neo4j+python知识图谱构建(基于豆瓣TOP250电影)
爬取内容网站:https://movie.douban.com/top250?start=0&filter=
第一步:明确节点nodes和关系relations。
针对本文,有4个节点,4个关系。一个节点就相当于一个实体。
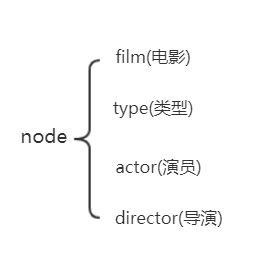
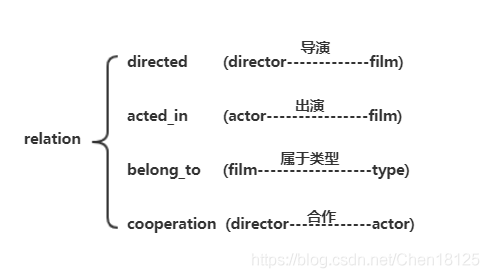
【注明:因为一部电影可以属于很多种类型,比如《肖申克的救赎》可以属于犯罪,也可以属于剧情,因此把type(类型)也作为一个节点。】
因此,一共需要生成八个文件,包括四个节点文件和四个关系文件。

文件类型规定:本文使用csv文件。
节点文件(以director.csv为例):第一列为index:ID,最后一列为:LABEL(实体的标签),中间列为实体属性。注意实体属性最好用英文表示。

关系文件(以directed.csv为例):第一列为:START_ID(相当于关系的实施者的index:ID),此处为director的index:ID;第二列为:END_ID(相当于关系的实施对象的index:ID),此处为film的index:ID;第三列为relation(关系),此处为directed;第四列为:TYPE(关系类型),此处为directed。一般来说,关系和关系类型区别不是很大,可以一致。

第二步,将八个csv文件导入neo4j。

节点路径和关系路径可以根据自己需要指定。文件路径的根目录默认为neo4j/bin。
另外,在执行此语句前要确保没有movie.db这个数据库,并且conf文件中注释这句dbms.active_database=movie.db(如果存在的话),不然会报数据库存在的错误。
导入成功后,再在conf文件中添加语句dbms.active_database=movie.db或取消注释。
第三步,打开neo4j数据库,进行查看。(以下为关系acted_in的其中一小部分截图)
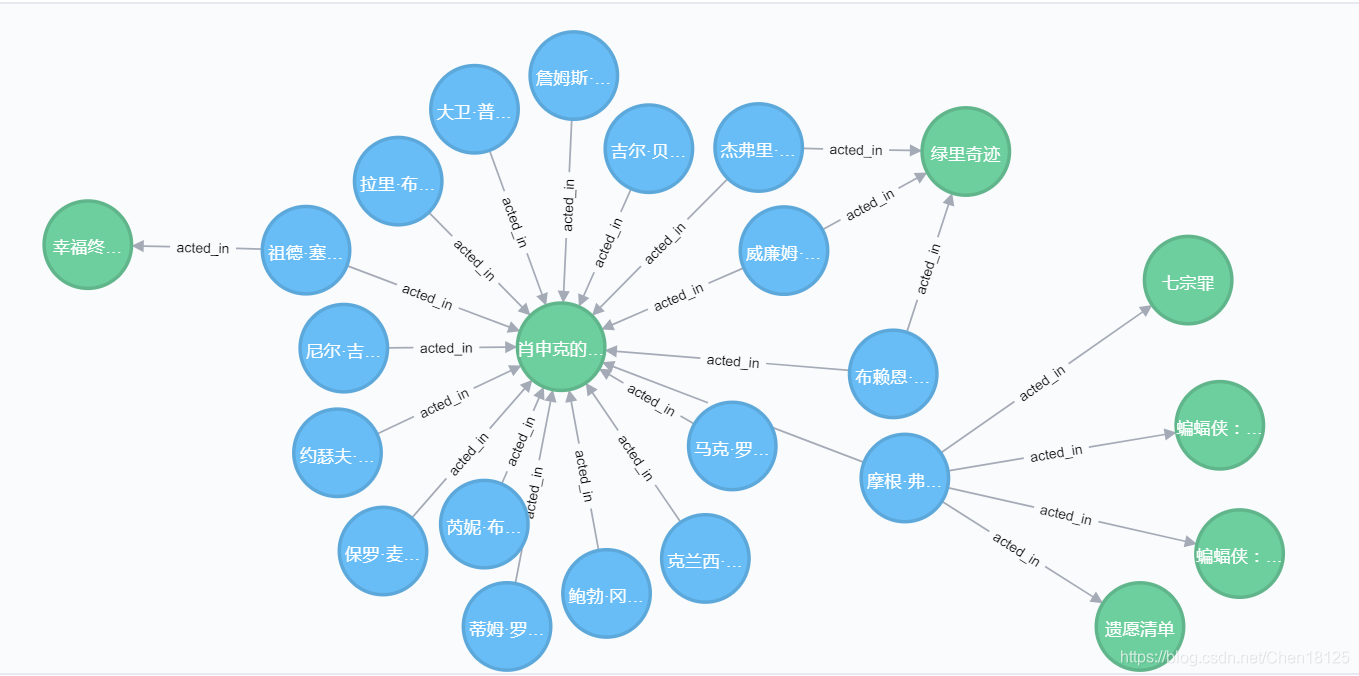
第四步,用cypher语句对此数据库进行查询、增加节点或关系等操作。
知识存储-cypher查询语句基础:https://blog.csdn.net/amao1998/article/details/80999423
参考文章:https://blog.csdn.net/shr903988854/article/details/83145088

- 【知识图谱】杨娟:告别传统,基于知识图谱技术构建智能CRM
- 新手第一次使用python爬取豆瓣电影top250遇到的错误
- python3爬虫豆瓣top250电影(并保存到mysql数据库)
- 基于知识图谱的电影自动问答系统(一)知识的获取与存储
- 基于python的豆瓣“我看过的电影”的爬虫
- 基于知识图谱的电影自动问答系统(一)知识的获取与存储
- Python爬虫案例1:手把手教你爬取豆瓣TOP250电影各种信息
- Python爬虫之多线程下载豆瓣Top250电影图片
- 基于知识图谱的电影自动问答系统(二)自动问答实现
- 基于知识图谱的电影自动问答系统(二)自动问答实现
- 基于Python的豆瓣电影评分查询器
- Python调用豆瓣API抓取top250电影并存储进数据库
- 利用Python+Gephi构建金庸人物知识图谱
- python实践2——利用爬虫抓取豆瓣电影TOP250数据及存入数据到MySQL数据库
- python爬虫|爬取豆瓣电影TOP250并写入txt中
- Python3爬虫豆瓣电影TOP250将电影名写入到EXCEL
- Python爬虫案例1:手把手教你爬取豆瓣TOP250电影各种信息
- Python3.6爬虫爬取豆瓣电影Top250信息
- 基于微信公众平台的Python开发——豆瓣电影搜索
- Python爬虫1-利用Scrapy抓取豆瓣电影top250数据