机器学习之朴素贝叶斯: sklearn.naive_bayes
朴素贝叶斯: sklearn.naive_bayes
1. 贝叶斯原理
贝叶斯分类是以贝叶斯定理为基础的一种分类算法。
已知某条件概率,如何得到事件交换后的概率;即在已知P(A|B)的情况下求得P(B|A)。条件概率P(A|B)表示事件B已经发生的前提下,事件A发生的概率。其基本求解公式为:P(A|B)=P(AB)/P(B)。贝叶斯定理:
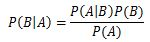
贝叶斯的主要思想可以概括为:先验概率+数据=后验概率。贝叶斯定理换个表达形式:
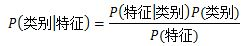
对于给定训练集,首先基于特征条件独立性的假设,学习输入/输出联合概率(计算出先验概率 和条件概率 ,然后求出联合概率 。然后基于此模型,给定输入x,利用贝叶斯概率定理求出最大的后验概率作为输出y。
例如:一个事物具有很多属性(features),把它的众多属性看作一个向量X,即X=(x1,x2,x3,…,xn),称为属性集。事物的类别(labels)也有很多种,用集合C={c1,c2,…cm}表示。一般X和C的关系是不确定的,可以将X和C看作是随机变量,P(C|X)称为C的后验概率,与之相对的,P( C)称为C的先验概率。
根据贝叶斯公式,后验概率P(C|X)=P(X|C)P( C)/P(X),计算后验概率时可以巧妙利用以下几点:
- 在比较不同C值的后验概率时,分母P(X)总是常数,忽略掉,即是后验概率P(C|X)=P(X|C)P©,
- 先验概率P©可以通过计算训练集中属于每一个类的训练样本所占的比例,
- 难度在于**条件概率P(X|C)**的估计
【针对朴素贝叶斯,因为朴素贝叶斯假设事物属性之间相互条件独立,P(X|C)=∏P(xi|ci)。】
2. 朴素贝叶斯
朴素贝叶斯分类是贝叶斯分类中最简单最常见的一种。它是基于贝叶斯定理和特征条件独立假设分类方法。朴素贝叶斯的含义是:朴素——特征条件独立,贝叶斯——基于贝叶斯定理。

3. 朴素贝叶斯模型:
朴素贝叶斯分类器是一种有监督学习,常见有两种模型,多项式模型即为词频型和伯努利模型即文档型,还有一种高斯模型。
3.1 多项式模型MultinomialNB
当特征是离散的时候,使用多项式模型。多项式模型在计算先验概率和条件概率时,会做一些平滑处理。
如果不做平滑,当某一维特征的值xi没在训练样本中出现过时,会导致条件概率为0,从而导致后验概率为0,加上平滑后可以克服这个问题。
3.2 高斯模型GaussianNB
当特征是连续变量的时候,运用多项式模型会导致很多条件概率为0。 以处理连续的特征变量,应该采用高斯模型。
3.3 伯努利模型BernoulliNB
伯努利模型适用于离散特征的情况,不同的是,伯努利模型中每个特征的取值只能是0和1。
伯努利模型中,条件概率的计算方式是:
当特征值xi=1时,P(xi∣ci)=P(xi=1∣ci)P(x_i|c_i)=P(x_i=1|c_i)P(xi∣ci)=P(xi=1∣ci)
当特征值xi=0时,P(xi∣ci)=1−P(xi=1∣ci)P(x_i|c_i)=1-P(x_i=1|c_i)P(xi∣ci)=1−P(xi=1∣ci)
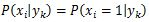
当特征值xi=0时,
4. sklearn 实现 朴素贝叶斯分类

基于Cnews 数据集,跑了一下,准确率是0.86,偏低,想着用K折交叉验证改进一下:
from sklearn.metrics import accuracy_score,f1_score,roc_auc_score,recall_score,precision_score
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import MultinomialNB, GaussianNB,BernoulliNB
def train_model(X, X_test, y, folds,params=None, model_type='LSVC', plot_feature_importance=False):
n_fold=5
iteration=3000
nrepeats = 2
prediction = np.zeros((X_test.shape[0], n_fold*nrepeats))
scores = []
feature_importance = pd.DataFrame()
fold_n=0
#split method 需要写得通用些,需支持两种策略的split!!!
for train_index, valid_index in folds.split(X, y):
fold_n+=1
print('Fold', fold_n, 'started at', time.ctime())
X_trn, X_val = X[trn_index], X[val_index]
y_trn, y_val = y[trn_index], y[val_index]
if model_type=='LSVC':
model= LinearSVC()
model.fit(X_train,y_train)
y_valid_pred=model.predict(X_valid)
y_pred=model.predict(X_test)
if mode_type=='mnb':
model=MultinomialNB()
model.fit(X_trn,y_trn)
y_val_pred=model.predict(X_val) # 使用逻辑回归函数对测试集进行预测
y_pred=model.predict(X_test)
if mode_type=='gnb':
model=GaussianNB()
model.fit(X_trn,y_trn)
y_val_pred=model.predict(X_val) # 使用逻辑回归函数对测试集进行预测
y_pred=model.predict(X_test)
if mode_type=='bnb':
model=BernoulliNB()
model.fit(X_trn,y_trn)
y_val_pred=model.predict(X_val) # 使用逻辑回归函数对测试集进行预测
y_pred=model.predict(X_test)
f1_scores.append(f1_score(np.array(y_val), y_val_pred,average='micro'))
accuracy_scores.append(accuracy_score(np.array(y_val), y_val_pred,average='micro'))
roc_auc_scores.append(roc_auc_score(np.array(y_val), y_val_pred,average='micro'))
recall_scores.append(recall_score(np.array(y_val), y_val_pred,average='micro'))
precision_scores.append(precision_score(np.array(y_val), y_val_pred,average='micro'))
print('CV mean f1_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(f1_scores), np.std(f1_scores)))
print('CV mean accuracy_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(accuracy_scores), np.std(accuracy_scores)))
print('CV mean roc_auc_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(roc_auc_scores), np.std(roc_auc_scores)))
print('CV mean recall_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(recall_scores), np.std(recall_scores)))
print('CV mean precision_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(precision_scores), np.std(precision_scores)))
prediction[:,fold_n]=y_pred
if model_type == 'lgb':
# feature importance
fold_importance = pd.DataFrame()
fold_importance["feature"] = X.columns
fold_importance["importance"] = model.feature_importance()
fold_importance["fold"] = fold_n + 1
feature_importance = pd.concat([feature_importance, fold_importance], axis=0)
# """对K个模型的结果进行融合,融合策略:投票机制"""
y_test_pred = []
for i in range(len(prediction)):
result_vote = np.argmax(np.bincount(prediction[i,:]))
y_test_pred.append(result_vote)
print('CV mean f1_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(f1_scores), np.std(f1_scores)))
print('CV mean accuracy_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(accuracy_scores), np.std(accuracy_scores)))
print('CV mean roc_auc_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(roc_auc_scores), np.std(roc_auc_scores)))
print('CV mean recall_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(recall_scores), np.std(recall_scores)))
print('CV mean precision_scores: {0:.4f}, std: {1:.4f}.'.format(np.mean(precision_scores), np.std(precision_scores)))
return y_test_pred
实验跑崩溃了,,,
参考链接:
https://www.geek-share.com/detail/2706861679.html
https://blog.csdn.net/Kaiyuan_sjtu/article/details/80030005
https://www.geek-share.com/detail/2727618572.html

- sklearn朴素贝叶斯类库(naive_bayes)使用小结
- python中sklearn的朴素贝叶斯方法(sklearn.naive_bayes.GaussianNB)的简单使用
- 【机器学习实战之二】:C++实现基于概率论的分类方法--朴素贝叶斯分类(Naive Bayes Classifier)
- 朴素贝叶斯分类算法(Naive Bayes Classifier)
- 朴素贝叶斯分类器的应用 Naive Bayes classifier
- 【十大算法实现之naive bayes】朴素贝叶斯算法之文本分类算法的理解与实现
- 机器学习系列--Naive Bayes Classification
- [置顶] 【机器学习 sklearn 】朴素贝叶斯naive_bayes
- 朴素贝叶斯分类器的应用 Naive Bayes classifier
- 朴素贝叶斯分类器 Naive Bayes Classifier
- 机器学习之Naive Bayes&&python实践
- 朴素贝叶斯模型(Naive Bayes Model,NB)理解
- 朴素贝叶斯分类算法(Naive Bayes algorithm)
- sklearn.naive_bayes
- 深入理解朴素贝叶斯(Naive Bayes)
- 机器学习——分类算法3:朴素贝叶斯(Bayes) 思想 和 代码解释
- 朴素贝叶斯方法(Naive Bayes Method)
- 【机器学习】文本分类——朴素贝叶斯Bayes
- 朴素贝叶斯(Naive-Bayes)介绍
- SparkMLlib Java 朴素贝叶斯分类算法(NaiveBayes)