Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions论文笔记
文章目录
一、背景:
磁共振成像(MRI)通常是脑结构分析的首选方法,因为它提供了高对比度的软组织图像和高的空间分辨率,并且没有已知的健康风险。虽然计算机断层扫描(CT)和正电子发射断层扫描(PET)等模式也被用来研究大脑,但MRI是最流行的,我们将在本工作中重点研究MRI。脑MRI定量分析广泛应用于阿尔茨海默病、癫痫、精神分裂症、多发性硬化症(MS)、癌症、感染性和退行性疾病等脑疾病的定性。例如,组织萎缩是阿尔茨海默病、癫痫、精神分裂症、多发性硬化症和许多其他神经系统疾病和疾病的诊断和治疗评估中常用的生物标志物之一。为了量化组织萎缩,需要对脑组织进行分割和相应的测量。同样,对大脑结构变化的量化要求对在不同时间点获得的MRI进行分割。此外,异常组织和周围健康结构的检测和精确定位对于诊断、手术计划、术后分析和化疗/放疗计划至关重要。正常结构和病理结构的定性和定量表征,无论是在空间上还是在时间上,都是临床试验的一部分,在这些试验中,对患者和正常对照组的治疗效果进行了研究。
脑部MRI定量分析已经被广泛应用到很多脑部疾病特征分析。为了定量组织萎缩,分割,相应的大脑组织测量都是必须的。相应的,脑部结构变化的定量,要求对在不同时间点获取的MRI分割。除此之外,非正常组织和周围正常结构的检测和精确定位对于诊断,手术规划,术后分析,化疗/放疗计划是至关重要的。正常和病变组织的定量定性特征,包括时间和空间,经常是临床试验的一部分,通过一组病人和正常组来研究治疗效果。神经性疾病和状况一般都需要脑部磁共振图像的定量分析。2D和3D的分割和打标签都是定量分析的重要组成。手动分割是活体图像的金标准。然而,这要求一张一张画出组织结构,不仅昂贵和冗长乏味,而且由于人工错误而不精确。因此有必要使用一种自动分割方法,并且拥有专家级别的精度和高度一致性。 3D,4D图像越来越普及,且生理功能成像越来越多,医学图像在数量和复杂度方面都在增加。机器学习是一系列算法技术,能够使计算机系统从大数据进行数据驱动预测。这些技术有许多可以被应用到医学领域。
迄今为止,已经在MRI脑部图像正常(白质和灰质)和非正常(脑肿瘤)分割的经典机器学习算法上投入了很多研究。然而使得能够分割的图像特征的产生要求熟练的工程和专业知识。更重要的是,传统的机器学习算法并不好用。尽管医学图像搜索社区付出了显著的努力,大脑组织的自动分割和异常区的检测任然没有解决,由于脑部形态正常解剖变异,获取设置和核磁共振成像扫描仪的变化,图像采集的缺陷,病理学表现的异常。 深度学习在医学图像分析的很多领域已经得到了广泛的应用,比如,电脑辅助检测乳腺病变,电脑辅助诊断乳腺病变和肺结节,组织病理学诊断。这篇论文概述了在脑部磁共振图像分割的最好深度学习技术,并且讨论了通过使用深度学习技术仍然能够提高的距离。
二、创新点:
1.我们将论文分为两类:关于正常组织和脑损伤。这两组里不同的深度学习架构被介绍来处理领域内特定的问题。基于它们的架构风格,我们又进行了更细的分类:patch-wise, semantic-wise, or cascaded architectures。
2.当数据有限,就使用交叉验证方法。由于使用监督方法,需要标签。数据一般通过专家对脑部组织和病变区域分割认为标定。虽然这对于学习和评估是一个金标准,但非常繁琐和辛苦,还包含了主观性。对于手动分割脑肿瘤图像,国内专家有20 ± 15%的变化,国际专家有28 ± 12%的变化。为了减小这种变化,通过使用标签融合算法(STAPLE,Simultaneous truth and performance level estimation (STAPLE): An algorithm for the validation of image segmentation,A logarithmic opinion pool based STAPLE algorithm for the fusion of segmentations with associated reliability weights),多个专家的分割图像被以最佳的方式被结合。对于脑部损伤的分类任务,标定过的真实数据通过活检和病理检查来得到。
三、算法-CNN
一般地,CNN的基本结构包括两层:
1)特征提取层:每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来。
2)特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。

(a)A schematic representation of a convolutional neural network (CNN) training process
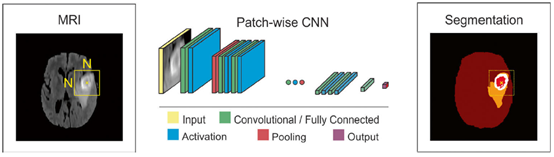
(b)Schematic illustration of a patch-wise CNN architecture for brain tumor segmentation task
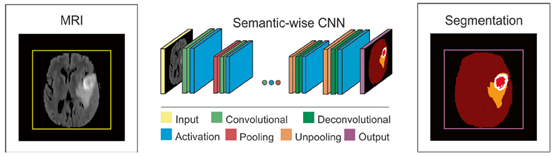
(c)Schematic illustration of a semantic-wise CNN architecture for brain tumor segmentation task
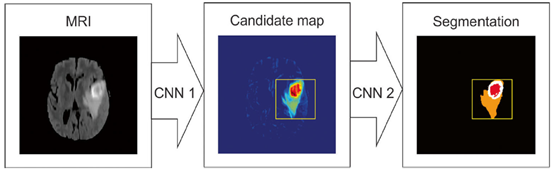
(d)Schematic illustration of a cascaded CNN architecture for brain tumor segmentation task,where the output of the first network (CNN 1) is used in addition to image data for a refined input to the second network (CNN2), which provides final segmentation
四、优缺点及改进
文献报道最新的方法表明,深度学习技术在定量脑部MRI图像分析中有巨大的潜能。虽然深度学习方法只是最近被用于脑部MRI,但看起来比先前最好的机器学习方法,变得越来越成熟。由于复杂的脑解剖和它表现的多样性,由于成像协议的不同而导致的非标准的MRI灰度,图像采集的缺陷,病理的存在,对于计算机辅助技术,脑图象分析一直是一个巨大的挑战。那么就需要像深度学习这样处理这些变异的更加泛化的技术。
尽管是一个有意义的突破,但深度学习的潜能仍然被限制,因为医学图像数据集相对小,这就限制了这种方法的能力,不能显示它的全部能力,这种能力已经在大的数据集上显示。尽管有作者报道他们的监督学习架构要求仅仅一个训练样本,但大多数作者报告他们的结果随着数据集的增加而稳定提高。对于深度学习方法的有效应用急需大规模的数据集。或者数据集的数量可以通过对原始数据的随机变换,比如抖动,旋转,变换,变形等来有效增加。机器学习算法中经常使用这种办法,被称为数据增强。数据增强帮助增加训练样本的个数,并且通过引入原始数据的随机变换来减小过拟合。多个研究报告数据增强在他们的研究中非常有用。
为了提高深度学习方法,一些步骤是非常重要的,包括,数据预处理,数据后处理,网络权重初始化,阻止过拟合。数据预处理扮演了一个关键角色,多重数据预处理已经被应用到最近的研究中。比如,使得输入脑部MR图像灰度在同一个参考比例,并且对对每种形态进行正则化。这避免了在输出模型中由于任何modality和灰度的不同而使得结构的真正pattern被抑制。模型输出的后处理对于精调分割结果非常重要。任何学习方法的目的是得到一个完美的预测,但是图像上总有一些区域会有不同类重叠,被称为部分体积效应,这不可避免的导致了假阳性或假阴性。这些区域要求额外的预处理来精确量化。另一个非常重要的步骤是神经网络合适的网络参数初始化,来保证整个网络的梯度流动,并且能够收敛。不然激活和梯度流动会消失,且导致不收敛和不学习。随机权重初始化已经被用到了大多数最近的研究中。最近,阻止过拟合对于学习图片中正确的信息非常关键,避免提供的特定的训练集过拟合。神经网络特别容易过拟合,因为参数太多,但训练数据有限。一些策略被用来阻止过拟合,比如,引入数据随机变化性来进行数据增强,使用dropout在训练中随机去掉网络节点,L1/L2正则化引入权重惩罚。
Semantic-wise架构接受任何大小的输入,生成分类映射而patch-wise CNN架构接受固定大小的输入,并且产生非空间输出。因此,semantic-wise架构对图像的每个像素产生预测结果比patch-wise架构更快。另一方面,相对于semantic-wise架构的全图训练,在一个数据集上对patches进行随机采样,潜在的促进更快的收敛。Semantic-wise架构易受类别不平衡影响,但这可以通过在损失函数中加权来解决。Cascaded架构,比如patch-wise架构加一个semantic架构,可以解决单独架构的问题,并且提高输出结果。
开发一种通用的深度学习方法,能够适用于从不同机器不同机构产生的数据仍然是一个挑战,原因是,有限的训练数据和有label的数据,图像采集协议的不同,每个MRI采集器的不完美,健康和病理脑组织的表现不同。到目前为止,现在可用的方法都是随机初始化,并且在有限数据集上训练。为了提高深度学习架构的一般化,我们可以采用一个表现好的深度学习网络,在一个大的数据集上训练,然后再一个小数据集上针对一个特定问题进行微调,这种方法被称为迁移学习。已经表明,将预训练的好的具有一般性网络的权重转移到新网络,然后在特定数据集上训练的效果比随机初始化网络权重要好。迁移学习的效果和能否成功依赖于数据集之间的相似性。比如,使用拿ImageNet训练的与训练模型,如果没有更深的训练,在医学图像上可能表现不好。Shin等人报告,他们已经使用拿ImageNet预训练的模型,使用迁移学习并通过在淋巴结和肺间质疾病微调,而不是从头开始训练,获得了最好的结果。另一方面,ImageNet数据集实质上与医学图像数据集非常不同,因此使用从ImageNet训练的迁移学习,对于医学图像来说也许不是最好的选择。
注:小编水平有限,翻译和理解不正确的地方,还请下方留言区批评指正。
- 点赞 1
- 收藏
- 分享
- 文章举报
 Mr.Ma-master
发布了55 篇原创文章 · 获赞 23 · 访问量 9967
私信
关注
Mr.Ma-master
发布了55 篇原创文章 · 获赞 23 · 访问量 9967
私信
关注

- 【论文阅读笔记】Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique
- 论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
- 【医学+深度论文:F11】2018 A deep learning model for the detection of both advanced and early glaucoma using
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H
- 论文笔记:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning --- 论文笔记
- [论文笔记] Xen and the art of virtualization (SOSP, 2003)
- State of the "Art": A Taxonomy of Artistic Stylization Techniques for Images and Video(五)
- 论文笔记之:Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic
- 【医学+深度论文:F08】2018 Performance of Deep Learning Architectures and Transfer Learning for Detecting
- [深度学习论文笔记][Weight Initialization] Exact solutions to the nonlinear dynamics of learning in deep lin
- 论文笔记 | Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- State of the "Art": A Taxonomy of Artistic Stylization Techniques for Images and Video(六)
- 【论文笔记】Active Convolution: Learning the Shape of Convolution for Image Classification
- 论文笔记之:Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic
- Theano-Deep Learning Tutorials 笔记:Modeling and generating sequences of polyphonic music with the RNN
- The Future of Real-Time SLAM and "Deep Learning vs SLAM" 深度学习与slam
- State of the "Art": A Taxonomy of Artistic Stylization Techniques for Images and Video(一)
- [论文笔记] Leveraging the crowd as a source of innovation Does crowdsourcing represent a new model for product and service innovation? (SIGMIS-CPR, 2012)
- Deep Learning for Design and Retr of Nano-photonic Structures 论文学习