CNN中input,output的计算推导
2019-07-22 22:29
106 查看
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/public669/article/details/96904410
最近在研究facebook推出的深度学习框架pytorch,在使用CNN对非常经典的MNIST数据集进行卷积运算时遇到了些问题,就是自己手动使用公式进行推导时,总是在最后一步的全连接层矩阵运算时出错

- 开始也是比较的郁闷,为什么按照Stanford University CS231n上介绍的运算公式总是推算不对呢
- 较劲的我又重新的返回来查看了这么一个非常简单的入门级别代码:
class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # 使用序列工具快速构建 self.conv1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5,stride=1, padding=2), nn.ReLU(), nn.MaxPool2d(2) ) self.conv2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5,stride=1,padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(2)) self.fc = nn.Linear(7*7*32, 10) def forward(self, x): out = self.conv1(x) out = self.conv2(out) out = out.view(out.size(0), -1) # reshape out = self.fc(out) return out
然后我又开始在验算纸继续按照公式又运算了一遍:
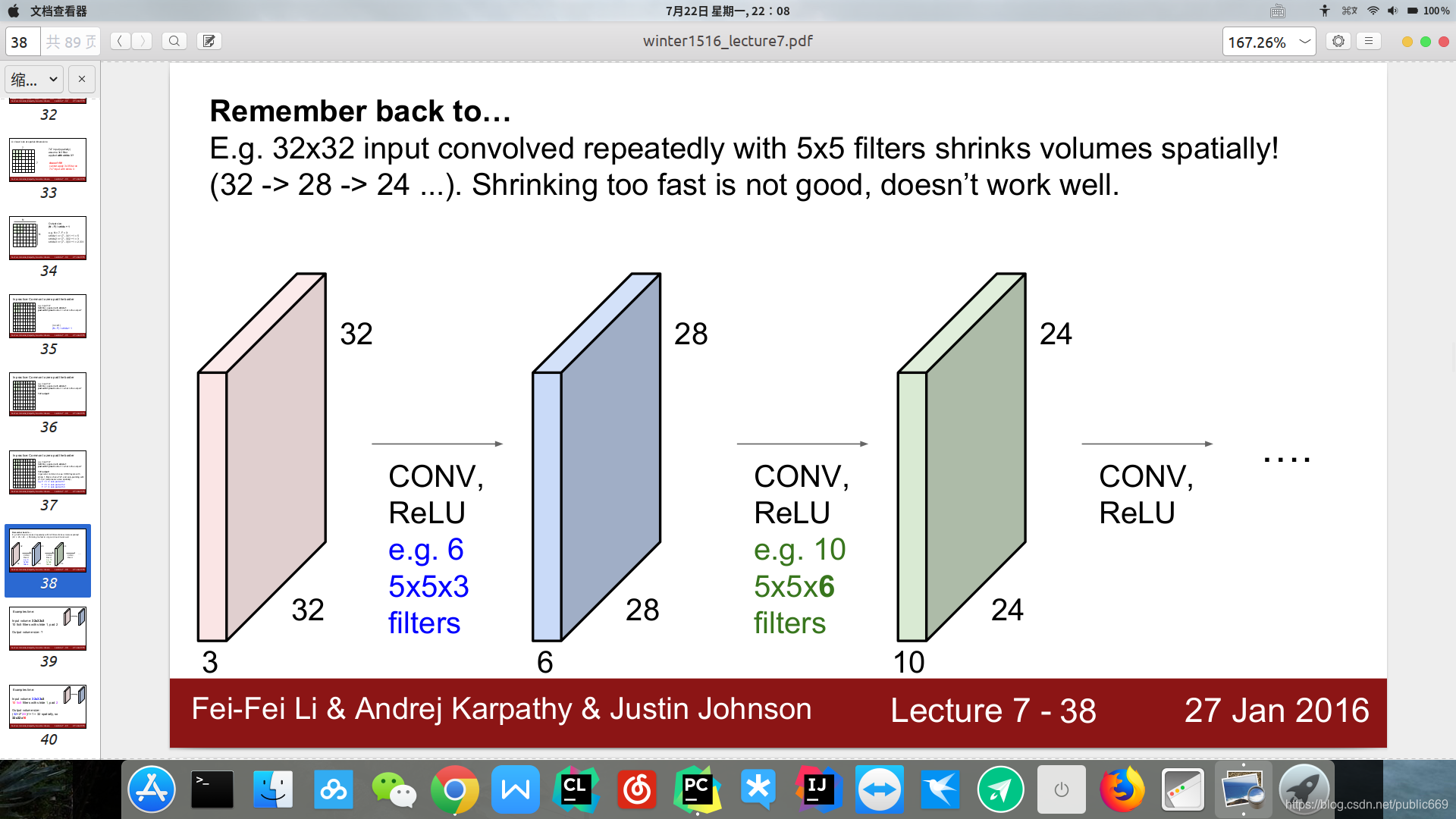


按照上面的代码公式可以总结为:
W(out)=[W(in)+2p-F]/S+1 H(out)=[H(in)+2p-F]/S+1
其中W(out),H(out)为输出维度,
W(in),H(in)为输入维度
p为padding
F为kernel_size
-
结合这上面的公式对MNIST数据集的一张图片进行手动运算,原图像的维度为28*28
计算:
进行着第一步卷积之后的图像[28+22-5]/1+1
可以看出此时的运算结果还为28 (可以自己的运算一遍进行验证) -
我们知道在进行卷积运算之后,是需要结合着pool的,也就是通常所说的池化,或者说降维,这里呢就介绍MaxPool
-
nn.MaxPool2d())
-
看这其中的参数,个人认为这就是对输出数据进行折半处理咱们第一步开始进行验证自己的猜测
如果猜测的正确的话,我们在进行四层卷积运算之后MNIST数据对应输出应该是 -
14x14x16
-
7x7x32
-
3x3x64
-
1x1x128
验证:
import torch
import torch.nn as nn
import torchvision
from torch import optim
import torchvision.datasets as normal_datasets
import torchvision.transforms as transforms
from torch.autograd import Variable
num_epochs = 5 # 批次
batch_size = 100 # 批次数据
learning_rate = 0.001 # 学习率
# 将数据处理成Variable, 如果有GPU, 可以转成cuda形式
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
# 从torchvision.datasets中加载一些常用数据集
train_dataset = normal_datasets.MNIST(
root='./MNIST_Model/', # 数据集保存路径
train=True, # 是否作为训练集
transform=transforms.ToTensor(), # 数据如何处理, 可以自己自定义
download=True) # 路径下没有的话, 可以下载
# 见数据加载器和batch
test_dataset = normal_datasets.MNIST(root='./MNIST_Model/',
train=False,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# 两层卷积
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 使用序列工具快速构建
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5,stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5,stride=1,padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv3=nn.Sequential(
nn.Conv2d(32,64,kernel_size=5,stride=1,padding=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv4=nn.Sequential(nn.Conv2d(64,128,kernel_size=5,stride=1,padding=2),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(1*1*128, 10)
def forward(self, x):
out = self.conv1(x)
print(out.shape)
out = self.conv2(out)
print(out.shape)
out=self.conv3(out)
print(out.shape)
out=self.conv4(out)
print(out.shape)
out = out.view(out.size(0), -1) # reshape
out = self.fc(out)
return out
cnn = CNN()
if torch.cuda.is_available():
cnn = cnn.cuda()
# 选择损失函数和优化方法
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = get_variable(images)
labels = get_variable(labels)
outputs = cnn(images)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f'
% (epoch + 1, num_epochs, i + 1, len(train_dataset) // batch_size, loss.item()))
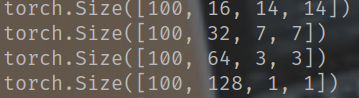
此时可以看到确实是我们猜想的那样
*总结:
上述都是个人理解,如有不正确的地方欢迎提出,一同进步

相关文章推荐
- 阶乘之和Description 输入n,计算S=1!+ 2!+…+ n!的末6位(不含前导0)。这里,n!表示前n个正整数之积。 Input 输入n,,n≤ 106。 Output 输出S的
- 关于set_input_delay和set_output_delay的选项-max和-min的存在意义和推导
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
- BP(反向传播)算法和CNN反向传播算法推导(转载)
- 10201 upgrade to 10205 Input/output error
- linux input output i/o重定向 bash算术运算
- C++——流的文件I/O(Input & Output)
- input/output
- andriod 内存数据读取 写入操作(openFileInput,openFileOutput)
- input和output实例
- (筆記) 如何設定Debussy / Verdi的input / output port顏色? (SOC) (Debussy) (Verdi)
- softmax 损失函数以及梯度推导计算
- IOPS :Input/Output Operations Per Second
- 【深度学习-CNN】CNN中的参数与计算量
- File Input and Output with R
- linux下出现architecture of input file `*.o' is incompatible with i386:x86-64 output的解决方法
- CNN在NLP领域的应用(2) 文本语义相似度计算
- CNN中各层图像大小的计算
- CNN中的卷积操作的参数数计算
- .NET中调用存储过程(Output、Input)