机器学习初级算法梳理[3]—决策树
任务3 - 决策树算法梳理
文章目录
1-信息论基础
1.1 基础概念
熵Ent :
度量随机变量的不确定性。
定义:假设随机变量X的可能取值有x1,x2,...,xnx_{1},x_{2},...,x_{n}x1,x2,...,xn,对于每一个可能的取值xix_{i}xi,其概率为P(X=xi)=pi,i=1,2...,nP(X=x_{i})=p_{i},i=1,2...,nP(X=xi)=pi,i=1,2...,n。随机变量的熵为:
H(X)=−∑i=1npilog2pi
H(X)=-\sum_{i=1}^{n}p_{i}log_{2}p_{i}
H(X)=−i=1∑npilog2pi
对于样本集合,假设样本有k个类别,每个类别的概率为∣Ck∣∣D∣\frac{|C_{k}|}{|D|}∣D∣∣Ck∣,其中 ∣Ck∣∣D∣{|C_{k}|}{|D|}∣Ck∣∣D∣为类别为k的样本个数,∣D∣|D|∣D∣为样本总数。样本集合D的熵为:
H(D)=−∑k=1k∣Ck∣∣D∣log2∣Ck∣∣D∣
H(D)=-\sum_{k=1}^{k}\frac{|C_{k}|}{|D|}log_{2}\frac{|C_{k}|}{|D|}
H(D)=−k=1∑k∣D∣∣Ck∣log2∣D∣∣Ck∣
联合熵:
如果XXX ,YYY是一对离散型随机变量,XXX ,Y~p(x,y)Y~p(x,y)Y~p(x,y),XXX ,YYY的联合熵$H(X,Y) $定义为
H(X,Y)=∑x∈X∑y∈Yp(x,y)logp(x,y)
H(X,Y) =\sum_{x\in X}^{}\sum_{y\in Y}^{}p(x,y)logp(x,y)
H(X,Y)=x∈X∑y∈Y∑p(x,y)logp(x,y)
联合熵描述一对随机变量平均所需的信息量。
条件熵 :
给定随机变量XXX,随机变量YYY的条件熵定义如下
H(X,Y)=∑x∈Xp(x)H(Y∣X=x)=∑x∈Xp(x)[−∑y∈Yp(y∣x)logp(y∣x)=−∑x∈X∑y∈Yp(x,y)logp(y∣x)
H(X,Y) =\sum_{x\in X}^{}p(x)H(Y|X=x)\\
=\sum_{x\in X}^{}p(x)[-\sum_{y\in Y}^{}p(y|x)logp(y|x)\\
=-\sum_{x\in X}^{}\sum_{y\in Y}^{}p(x,y)logp(y|x)
H(X,Y)=x∈X∑p(x)H(Y∣X=x)=x∈X∑p(x)[−y∈Y∑p(y∣x)logp(y∣x)=−x∈X∑y∈Y∑p(x,y)logp(y∣x)
信息增益Gain :
定义:以某特征划分数据集前后的熵的差值。
熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。 假设划分前样本集合D的熵为H(D)。使用某个特征A划分数据集D,计算划分后的数据子集的熵为H(D|A)。
则信息增益为:
g(D,A)=H(D)−H(D∣A)
g(D,A)=H(D)-H(D|A)
g(D,A)=H(D)−H(D∣A)
*注:*在决策树构建的过程中我们总是希望集合往最快到达纯度更高的子集合方向发展,因此我们总是选择使得信息增益最大的特征来划分当前数据集D。
思想:计算所有特征划分数据集D,得到多个特征划分数据集D的信息增益,从这些信息增益中选择最大的,因而当前结点的划分特征便是使信息增益最大的划分所使用的特征。
另外这里提一下信息增益比相关知识:
信息增益比=惩罚参数×信息增益信息增益比=惩罚参数\times信息增益信息增益比=惩罚参数×信息增益
信息增益比本质:在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
惩罚参数:数据集D以特征A作为随机变量的熵的倒数。
基尼指数(基尼不纯度Gini impurity):
分类问题中,假定当前样本集合 DDD 中第 kkk 类样本所占的比例为 pk(k=1,2,...,∣y∣)p_k(k =1,2,...,|y|)pk(k=1,2,...,∣y∣),则 DDD 的基尼值为
Gini(p)=∑k=1∣y∣∑k≠k′pkpk′=∑k=1∣y∣pk(1−pk)=1−∑k=1∣y∣pk2
\begin{aligned}
Gini(p) &=\sum_{k=1}^{|y|}\sum_{k\neq{k'}}{p_k}{p_{k'}}\\
&=\sum_{k=1}^{|y|}{p_k}{(1-p_k)} \\
&=1-\sum_{k=1}^{|y|}p_k^2
\end{aligned}
Gini(p)=k=1∑∣y∣k̸=k′∑pkpk′=k=1∑∣y∣pk(1−pk)=1−k=1∑∣y∣pk2
二分类问题,若样本点属于第一个类的概率为ppp,则概率分布的基尼指数为
Gini(p)=2p(1−p)
Gini(p) = 2p(1-p)
Gini(p)=2p(1−p)
表示样本集合中一个随机选中的样本被分错的概率,Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是集合的纯度越高。
样本集合D的Gini指数,假设集合中有K个类别,则
Gini(D)=1−∑k=1K(∣Ck∣∣D∣)2
Gini(D) = 1-\sum_{k=1}^{K}(\frac{|C_k|}{|D|})^2
Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
1.2 2.决策树的不同分类算法
决策树(Decision Tree)是一种分而治之的决策过程,基本的分类与回归的方法。
决策树模型是描述对样本进行分类的塑形结构,将一个困难的预测问题,通过树的分支节点,被划分成两个或多个较为简单的子集,从结构上划分为不同的子问题。内部结点表示一个特征或者属性,叶子结点表示一个分类,有向边代表了一个划分规则。
将依规则分割数据集的过程不断递归下去(Recursive Partitioning)。随着树的深度不断增加,分支节点的子集越来越小,所需要提的问题数也逐渐简化。当分支节点的深度或者问题的简单程度满足一定的停止规则(Stopping Rule)时, 该分支节点会停止分裂,此为自上而下的停止阈值(Cutoff Threshold)法;有些决策树也使用自下而上的剪枝(Pruning)法。
优点:可读性强,分类速度快
决策树学习通常包含三个步骤:特征选择,决策树生成,决策树剪枝。
决策树常用的生成算法:
- ID3:选择信息熵增益最大的feature作为node,实现对数据的归纳分类。
- C4.5:是ID3的一个改进,比ID3准确率高且快,可以处理连续值和有缺失值的feature。
- CART:使用基尼指数的划分准则,通过在每个步骤最大限度降低不纯洁度,CART能够处理孤立点以及能够对空缺值进行处理。
ID3生成算法
- ID3生成算法核心是在决策树的每个结点上应用信息赠一准则选择特征,递归的构建决策树。
-
从根结点开始,计算所有结点可能的特征的信息增益,选择信息增益最大的特征为结点的特征,由该特征划分出子结点。
- 再对子结点递归的调用以上方法,构建决策树。
- 知道所有特征的信息增益均很小或者没有特征可以选择为止,最后得到一个决策树。如果不设置特征信息增益的下限,则可能会使得每个叶子都只有一个样本点,从而划分得太细。
- ID3生成算法:
-
输入:
训练数据集D\mathbb{D}D
- 特征集合A=A1,A2,…,An\mathbb{A} = {A_1,A_2,…,A_n}A=A1,A2,…,An
- 特征信息增益阈值:ε>0\varepsilon > 0ε>0
- 输出:决策树TTT
- 算法步骤:
-
若D\mathbb{D}D中所有样本均属于同一类 ckc_kck,则TTT为单结点树,并将ckc_kck作为该结点的类标记,算法终止。
- 若A=ϕ\mathbb{A}=\phiA=ϕ,则TTT为单结点树,将D\mathbb{D}D中样本数最大的类ckc_kck作为该结点的类标记,算法终止。
- 否则计算g(D,Aj),j=1,2,…,ng(\mathbb{D},A_j),j=1,2,…,ng(D,Aj),j=1,2,…,n ,选择信息增益最大的特征AgA_gAg : 若 g(D,Aj)<εg(\mathbb{D},A_j)<\varepsilong(D,Aj)<ε ,则置TTT为单结点树,将D\mathbb{D}D中样本数最大的类ckc_kck作为该结点的类标记,算法终止
- 若g(D,Aj)≥εg(\mathbb{D},A_j)\geq \varepsilong(D,Aj)≥ε ,则对AgA_gAg特征的每个可能取之ai,i=1,2,…,nga_i,i=1,2,…,n_gai,i=1,2,…,ng,根据Ag=aiA_g=a_iAg=ai将D\mathbb{D}D划分为若干个非空子集DiD_iDi,
- 对第iii个子结点,以DiD_iDi为训练集,以A−Ag\mathbb{A}-{A_g}A−Ag为特征集,递归地调用前面的步骤来构建子树。
C4.5
C4.5生成算法与ID3算法相似,但是C4.5算法在生成过程中用信息增益比来选择特征。
CART分类树
-
CART:classification and regression tree,学习在给定输入随机变量x的条件下,输出随机变量y的条件概率分布的模型。特征选择+书的生成+剪枝。既可用于回归,也可用于分类。
-
CART假设决策树是二叉树:
-
内部结点特征的取值为是 or 否。左侧分支为 是, 右侧分支为 否。
- 递归的二分每个特征,将输入空间划分成为有限个单元。
-
CART树与ID3决策树和C4.5决策树的重要区别:
-
CART树是二叉树,后两者为N叉树。CART树的拆分不依赖于特征的取值数量。因此CART树也不想ID3那样倾向于取值数量较多的特征。
- CART树的特征可以是离散的,也可以是连续的,后两者的特征是离散的。如果是连续特征,需要执行分桶来进行离散化。
-
CART算法分两步
-
决策树生成:用训练数据生成尽可能大的决策树
- 决策树剪枝:用验证数据基于损失韩素最小化的标准生成的决策树剪枝
-
具体过程如下:
从根节点开始,对节点计算现有特征的基尼指数,对每一个特征,例如AAA,再对其每个可能的取值如aaa,根据样本点对A=aA=aA=a的结果的”是“与”否“划分为两个部分,利用
Gini(D,A=a)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2) Gini(D,A=a)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) Gini(D,A=a)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
进行计算; -
在所有可能的特征AAA以及该特征所有的可能取值aaa中,选择基尼指数最小的特征及其对应的取值作为最优特征和最优切分点。然后根据最优特征和最优切分点,将本节点的数据集二分,生成两个子节点
-
对两个字节点递归地调用上述步骤,直至节点中的样本个数小于阈值,或者样本集的基尼指数小于阈值,或者没有更多特征后停止;
-
生成CART分类树;
2-回归树原理
回归树是可以用于回归的决策树模型,一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值.与分类树不同的是,回归树对输入空间的划分采用一种启发式的方法,会遍历所有输入变量,找到最优的切分变量jjj和最优的切分点sss,即选择第jjj个特征xjx_jxj和它的取值sss将输入空间划分为两部分,然后重复这个操作。
而如何找到最优的jjj和sss是通过比较不同的划分的误差来得到的。一个输入空间的划分的误差是用真实值和划分区域的预测值的最小二乘来衡量的,即
∑xi∈RM(yi−f(xi))2
\sum_{x_i \in R_M}(y_i-f(x_i))^2
xi∈RM∑(yi−f(xi))2
其中,f(xi)f(x_i)f(xi)是每个划分单元的预测值,这个预测值是该单元内每个样本点的值的均值,即
f(xi)=cm=ave(yi∣xi∈Rm)
f(x_i)=c_m=ave(y_i|x_i\in R_m)
f(xi)=cm=ave(yi∣xi∈Rm)
将空间划分成MMM个单元R1,R2,…,RmR_1,R_2,…,R_mR1,R2,…,Rm
j和s的求解可以用下式进行
minj,s[minC1∑xi∈R1(j,s)(yi−ci)2+minc2∑xi∈R2(j,s)(yi−c2)2]
min_j,s[min_{C1}\sum_{x_i \in R_1(j,s)}(y_i-c_i)^2 + min_{c2}\sum_{x_i \in R_2(j,s)}(y_i-c_2)^2]
minj,s[minC1xi∈R1(j,s)∑(yi−ci)2+minc2xi∈R2(j,s)∑(yi−c2)2]
其中,R1(j,x)=x∣xj≥sR_1(j,x)={x|x^j \geq s}R1(j,x)=x∣xj≥s和R2(j,s)=x∣xj>sR_2(j,s) = {x|x^j>s}R2(j,s)=x∣xj>s是被划分后的两个区域
-
选择最优的切分变量jj和最优的切分点ss,求解
minj,s[minC1∑xi∈R1(j,s)(yi−ci)2+minc2∑xi∈R2(j,s)(yi−c2)2] min_j,s[min_{C1}\sum_{x_i \in R_1(j,s)}(y_i-c_i)^2 + min_{c2}\sum_{x_i \in R_2(j,s)}(y_i-c_2)^2] minj,s[minC1xi∈R1(j,s)∑(yi−ci)2+minc2xi∈R2(j,s)∑(yi−c2)2]
遍历所有特征,对固定的特征扫描所有取值,找到使上式达到最小值的对(j,s)(j,s)(j,s)(j,s). -
用选定的对 (j,s)(j,s)(j,s)划分区域,并确定该区域的预测值;
-
继续对两个字区域调用上述步骤,直至满足停止条件;
-
生成回归树;
3-决策树防止过拟合手段
剪枝处理是决策树学习算法用来解决过拟合问题的一种办法。决策树的剪枝是学习整体的模型。即:生成算法仅考虑局部最优,而剪枝算法考虑全局最优。
在决策树算法中,为了尽可能正确分类训练样本, 节点划分过程不断重复, 有时候会造成决策树分支过多,以至于将训练样本集自身特点当作泛化特点, 而导致过拟合。 因此可以采用剪枝处理来去掉一些分支来降低过拟合的风险。 剪枝的依据:最小化决策树的整体损失函数或者代价函数。
剪枝的基本策略有预剪枝(pre-pruning)和后剪枝(post-pruning)。
预剪枝:在决策树生成过程中,在每个节点划分前先估计其划分后的泛化性能, 如果不能提升,则停止划分,将当前节点标记为叶结点。
后剪枝:生成决策树以后,再自下而上对非叶结点进行考察, 若将此节点标记为叶结点可以带来泛化性能提升,则修改之。
剪枝算法:
从已生成的树上裁掉一些子树或者叶结点,并将根结点或者其父结点作为新的叶结点。
- 输入: 生成算法产生的决策树T,
- 参数alpha
-
对树T每个结点Tt,t=1,2,..∣Tf∣T_t, t=1,2,..|T_f|Tt,t=1,2,..∣Tf∣,计算器经验熵H(t)H(t)H(t)
4-模型评估
4.1自助法(bootstrap):
训练集是对于原数据集的有放回抽样,如果原始数据集NNN,可以证明,大小为NNN的自助样本大约包含原数据63.2%的记录。当NNN充分大的时候,1−(1−1N)N)1-(1-\frac{1}{N})^N)1−(1−N1)N) 概率逼近 1−e−1=0.6321-e^{-1}=0.6321−e−1=0.632。抽样 b 次,产生 b 个bootstrap样本,则总准确率为(accs为包含所有样本计算的准确率):
accboot=1b∑i=1b(0.632×εi+0.368×accs)
acc_{boot}=\frac{1}{b}\sum_{i=1}{b}(0.632×\varepsilon_i+0.368×acc_s)
accboot=b1i=1∑b(0.632×εi+0.368×accs)
4.2准确度的区间估计:
将分类问题看做二项分布,则有:
令XXX为模型正确分类,ppp为准确率,XXX 服从均值 NpNpNp、方差 Np(1−p)Np(1-p)Np(1−p)的二项分布。acc=X/Nacc=X/Nacc=X/N为均值 p,方差 p(1−p)/Np(1-p)/Np(1−p)/N 的二项分布。acc 的置信区间:
P(−Zα2≤acc−pp(1−p)/N≤Z1−α2
P(−Z_{\frac{α}{2}} \leq \frac{acc−p}{\sqrt{p(1-p)/N} \leq Z_{1-\frac{\alpha}{2}}}
P(−Z2α≤p(1−p)/N≤Z1−2αacc−p
P∈2∗N∗acc+Zα22±Zα2Zα22+4∗N∗acc−4∗N∗acc22(N+Zα22) P \in{\frac{2*N*acc+Z_{\frac{\alpha}{2}}^{2}±Z_{\frac{\alpha}{2}}\sqrt{Z_{\frac{\alpha}{2}}^{2}+4*N*acc-4*N*acc^2}}{2(N+Z_{\frac{\alpha}{2}}^{2})}} P∈2(N+Z2α2)2∗N∗acc+Z2α2±Z2αZ2α2+4∗N∗acc−4∗N∗acc2
5-sklearn参数详解,Python绘制决策树
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。两者的参数定义几乎完全相同,但是意义不全相同。下面就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做一个总结,重点比较两者参数使用的不同点和调参的注意点。
5.1参数:
-
特征选择标准criterion;
DecisionTreeClassifier分类树:gini代表基尼系数;entropy:代表信息增益。一般说使用默认的基尼系数,即CART算法。 - DecisionTreeRegressor回归树:“mse"均方差;“mae”:和均值之差的绝对值之和。默认的"mse”。
特征划分点选择标准splitter:“best”:默认,特征的所有划分点中找出最优的划分点,适合样本量不大的时候;“random”:随机的在部分划分点中找局部最优的划分点,样本数据量非常大,推荐"random"
划分时考虑的最大特征数max_features:可以使用很多种类型的值,默认是"None",意味着划分时考虑所有的特征数;如果是"log2log2log2"意味着划分时最多考虑log2Nlog2Nlog2N个特征;如果是"sqrt"或者"auto"意味着划分时最多考虑N−−√N个特征。如果是整数,代表考虑的特征绝对数。如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中N为样本总特征数。
一般来说,如果样本特征数不多,比如小于50,我们用默认的"None"就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。
决策树最大深max_depth:决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
内部节点再划分所需最小样本数min_samples_split:这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
叶子节点最少样本数min_samples_leaf:这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。
叶子节点最小的样本权重和min_weight_fraction_leaf:这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
最大叶子节点数max_leaf_nodes:通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
类别权重class_weight:
-
指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的"None"
节点划分最小不纯度min_impurity_split:这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。
数据是否预排序presort:这个值是布尔值,默认是False不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为true可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。
5.2python绘制决策树
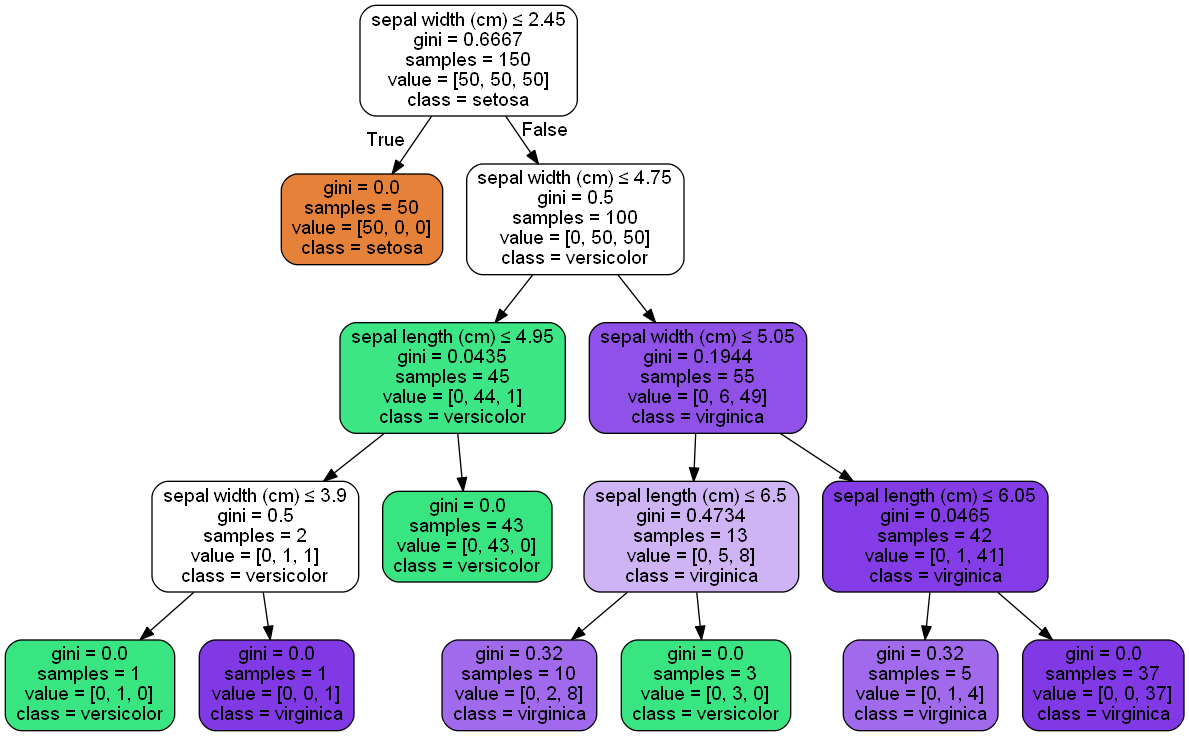
from itertools import product import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.tree import DecisionTreeClassifier # 仍然使用自带的iris数据 iris = datasets.load_iris() X = iris.data[:, [0, 2]] y = iris.target # 训练模型,限制树的最大深度4 clf = DecisionTreeClassifier(max_depth=4) #拟合模型 clf.fit(X, y) # 画图 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1)) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.contourf(xx, yy, Z, alpha=0.4) plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8) plt.show()
决策树可视化的三种方法:
-
第一种是用graphviz的dot命令生成决策树的可视化文件,敲完这个命令后当前目录就可以看到决策树的可视化文件iris.pdf.打开可以看到决策树的模型图。
-
第二种方法是用
pydotplus
生成iris.pdf。这样就不用再命令行去专门生成pdf文件了。 -
第三种办法直接把图产生在ipython的notebook。
-
from IPython.display import Image from sklearn import tree import pydotplus dot_data = tree.export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data) Image(graph.create_png())
图片来自网络;

- 机器学习初级算法梳理(三):决策树
- 机器学习初级算法梳理二
- 机器学习—线性回归—初级算法梳理01
- 机器学习初级算法梳理一
- 机器学习初级算法梳理(二):逻辑回归
- 机器学习初级算法梳理(三)
- #机器学习初级算法梳理(一)
- 2python机器学习--SVM(决策树分类算法)
- 初级算法梳理课程___第一次学习笔记
- 算法梳理三:决策树
- 机器学习经典算法-决策树学习之ID3算法
- 机器学习-决策树与集成算法
- [Java][机器学习]用决策树分类算法对Iris花数据集进行处理
- 机器学习 之 决策树(Decision Tree)文本算法的精确率
- 用Python开始机器学习(2:决策树分类算法)
- 初级算法梳理
- 机器学习经典算法详解及Python实现--决策树(Decision Tree)
- 算法梳理(三)决策树
- DNS通道检测 国内学术界研究情况——研究方法:基于特征或者流量,使用机器学习决策树分类算法居多
- 机器学习(5)——决策树(下)算法实现