Python爬虫-Scrapy框架(三)- 爬虫数据入库
Python爬虫-Scrapy框架(三)- 爬虫数据入库
写在前面
之前,我们已经获取到了想要爬取的数据,现在想要将其存储在数据库中,在这里选择SQLite数据库。这一部分主要是爬虫数据入库的内容。这里的内容承接上一篇文章。
爬虫数据入库
创建数据库
这里选择ipython作为交互式命令工具,其相比于python自带的交互式命令模式使用更加方便。打开PyCharm中的Terminal终端,通过命令 ipython 进入ipython工具。
成功进入之后,首先导入SQLite。
In [1]: import sqlite3
接下来连接数据库,如果这里要连接的数据库名称不存在,则会自动创建该数据库。
In [2]: blog = sqlite3.connect(“blog.sqlite”)
数据应该被保存在数据库的表格中,接下来在数据库中创建表格,同样采用sqlite命令。
In [3]: create_table = “create table blog (num varchar(128))”
现在直接通过sqlite语言命令执行刚才建立的命令。
In [4]: blog.execute(create_table)
提示cursor。
Out[4]: <sqlite3.Cursor at 0x268536ee730>
最后通过命令 exit 断开。在工程文件里会出现sqlite文件,将其拖动至Database工作区,可以打开该sqlite文件。

稍等一段时间后,可以找到已经创建好的数据库以及数据库中的num表格。

SQLite显示异常处理
在新安装的PyCharm中可能会出现一种异常,将新建好的blog.sqlite拖动到Database打开后会发现名字下面出现波浪线,显然这是一个错误提示。点击下拉按钮,发现其中并没有出现刚刚创建的表格,这是由于我们需要下载一些东西来支持SQLite。

这里我们并不需要自己去寻找缺失的文件,可以采用这种方式直接安装。点击新建按钮,在选项中选择SQLite。

这里会发现在左下角出现了感叹号,提示missing driver files,我们直接点击Download,待下载完成时,点击Apply,会发现波浪线消失,同时我们也可以在下属目录中找到创建好的blog。

启用管道文件
之前我们在csdn_sun.py爬虫文件中编写的爬虫只是用来获得数据,并不能完成将获得的数据存入到数据库中的工作。所有获得的数据是在pipelines.py管道文件中进行清理和入库工作,接下来开始设置爬虫管道启用以及添加到整个爬虫工程中。
打开pipelines.py文件,找到类名,此处为CsdnSunPipeline。
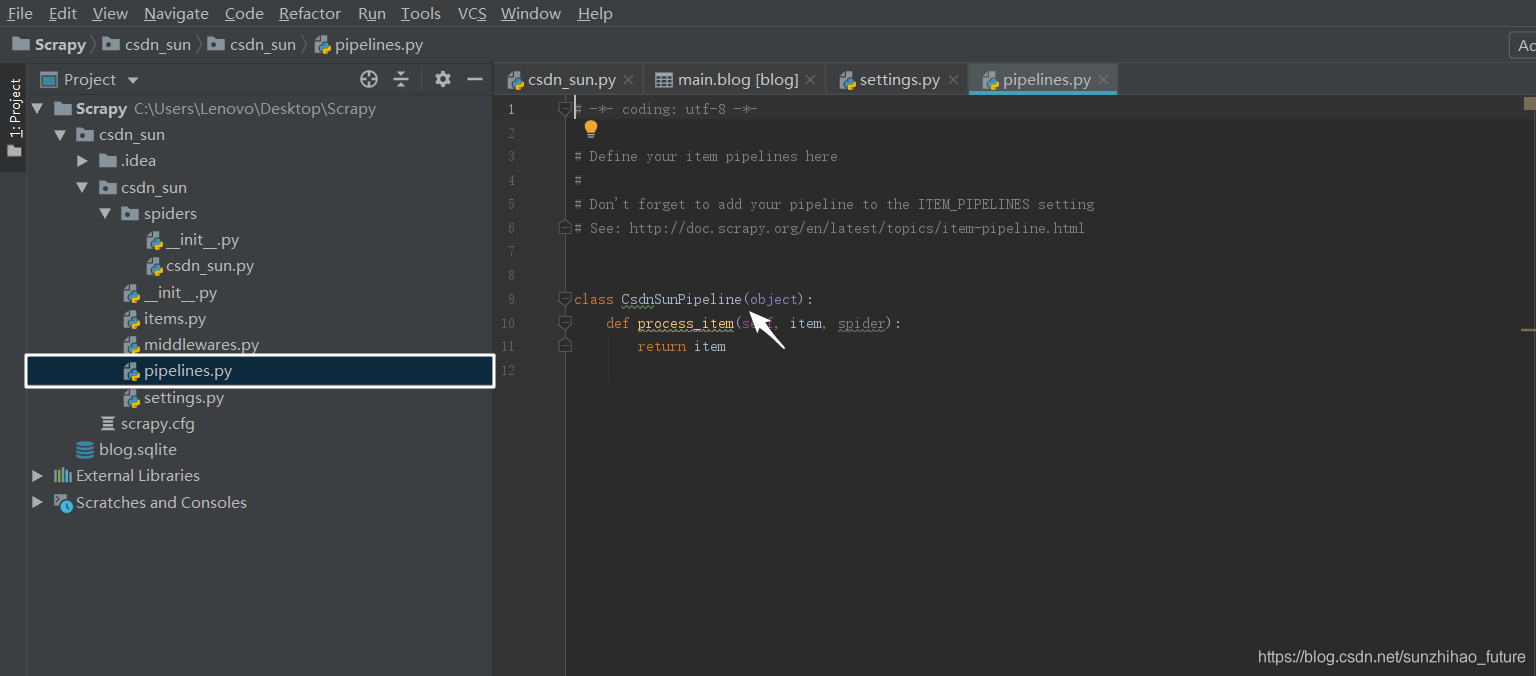
打开settings.py文件,找到ITEM_PIPELINES,将其取消注释,并检查其中的类名是否替换为刚才在管道文件中确定的类名CsdnSunPipeline,修改后的代码如下。
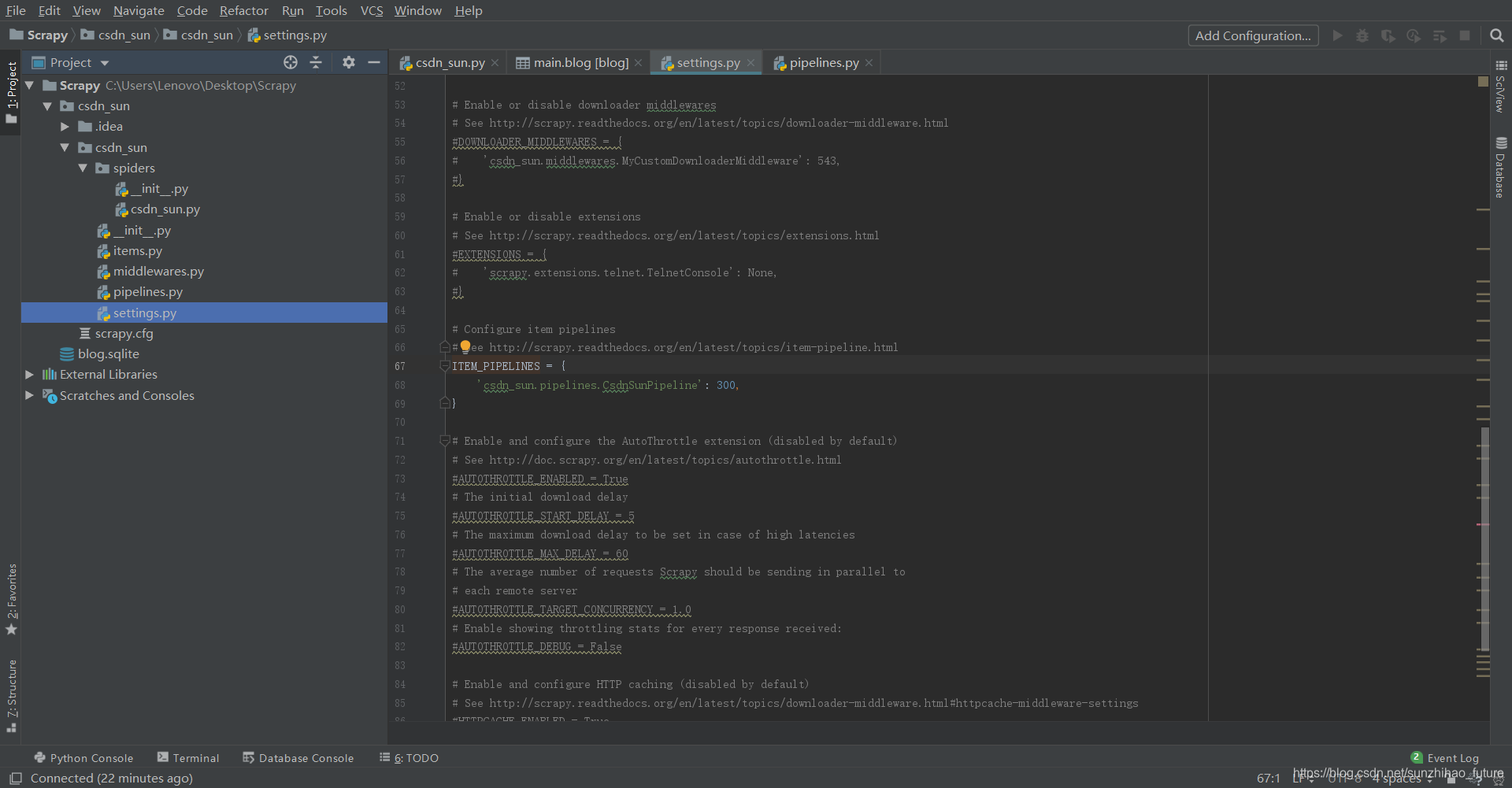
ITEM_PIPELINES = {
'csdn_sun.pipelines.CsdnSunPipeline': 300,
}
我们如何连接爬虫文件与管道文件呢? 在Scrapy框架中,我们必须通过items.py文件中的类,才可以将爬虫文件与管道文件连接起来实现相应功能,因此在这里要修改items.py文件以及之前的csdn_sun.py文件。
在items.py文件中修改CsdnSunItem类,代码如下。
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class CsdnSunItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() num = scrapy.Field() # pass
在csdn_sun.py文件中导入CsdnSunItem,创建一个类的实例,将获取的数据赋值给该实例,代码如下。
import scrapy
from ..items import CsdnSunItem
class BlogSpider(scrapy.Spider):
name = "blog"
start_urls = ['https://blog.csdn.net/sunzhihao_future']
def parse(self, response):
print(response)
csdn = CsdnSunItem()
num_list = response.xpath("/html/body[@class='nodata ']/div[@id='mainBox']/main"
"/div[@class='article-list']/div[@class='article-item-box csdn-tracking-statistics']"
"/div[@class='info-box d-flex align-content-center']/p[3]"
"/span[@class='read-num']/span[@class='num']/text()").extract()
for i in num_list:
csdn['num'] = i
yield csdn
# print(i)
数据入库
接下来继续添加代码,实现将管道文件中数据存储至数据库的这一部分功能。
打开pipelines.py管道文件,导入sqlite3,随后添加以下函数:
open_spider - 爬虫启动时执行该函数,将管道文件连接SQLite数据库。
spider_close - 爬虫结束时执行该函数,关闭数据库。
接下来修改以下函数:
process_item - 该函数将爬虫获得的数据,即在items.py文件中的item调入到管道文件中。这里首先定义插入语句,将数据插入到表格;采用execute语句来执行insert_sql命令。此外,数据库的插入和更新操作后需要提交操作。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import sqlite3
class CsdnSunPipeline(object):
def open_spider(self, spider):
self.con = sqlite3.connect("blog.sqlite")
self.cu = self.con.cursor()
def process_item(self, item, spider):
print(spider.name, 'pipelines')
insert_sql = "insert into blog (num) values ('{}')".format(item['num'], "
1c140
")
print(insert_sql)
self.cu.execute(insert_sql)
self.con.commit()
return item
def spider_close(self, spider):
self.con.close()
问题与解决
关闭整个项目,重新打开项目文件时,打开Terminal终端通过scrapy crawl blog执行爬虫时报错如下:
C:\Users\Lenovo\Desktop>scrapy crawl blog
Scrapy 1.4.0 - no active project
Unknown command: crawl
Use “scrapy” to see available commands
这里通常是因为目录位置错误,可以通过cd命令前往爬虫项目所在的文件夹,以此处为例,即进入C:\Users\Lenovo\Desktop\Scrapy\csdn_sun根目录后,重新执行命令,即可解决此报错。

到这里,已经简单的接触到了数据库的内容,同时对于一些管道文件中的代码的掌握还不够,相信会在后面的学习中不断深入理解。接下来将进入内置爬虫类型的学习。

- Python爬虫框架Scrapy之爬取糗事百科大量段子数据
- 数据可视化 三步走(一):数据采集与存储,利用python爬虫框架scrapy爬取网络数据并存储
- Python爬虫scrapy框架爬取动态网站——scrapy与selenium结合爬取数据
- Python爬虫框架Scrapy实战之抓取户外数据
- Python数据分析:爬虫框架scrapy基础知识点
- 使用python scrapy爬虫框架 爬取科学网自然科学基金数据
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
- python爬虫框架scrapy学习笔记
- Python3环境安装Scrapy爬虫框架过程及常见错误
- Scrapy(一):Python的爬虫框架
- Python网络爬虫框架scrapy的学习
- 基于Python使用scrapy-redis框架实现分布式爬虫 注
- Python3环境安装Scrapy爬虫框架过程及常见错误
- python从零开始写爬虫(5)-- 数据入库
- Python爬虫 --- 2.3 Scrapy 框架的简单使用
- Python3环境安装Scrapy爬虫框架过程及常见错误
- 利用python scrapy 框架抓取豆瓣小组数据
- [Python]网络爬虫(12):爬虫框架Scrapy的第一个爬虫示例入门教程
- python爬虫框架scrapy实例详解
- Python爬虫进阶三之Scrapy框架安装配置