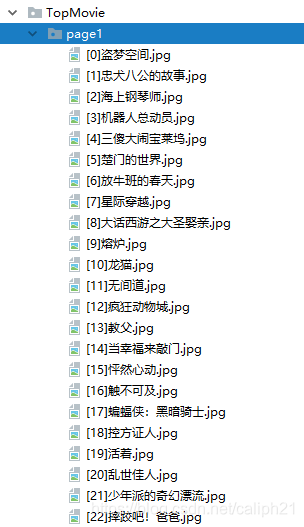
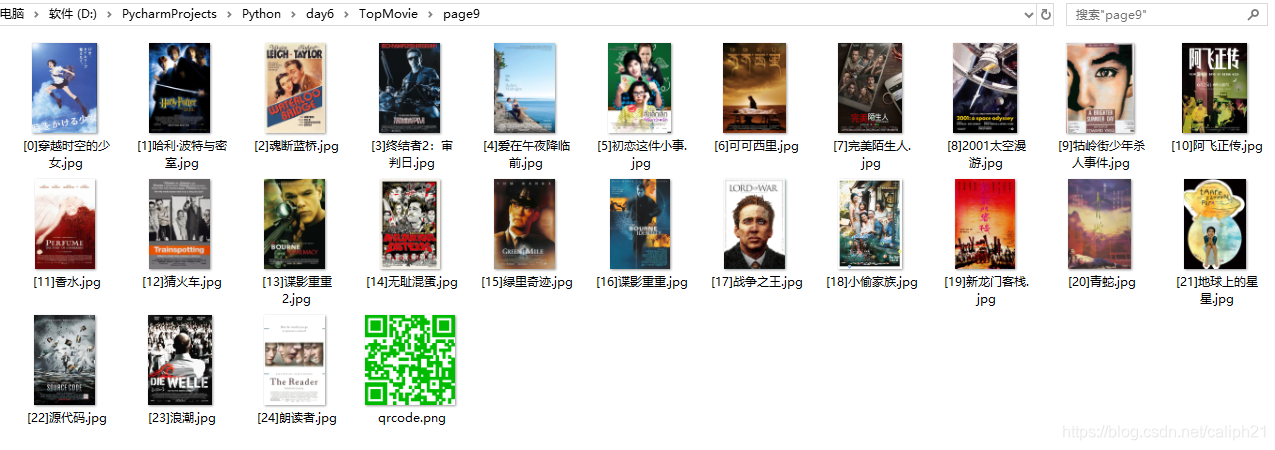
- 点赞
- 收藏
- 分享
- 文章举报
 caliph21
发布了5 篇原创文章 · 获赞 0 · 访问量 321
私信
关注
caliph21
发布了5 篇原创文章 · 获赞 0 · 访问量 321
私信
关注

- Python网络爬虫学习案例——爬取豆瓣电影top250信息
- 萌新的Python学习日记 - 爬虫无影 - 爬取豆瓣电影top250并入库:豆瓣电影top250
- python爬取豆瓣电影Top250的信息
- Python爬虫――爬取豆瓣电影Top250代码实例
- Python爬虫学习笔记 -- 爬取豆瓣电影top250的信息
- python爬去豆瓣top250电影
- python爬取豆瓣top250电影名称
- Python爬虫之多线程下载豆瓣Top250电影图片
- neo4j+python知识图谱构建(基于豆瓣TOP250电影)
- Python3.6爬虫爬取豆瓣电影Top250信息
- 新手第一次使用python爬取豆瓣电影top250遇到的错误
- Python爬虫学习-豆瓣电影TOP250数据爬取(存入mongo数据库中)
- 爬虫练习-爬取豆瓣电影TOP250的数据
- Python爬虫案例1:手把手教你爬取豆瓣TOP250电影各种信息
- 用Python爬虫爬取豆瓣电影、读书Top250并排序
- Python3爬虫豆瓣电影TOP250将电影名写入到EXCEL
- Python爬虫1-利用Scrapy抓取豆瓣电影top250数据
- 小白之python开发:豆瓣电影top250的爬取
- [Python]计算豆瓣电影TOP250的平均得分
- python爬虫|爬取豆瓣电影TOP250并写入txt中