初级算法梳理
初级算法梳理
一·、有监督学习:需要利用训练数据集学习一个模型,训练数据集往往是人工给的,在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子
无监督学习:我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构,在无监督学习中给定的数据没有任何标签或者说只有同一种标签
泛化能力:泛化能力是指学习方法对未知数据的预测能力
过拟合:一味追求对训练数据的预测能力,所选模型复杂度会高,这种现象称为“过拟合”,这种情况下参数过多,结果可能出现对训练数据集预测好,对未知数据集预测差
解决办法:1)减少特征的数量 2)正则化
欠拟合:模型没有很好的抓住数据集中的特征,训练偏差也交大
解决办法:1)添加其他特征项
交叉验证:(针对实际情况中数据不充足的情况下)
基本思想:重复使用数据,把给定的数据进行切分,将切分的数据集分为训练集和测试集,在此基础上反复进行训练,测试和模型的选择
简单交叉验证
70%数据为训练集,30%为测试集,然后在不同参数个数情况下求解模型,然后利用测试集选择最优的模型
S折交叉验证
方法如下:将数据切分为S个互不相交的大小相同的子集,利用S-1个子集数据训练模型,1个子集测试模型,将这个过程重复S次不同选择,最后选出S次平均测试误差最小的模型
留一交叉验证
也是分为S组,但每组只有一个数据点
二、线性回归的原理
假设模型为线性模型

通过使预测与真实数之间的平方差最小,找到参数的最有取值
三、线性回归的函数定义
损失函数:样本模型真实值与预测值的误差,

损失函数越小,说明拟合越好,并且损失函数是定义在单个样本上的,算的一个样本的误差

代价函数:是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均
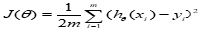
目标函数:最优化经验风险和结构风险,同时保证模型拟合效果好和避免过拟合
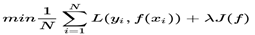
四优化方法
梯度下降法是求解无约束最优化问题的一种最常见方法,它是迭代算法,每一步需要求解目标函数的梯度向量。梯度下降法需要选择一个适当的初值,然后不断更新x值,更新x需要确定步长和函数在目前此点的负梯度方向。
牛顿法是求解无约束最优化问题的常用方法,有收敛速度快的优点,也属于迭代算法,每一步需要求解目标函数的海塞矩阵的逆矩阵,
拟牛顿法通过正定矩阵近似海塞矩阵的逆矩阵或海塞矩阵简化了计算
五:线性回归的评估标准(性能度量反映了任务需求,不同的性能度量方法导致不同的模型评价)
均方误差
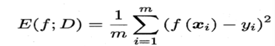
均方根误差
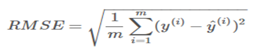
绝对平均误差
在这里插入图片描述
六.sklearn 参数
Class sklearn.linear_model.LinearRegression(fit.intercept=True,nomalize=False,copy_x=True,n_jobs=None) (关于线性回归的参数)
Fit_intecept:Boolean,optional,default True
是否计算此模型的截距,如果设置为False,则不使用截距。
Normalize:boolean,optional,default
True
当为True的时候,则回归量X将在回归之前通过减去平均值并除以I2范数来归一
Copy_x:Boolean ,optional,default True
如果设置为True,则将复制X,否则它可能被覆盖
n_jobs : int or None, optional(default=None)
多线程计算,-1表示使用所有核心进行计算,默认为1

- Datawhale-初级算法梳理-Day2-逻辑回归算法梳理
- 初级算法梳理任务2打卡
- Datawhale-初级算法梳理-Day1-线性回归算法梳理
- 初级算法梳理 任务一 线性回归算法梳理
- Datawhale 初级算法梳理 - 线性回归算法梳理
- 第六期-初级算法梳理-任务一 线性回归算法梳理
- LeetCode初级算法-字符串-2
- [leetcode]初级算法——链表
- 初级C语言算法实现分解质因数
- 初级算法整理,十进制转二进制的递归算法
- Leetcode 初级算法 字符串 C语言解答
- 算法初级_1:字符
- 基于OPL结合cutstock案例梳理Column Generation 算法
- 数据挖掘算法之时间序列算法(平稳时间序列模型,AR(p),MA(q),(平稳时间序列模型,AR(p),MA(q),ARMA(p,q)模型和非平稳时间序列模型,ARIMA(p,d,q)模型)学习笔记梳理
- 算法梳理——线性回归
- 逻辑回归算法梳理
- 机器学习-算法工程师 -面试/笔试准备-重要知识点梳理
- [转载] 机器学习面试之算法思想简单梳理
- 算法初级02——荷兰国旗问题、随机快速排序、堆排序、桶排序、相邻两数的最大差值问题、工程中的综合排序算法
- LeetCode(初级算法)数组篇--旋转数组c++