(五)从零开始学人工智能-搜索:通过搜索解决问题
通过搜索来解决问题
文章目录
- 通过搜索来解决问题
- 1. 什么是算法?
- 2. 什么是搜索?
- 3. 搜索算法
- 3.1 如何做路径规划?
- 3.2 搜索过程
- 3.3 通用搜索算法
- 3.4 盲目的搜索算法
- 3.4.1 深度优先遍历(Deep First Search)
- 3.4.2 广度优先遍历(BFS)
- 3.4.3 Dijkstra 算法
狄更斯的《双城记》中第一句话是:这是最好的时代,也是最坏的时代。

这本首次出版于1859年的书距离我们已经150多年了。如果狄更斯来到今天,我们可以坚定地告诉他:“这是最好的时代,也是最坏的时代。”
因为我们正在从信息时代跨入智能时代。曾经,我们要学习如何操作机器,掌握机器的语言,向机器靠拢。而今天,机器在向人类靠拢,试图理解人类、用我们的语言与我们对话。这就是“智能时代”,这个时代的基础是数据和算法。
我们还没有经历过机器在智能上全面超越人类的时代,我们需要在这样的环境中学会生存。这将是一个让我们振奋的时代,也是一个给我们带来空前挑战的时代。
这两年,出尽风头的人工智能是阿尔法狗。阿尔法狗(AlphaGo)是第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能程序,由谷歌(Google)旗下DeepMind公司戴密斯·哈萨比斯领衔的团队开发。具体到下棋的策略,阿尔法狗里面有两个关键的技术:
第一个是把棋盘上当前的状态变成一个获胜概率的数学模型,这个模型的关键是靠大数据训练(学习)出来的。
第二个是启发式搜索算法——蒙特卡洛树搜索算法(Monte Carlo Tree Search),这个算法能将搜索的空间限制在非常有限的范围内,保证计算机能够快速找到好的下法。
由此可见,下围棋这个看似智能型的问题,从本质上讲,是一个大数据和算法的问题。
数据和算法是驱动智能时代的两架马车。“大数据”这个时髦的词听得我们耳朵都要长茧了。今天我们不说数据,来谈谈算法,并重点引入上文提到的搜索算法及其应用。
1. 什么是算法?
在很多人眼里,很多人认为算法是这样的:

或者是这样的:

恭喜你,你的感觉是对的😹😂
但是你想过没有,最开始的它其实是这样的,又萌又直接:<{=....(嘎嘎嘎~)

这个图诠释了纳兰性德的词:“人生若只如初见”,再回首:“哇的一声哭出来~ ”
谁si谁知道~,憋着"你行你上"内心,可能是这样的:

这说明什么的呢?我们还是得从基础入手,而不是一步跳到算法的深海中去,不信来看看😂
按照老传统,我们对算法给出一个定义,算法在百度百科中的定义如下:
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。
一个算法应该具有以下五个重要的特征:
有穷性:(Finiteness)算法的有穷性是指算法必须能在执行有限个步骤之后终止;
确切性:(Definiteness)算法的每一步骤必须有确切的定义;
输入项:(Input)一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;
输出项:(Output)一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
可行性:(Effectiveness)算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步,即每个计算步都可以在有限时间内完成(也称之为有效性)。
是不是看着很迷糊?是的,定义总是那么晦涩难懂,先不用管它。简单一句话总结:算法就是解决问题的过程。
这个听起来高大上的词,实际上在我们生活中随处可见,每一天我们都会用到各种算法,只是你不知道而已。
比如菜谱就是一个算法。它就是一个饭菜制作的流程,解决我们如何做饭的问题。
按照算法的定义,菜谱具有算法的五个特征。
举个栗子:
菜谱:拍黄瓜
1、黄瓜洗干净。
2、放在案板上,用刀拍开,切小块。
3、蒜切末,花生用刀碾碎。
4、黄瓜加入蒜末、花生粒、生抽、芝麻油、香醋,充分搅拌均匀入味,即可。
有穷性:拍黄瓜,有4个步骤
确切性:每个步骤目标明确。
输入项:黄瓜、蒜、花生、生抽、芝麻油、香醋
输出项:拍黄瓜这道菜
可行性:每个步骤目标明确,能够在有限时间内完成。(拍个黄瓜也就5分钟)
其实,菜谱也好,说明书也好,人生的取舍与选择也好,商业战略决策也好,这些都是一种算法问题。
举两个生活中应用简单算法的例子:
比如打印一个20页的文件,需要打2份。
打印出来的文件排序是:“112233445566….2020”。现在你开始分成两份,正常情况下,你会左一张右一张这样分成两摞。
实际上有个更简易的分法:先在左边分1张,然后右边分两张,再左边分两张,再右边分两张……最后一张分左边。排序如下:[1,12,23,34,45…1920,20]
通过采用算法的优化,一次两张的分法,工作量一下减少了一半。
再比如,快速排序算法:
作为一名有前途的图书管理员,你需要把还回来的一堆书(比如有100本)按顺序入架。你该怎么做?
传统的办法:
一本一本书按照序号还回到书架。100本书,你需要跑100次。经过算法优化的方法:
先从这堆书里随便挑出来一本,
把比它号小的扔左边,比它号大的扔右边。
分成两堆后,再重复上面的步骤。
从小到大排序后的书,按照书架顺序归类。
每个书架跑一次,可能只需要跑10次就完成了。
通过采用算法的优化,工作量能够减少了一大半。
从以上生活中的例子能看出来,自从人类有文明以来,我们就一直在发明、使用和传播各种各样的算法,用于衣、食、住、行,等等。
上面的例子中算法虽然有用,但是我们用笨方法也能完成任务。
然而,在人生中,很多时候会面临选择的问题。人生没有回头路,用笨方法的人往往会“后悔”和“错过”。尤其是在今天这个智能时代,不掌握点有用的算法,最好的时代也会变成最坏的时代。因为不掌握点算法,你可能终被算法替代,退一步,就算终将被替代,但是不掌握点算法的话,你会连被谁干掉的都不知道。
算法并非猛兽,但是它可以成为猛兽!言归正传,了解什么是算法之后,进入我们今天的主题,搜索算法,那什么是搜索算法呢?以及它能干什么呢?带着这些个问题,我们一探究竟。
2. 什么是搜索?
生活中我们常常遇到关于搜索的问题,比如下图,现在想要从同花顺大楼开车到杭州东站,能到达的路线会有很多,那怎么找出最快的路线呢?

另一个例子,经典的华容道游戏,如何用最少的步骤让曹操移动到棋盘的最下部?

如何解决类似这样的方方面面的问题呢?
3. 搜索算法
老规矩,我们先给出搜索算法定义,有一个先验印象:
搜索算法是利用计算机的高性能来有目的的穷举一个问题解空间的部分或所有的可能情况,从而求出问题的解的一种方法。现阶段一般有枚举算法、深度优先搜索(DFS)、广度优先搜索(BFS)、A*算法、回溯算法、蒙特卡洛树搜索、散列函数等算法。
通过搜索我们可以解决许多在生活中、科研和工程领域有趣的问题,搜索算法可以被分为以下两种:
- 盲目的搜索算法,或称无信息图搜索算法 除了问题的定义之外,没有给出其他信息。虽然可以解决问题,但不一定是最优解,这类算法常用的有: 广度优先搜索
- 深度优先搜索
-
给出了一些指引,根据提示找到最佳方案,常用的有:
贪婪最佳优先算法
接下来我们以例子的形式讲解搜索过程,即上述算法。
3.1 如何做路径规划?
罗马尼亚度假问题
罗马里亚度假问题是一个经典的路径规划问题,即搜索最佳路径。
搜索问题通常可以用图来表示,本例为示例,实际生活中地图的路径规划问题要复杂的多。
假设我们目前在Arad,明天要赶往布加勒斯特(Bucharest),现在需要找出一条通往布加勒斯特的最短路径。
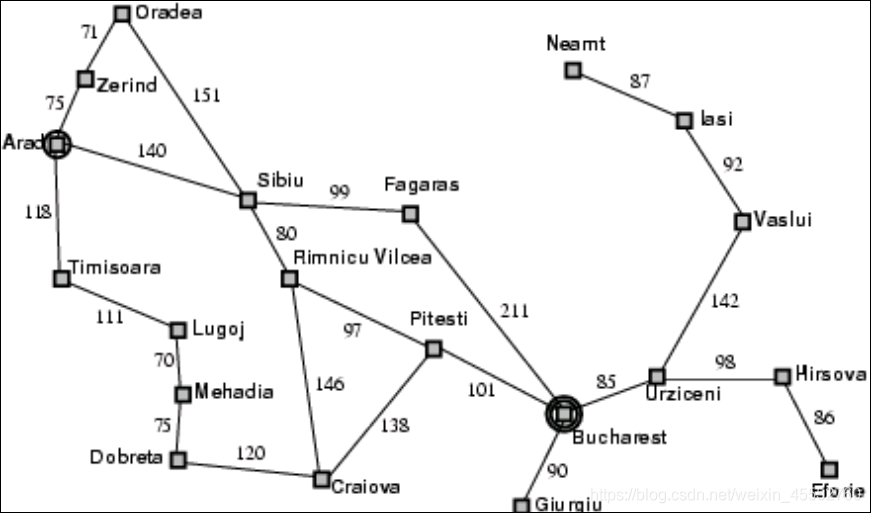
为了方便描述,我们做了如下约定:
初始状态: 开始的初始状态,例如我们在罗马尼亚的初始状态是 In(Arad)
当前所在为位置。
动作: 描述可能采取的操作。给定一个状态s,Actions(s)返回在s中可以执行的一组操作,例如在状态 In(Arad)中,可以采取的操作是到三个城市 {Go(Sibiu)、Go(Timisoara)、Go(Zerind)}
当前位置情况下,可以去的城市路径。
转换模型: 对每个动作的描述, 它由一个函数Result(s,a)指定,该模型返回在状态中执行动作a后所产生的状态。RESULT(In(Arad),Go(Zerind)) = In(Zerind)
可以简单理解为已经走过的路径。
图(路径): 初始状态、动作和转换模型隐式定义问题的状态空间
由任意一系列动作从初始状态可到达的所有状态集。状态空间形成有向网络或图,其中节点是状态,节点之间的链接是动作。
可以简单理解为上图的地图。
目标测试: 测试给定状态是否为目标状态。在这个问题中,我们的目标是 set{In(Bucharest)}。
走过的路径是否为最短路径。
路径成本: 到达目的地的一条路径的成本可能是以公里为单位的数值。
所走路径的路程长度。
3.2 搜索过程
明了问题之后,如何解决呢?
在搜索过程中,从初始位置开始实际上是建立了一棵搜索树,在搜索过程中树的分支对应于已探测的路径。
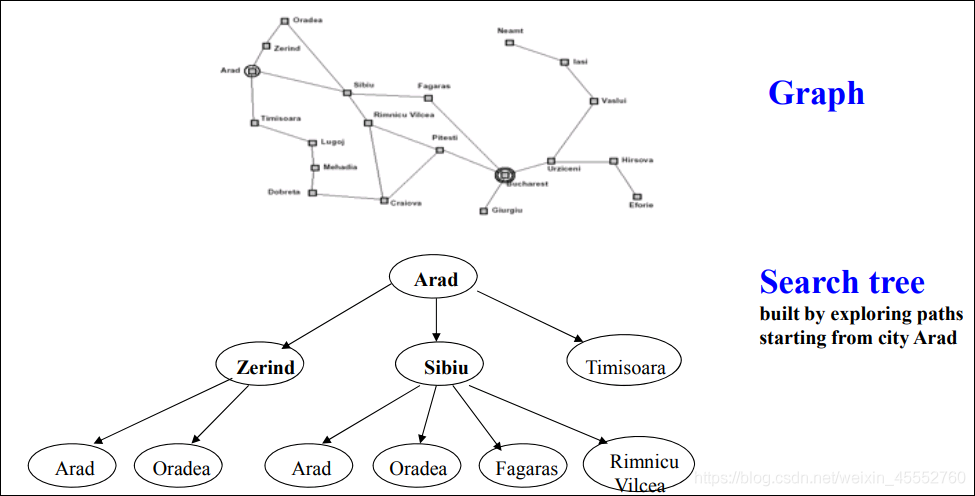
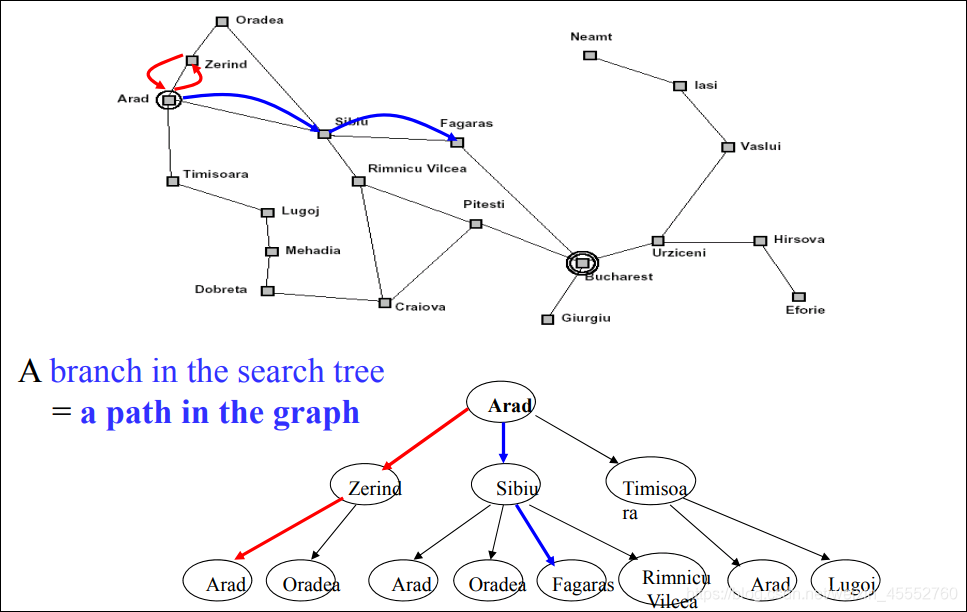
搜索树中的分支,实际上对应的是图中的一个分支,如下图的对应关系。
3.3 通用搜索算法
我们已经知道搜索的过程是建立一棵搜索树的过程,那么针对搜索问题,我们可以抽象一个通用的搜索算法:
General-search (problem, strategy) init() //根据问题的初始状态初始化搜索树 loop if 没有可进一步可探测的候选节点 return failure 根据算法选择下一个节点来探测 if 这个节点满足目标条件 return 最终方案 展开节点并将其所有后继节点添加到搜索树 end loop
看不懂?!没关系,客官不要急,后面都会懂的🎃
下图中,初始点位置为Arad,候选的城市有三个:Zerind,Sibiu,Timisoara。

接下来的一步中,如果选择了Zerind。
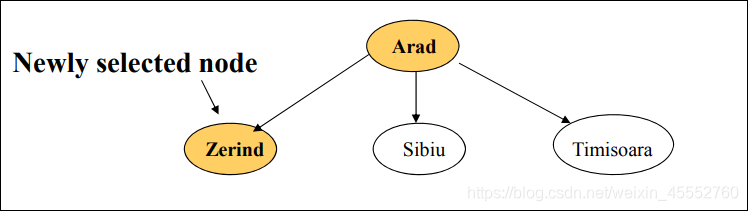
判断选择的点是不是目的地,根据任务描述,这显然不是终点,则继续探索路径。

接下来候选点(城市)变为Oradea,Sibiu,Timisoara。
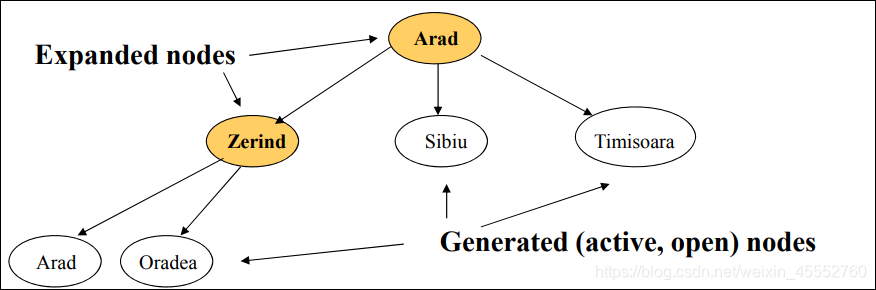
在继续往下探索的过程中,大家可能会发现一个问题,那我是先选择Oradea这条路呢,还是选择Sibiu或者Timisoara这条路?这就涉及到我们的遍历方法了。

不同搜索方法在探索空间的方式上有所不同,也就是他们如何选择下一步要扩展的节点方式不同!
下面我们介绍一下主要的搜索遍历方式
3.4 盲目的搜索算法
3.4.1 深度优先遍历(Deep First Search)
顾名思义,这种遍历方法是以深度为优先对图进行搜索或者遍历,我们可以先看下DFS的基本步骤:
从当前节点开始,先标记当前节点,再寻找与当前节点相邻,且未标记过的节点: (1)当前节点不存在下一个节点,则返回前一个节点进行DFS (2)当前节点存在下一个节点,则从下一个节点进行DFS
概括得通俗一点就是 “顺着起点往下走,直到无路可走就退回去找下一条路径,直到走完所有的结点。”
我们用图的方式来演示一下DFS的过程。
一开始,可以看出,若没有走到最终的叶子节点,这种遍历方式会从start节点沿着一条路一直深入遍历下去(start -> 1 -> 2 -> 3)。
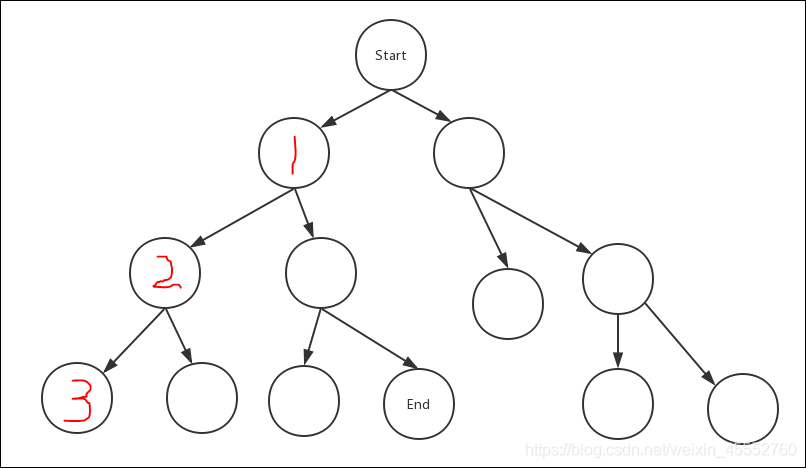
若走到叶子节点,便会退回上一节点,遍历上一节点的其他相邻节点(2 ->3-> 4)。

这样一直重复,直到找到最终目标节点。

如你所见到的一样,这样的搜索方法像一根贪婪的蚯蚓,喜欢往深的地方钻,所以就自然而然的叫做深度优先算法了。
我们可以顺便写出DFS的伪代码:
DFS_find(节点){
if(此结点已经遍历 || 此节点在图外 || 节点不满足要求) return;
if(找到了end节点) 输出结果 ; return;
标记此节点,表示已经遍历过了;
while(存在下一个相邻节点) find(下一个节点);
}
思考: 如果树的分支无穷深,那怎么办?
由于一个有解的问题树可能含有无穷分枝,深度优先搜索如果误入无穷分枝(即深度无限),则不可能找到目标节点。为了避免这种情况的出现,在实施这一方法时,需要定出一个深度界限,在搜索达到这一深度界限而且尚未找到目标时,即返回重找,所以深度优先搜索算法是不完备的。另外,应用此算法得到的解不一定是最佳解(最短路径)。
3.4.2 广度优先遍历(BFS)
对于深度优先算法,强迫症就很不爽了,并表示:“为什么不干干净净,一层一层地从start节点搜索下去呢,就像病毒感染一样,这样才像正常的搜索的样子嘛!”于是便有了BFS算法。广度优先算法便如其名字,它是以广度为优先的,一层一层搜索下去的。
BFS总是先访问完同一层的结点,然后才继续访问下一层结点,它最有用的性质是可以遍历一次就生成中心结点到所遍历结点的最短路径,这一点在求无权图的最短路径时非常有用。
还是以图的方式来演示,下图中start为搜索的初始节点,end为目标节点:
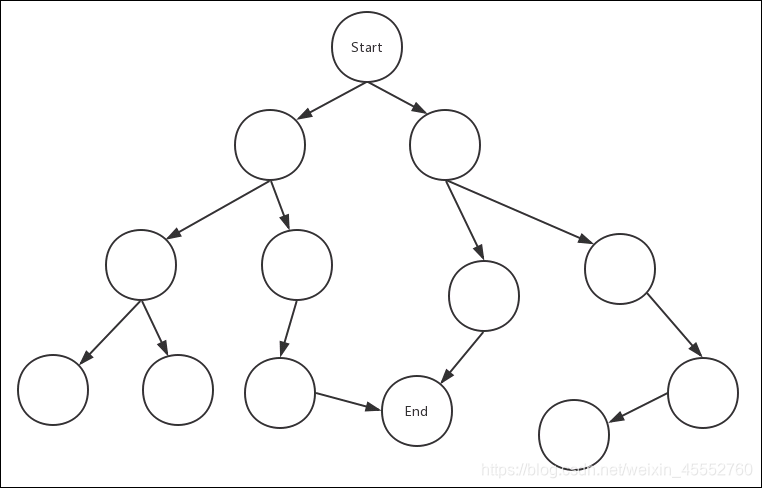
我们先把start节点的相关节点遍历一次

接下来把第一步遍历过的节点当成start节点,重复第一步
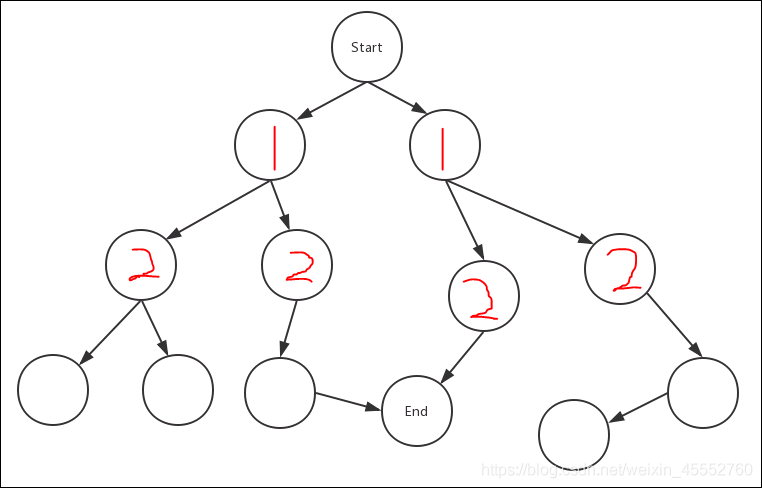
一直重复一二步,这样便是一个放射样式的搜索方法,直到找到end节点

可以看出,这样放射性的寻找方式,能找到从start到end的最短路径(因为每次只走一步,且把所有的可能都走了,谁先到end说明这就是最短路)。
从实现的角度上,在广度优先遍历的过程中,我们需要用到队列:
1. 首先扩展最浅的节点
2. 将后继节点放入队列的末尾(FIFO)
BFS是从根节点(起始节点)开始,按层进行搜索,也就是按层来扩展节点。所谓按层扩展,就是前一层的节点扩展完毕后才进行下一层节点的扩展,直到得到目标节点为止。
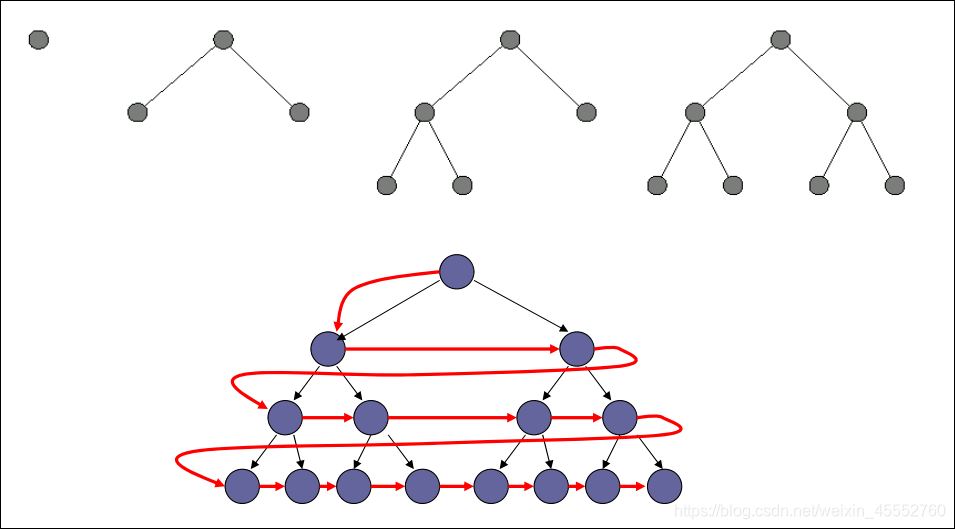
我们可以写出BFS的伪代码
BFS_find(start节点){
把start节点push入队列;
while(队列不为空) {
把队列首节点pop出队列;
对节点进行相关处理或者判断;
while(此节点有下一个相关节点){
把相关节点push入对列;
}
}
}
小结:
一般情况下,深度优先适合深度大的树,不适合广度大的树,广度优先则正好相反。
所谓深度大的树就是指起始节点到目标节点的中间节点多的树(可以理解成问题有很多中间解,这些解都可以认为是部分正确的,但要得到完全正确的结果——目标节点,就必须先依次求出这些中间解)。
所谓广度大的树就是指起始节点到目标节点的可能节点很多的树(可以理解成问题有很多可能解,这些解要么正确,要么错误。要得到完全正确的结果——目标节点,就必须依次判断这些可能解是否正确)。
多数情况下,深度优先搜索的效率要高于宽度优先搜索。但某些时候,对于这两种搜索算法的优劣(或效率)还需要针对不同的问题进行具体分析比较。
扩展: BFS和DFS在搜索引擎中的应用
进一步的,我们做一点扩展,看看BFS和DFS在搜索引擎中的应用。
通常,搜索引擎爬虫会从全网抓取网页,但是全网有数十万亿的网页,谷歌和百度之类的搜索引擎是如何下载整个互联网中的全部网页呢? 是用BFS还是DFS呢?
现在的互联网非常庞大,今天Google的索引中有超过1万亿个网页,即使更新最频繁的基础索引也有几百亿个网页,假如下载一个网页需要一秒钟,下载这100亿个网页则需要317年。
我们已经了解了BFS和DFS的原理,虽然从理论上讲,这两个算法(在不考虑时间因素的前提下)都能够在大致相同的时间里“爬下”整个“静态”互联网上的内容,但这只是理论上的可行性,它有两个假设——不考虑时间因素,互联网静态不变,都是现实中做不到的。

搜索引擎的网络爬虫问题更应该定义成“如何在有限时间里最多地爬下最重要的网页”。显然各个网站最重要的网页应该是它的首页。在最极端的情况下,如果爬虫非常小,只能下载非常有限的网页,那么应该下载的是所有网站的首页,如果把爬虫再扩大些,应该爬下从首页直接链接的网页(就如同和北京直接相连的城市),因为这些网页是网站设计者自己认为相当重要的网页。在这个前提下,显然BFS明显优于DFS。
事实上在搜索引擎的爬虫里,虽然不是简单地采用BFS,但是先爬哪个网页,后爬哪个网页的调度程序,原理上基本上是BFS。 那么是否DFS就不使用了呢?也不是这样的。实际的网络爬虫都是一个由成百上千甚至成千上万台服务器组成的分布式系统。对于某个网站,一般是由特定的一台或者几台服务器专门下载。这些服务器下载完一个网站,然后再进入下一个网站,而不是每个网站先轮流下载5%,然后再回过头来下载第二批。这样可以避免握手的次数太多。如果是下载完第一个网站再下载第二个,那么这又有点像DFS,虽然下载同一个网站(或者子网站)时,还是需要用BFS的。
网络爬虫对网页遍历的次序不是简单的BFS或者DFS,而是有一个相对复杂的下载优先级排序的方法。管理这个优先级排序的子系统一般称为调度系统(Scheduler),由它来决定当一个网页下载完成后,接下来下载哪一个。

扩展阅读:
3.4.3 Dijkstra 算法
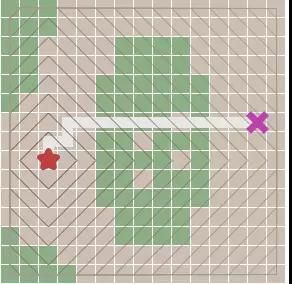
宽度优先算法,解决了起始顶点到目标顶点路径规划问题,但不是最优以及合适的,因为它的边没有权值(比如距离),路径无法进行估算比较最优解。为何权值这么重要,因为真实环境中,2个城市之间的路线并非一直都是直线,需要绕过障碍物才能达到目的地,比如森林,湖水,高山,都需要绕过而行,并非直接穿过。
比如我采用宽度优先算法,遇到如下情况,他会直接穿过障碍物(绿色部分),明显这个不是我们想要的结果:因为这个规划在实际中是一个错误的结果。
那么如何解决带有权重时的寻找最佳路径的问题呢?
寻找图中一个顶点到另一个顶点的最短以及最小带权路径是非常重要的提炼过程。为每个顶点之间的边增加一个权值,用来跟踪所选路径的消耗成本(比如上文提到的城市之间的路程),如果位置的新路径比先前的最佳路径更好,我们就将它放到新的路线中。
Dijkstra 算法基于BFS算法进行改进,把当前看起来最短的边加入最短路径树中,利用贪心算法计算并最终能够产生最优结果的算法。具体步骤如下:
贪心算法,正如它的名字,贪心,每次都选择局部的最优解,并不考虑这个局部最优选择对全局的影响。
1、每个顶点都包含一个预估值cost(起点到当前顶点的距离),每条边都有权值v,初始时,只有起始顶点的预估值cost为0,其他顶点的预估值d都为无穷大 ∞。 2、查找cost值最小的顶点A,放入path队列 3、循环A的直接子顶点,获取子顶点当前cost值命名为current_cost,并计算新路径new_cost,new_cost=父节点A的cost v(父节点到当前节点的边权值),如果new_cost<current_cost,当前顶点的cost=new_cost 4、重复2,3直至没有顶点可以访问.
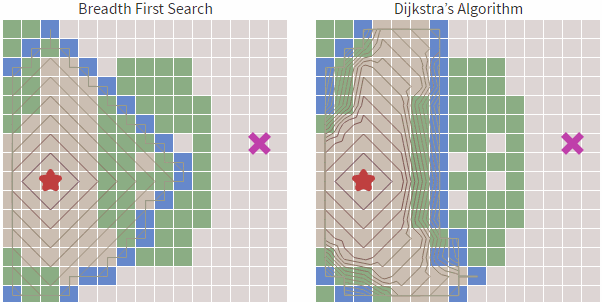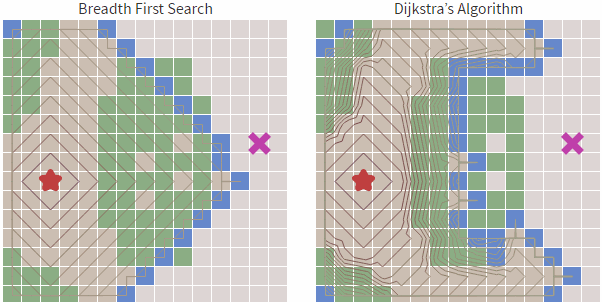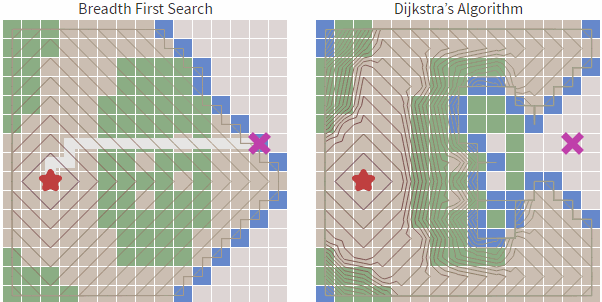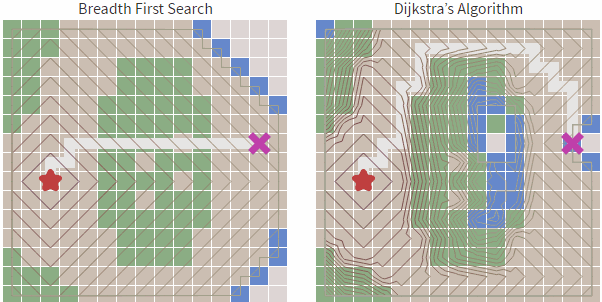
我们看到虽然Dijkstra 算法相对于宽度优先搜索更加智能,基于cost_so_far ,可以规避路线比较长或者无法行走的区域,但依然会存在盲目搜索的倾向,我们在地图中常见的情况是查找目标和起始点的路径,具有一定的方向性,而Dijkstra 算法从上述的图中可以看到,也是基于起点向子节点全方位扩散。
也就是对于Dijkstra算法来说,对全部路径进行了一遍查找,这其实是花费了非常多的工作量的,这种搜索具有有一定的盲目性,那么有没有更好的方法能够解决这种盲目性呢?答案是肯定的,那就是启发式搜索算法。
3.5 启发式搜索算法(有信息的图搜索算法)
在启发式搜索算法中,在问题本身定义之外给出了一些指引,能够比无信息的图搜索算法(如DFS、BFS等)更有效地找到解决方案。
比较经典的启发式搜索算法有贪婪最佳优先算法和A*寻路算法等,在游戏中应用比较广泛。
所有寻路算法都需要一种方法以数学的方式估算某个节点是否应该被选择。大多数游戏都会使用启发式(heuristic) ,以 h(x) 表示,就是估算从某个位置到目标位置的开销。理想情况下,启发式结果越接近真实越好。 ——《游戏编程算法与技巧》
3.5.1 贪婪最佳优先搜索算法(Greedy Best-First Search)
如上所述,贪心算法的含义是求解问题时,总是做出在当前来说最好的选择。通俗点说就是,这是一个“短视”的算法。
搜索的每一步,都会查找相邻的节点,计算它们距离终点的曼哈顿距离,即最低开销的启发式。
曼哈顿距离——两点在南北方向上的距离加上在东西方向上的距离,即h(i,j)=|xi-xj|+|yi-yj|。 对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离,因此,曼哈顿距离又称为出租车距离。
在Dijkstra算法中,我们已经发现了其最致命的缺陷:搜索存在盲目性。而贪婪最佳优先搜索在障碍物少的时候足够的快,但最佳优先搜索得到的都是次优的路径。举例来说,如果目标节点在起始点的南方,那么贪婪最佳优先搜索算法会将注意力集中在向南的路径上。

如下图,算法不断地寻找当前 h(启发式)最小的值,但这条路径很明显不是最优的。贪心最好优先算法虽然做了较少的计算,但却并不能找到一条较好的路径。

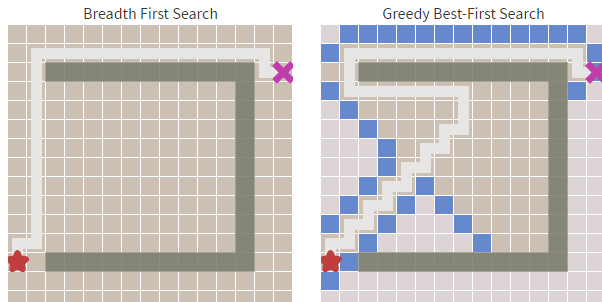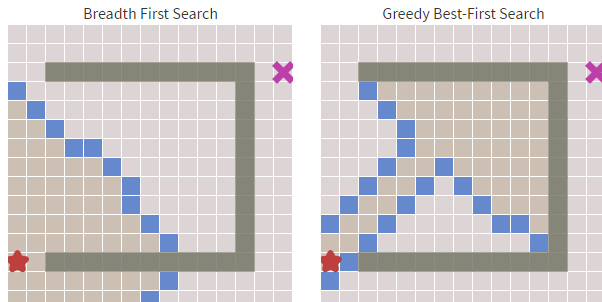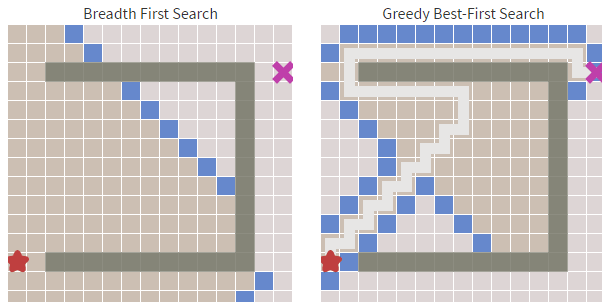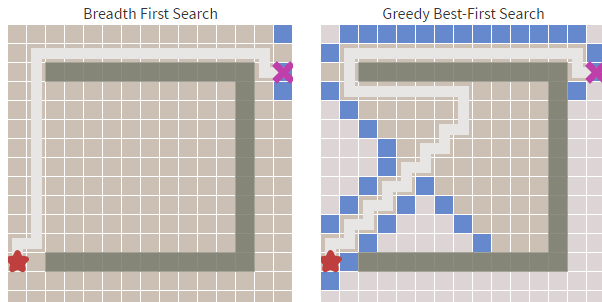
从上图中我们可以明显看到右边的算法(贪婪最佳优先搜索)寻找速度要快于左侧,虽然它的路径不是最优和最短的,但障碍物最少的时候,他的速度却足够的快。这就是贪心算法的优势,基于目标去搜索,而不是完全搜索。
那么这种算法有没有缺点呢? 肯定是有的,那就是得到的路径不是最短路径,只能是较优。
如何在搜索尽量少的顶点同时保证最短路径?我们来看A*算法。
3.5.2 基于BFS的A*寻路算法
从上面算法的演进,我们逐渐找到了最短路径和搜索顶点最少数量的两种方案,Dijkstra 算法和 贪婪最佳优先搜索。那么我们有没有可能汲取两种算法的优势,令寻路搜索算法即便快速又高效?
答案是可以的,A*算法正是这么做了,它吸取了Dijkstra 算法中的cost_so_far,为每个边长设置权值,不停的计算每个顶点到起始顶点的距离,以获得最短路线,同时也汲取贪婪最佳优先搜索算法中不断向目标前进优势,并持续计算每个顶点到目标顶点的距离,以引导搜索队列不断想目标逼近,从而搜索更少的顶点,保持寻路的高效。
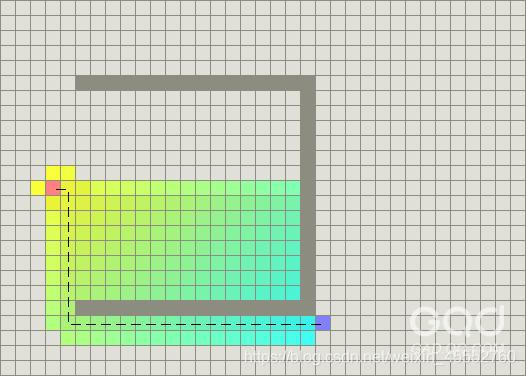
假设g(n)表示从起点到任意节点n的路径长度,h(n)表示从节点n到目标节点路径花费的估计值(启发值)。在上面的图中,黄色体现了节点距离目标较远,而青色体现了节点距离起点较远。A* 算法在物体移动的同时平衡这两者的值。定义f(n)=g(n)+h(n),A*算法将每次检测具有最小f(n)值的节点。然后朝着f(n)最小的点移动。
以下分别是Dijkstra算法,贪婪最佳优先搜索算法,以及A*算法的寻路雷达图,其中格子有数字标识已经被搜索了,可以对比下三种效率:
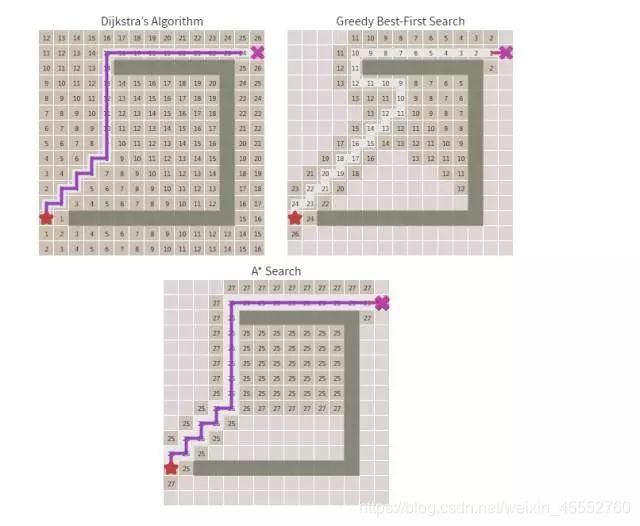
好了,到现在为止我们介绍了盲目的图搜索算法(DFS、BFS、Dijkstra), 启发式搜索算法(贪婪最佳优先、A*),你们是否已经对搜索算法有所了解了呢?
声明
本博客所有内容仅供学习,不为商用,如有侵权,请联系博主谢谢。
参考文献
[1] 人工智能:一种现代的方法(第3版)
[2] 吴军说谷歌爬虫技术
[3] A* Pathfinding for Beginners
[4] A*’s Use of the Heuristic
[5] Solving problems by searching
[6] 夜深人静写算法
- 点赞 8
- 收藏
- 分享
- 文章举报
 一举@hz
发布了16 篇原创文章 · 获赞 36 · 访问量 6593
私信
关注
一举@hz
发布了16 篇原创文章 · 获赞 36 · 访问量 6593
私信
关注

- UOJ#9 浅谈在线仙人球嵌套动态网络路径剖分优化的分支定界贪心剪枝启发式迭代加深人工智能搜索决策算法解决问题
- C++基于人工智能搜索策略解决农夫过河问题示例
- 人工智能3:通过搜索进行问题求解
- 人工智能一种现代的方法 --第3章 通过搜索进行问题求解
- 人工智能(三)上——通过搜索进行问题求解(有信息搜索策略)
- 通过人工智能解决全球气候问题,此举必将成走势
- WINSOCK RESET解决只能通过IP地址访问目的地址,而域名无法访问的问题。
- 新研究旨在用“黑箱”算法解决人工智能偏差问题
- C语言通过深度优先搜索来解电梯问题和N皇后问题的示例
- 通过重建图标缓存文件来解决程序图标显示错误的问题
- 通过openssh远程登录时的延迟问题解决
- 通过SSH向安装在虚拟机上的centOS 上传文件出现的问题及解决方法
- 通过ajax读取json格式数据字符串出现回车时出错问题解决
- IIS7.0通过FastCGI方式运行PHP遇到的一些问题及解决方法
- 通过配置多个DispatcherServlet解决SpringMVC RESTAPI前后端分离资源访问的问题
- IIS7.0通过FastCGI方式运行PHP遇到的一些问题及解决方法
- 解决jeecms问题WEB-INF\web.xml中无法搜索中文的问题
- 八数码问题——双向广度优先搜索解决
- 解决android 2.2 market搜索结果偏少的问题
- bootstrap模态框通过传值解决重复提交问题