Hashmap的结构,1.7和1.8有哪些区别
不同点:
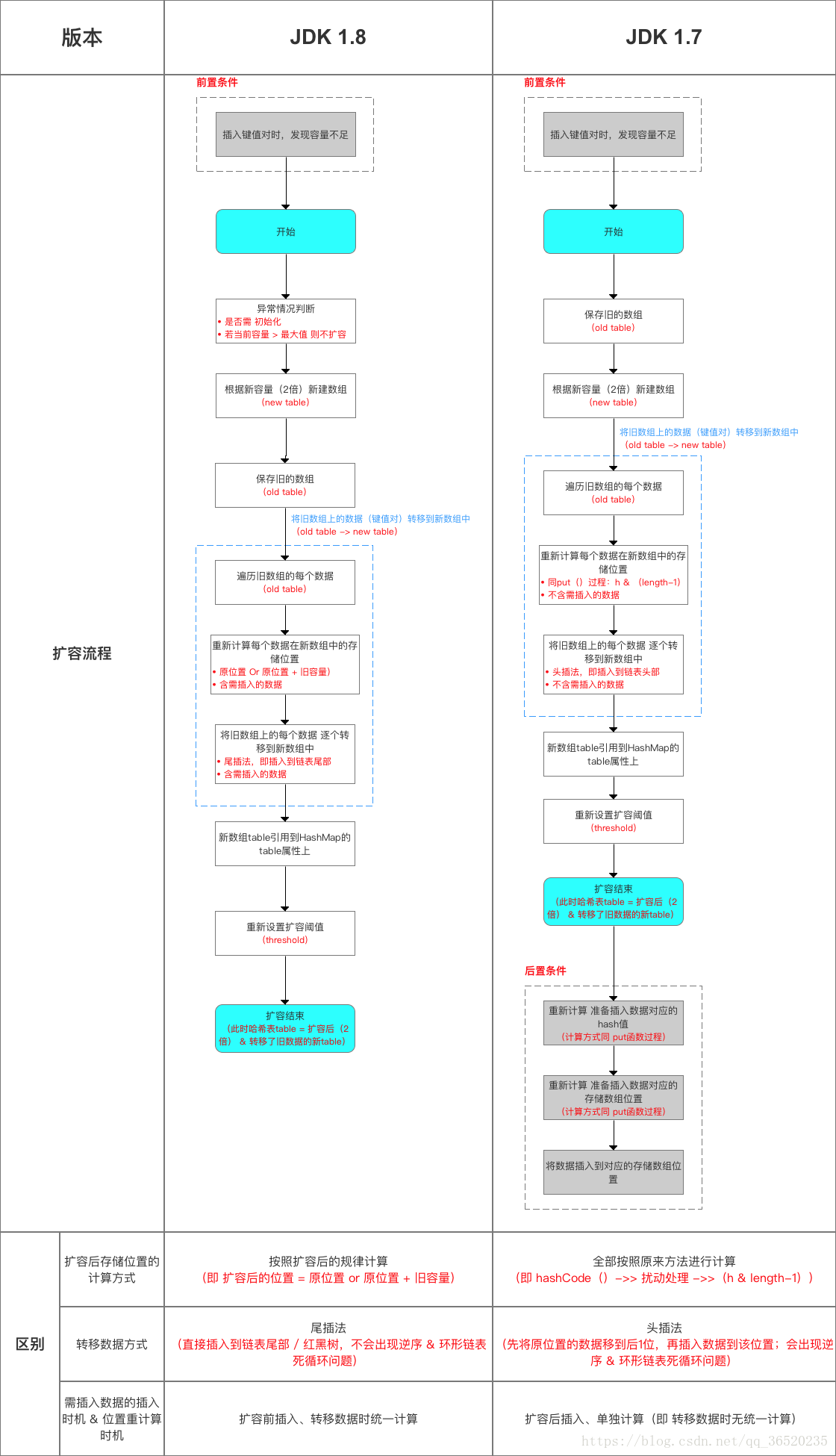
(1)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
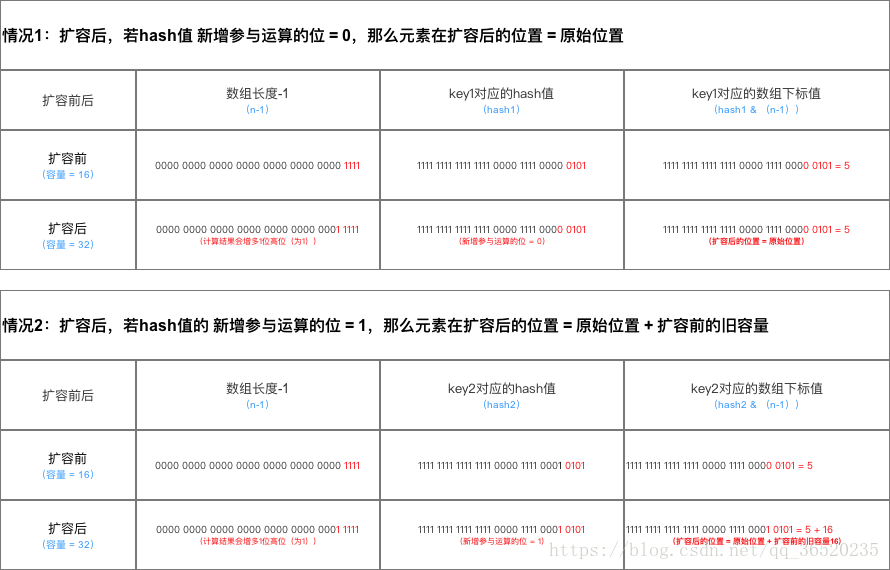
(2)扩容后数据存储位置的计算方式也不一样:1. 在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
2、而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。
在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。
扩容流程对比图:
(3)JDK1.7的时候使用的是数组+ 单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(nlogN)提高了效率)
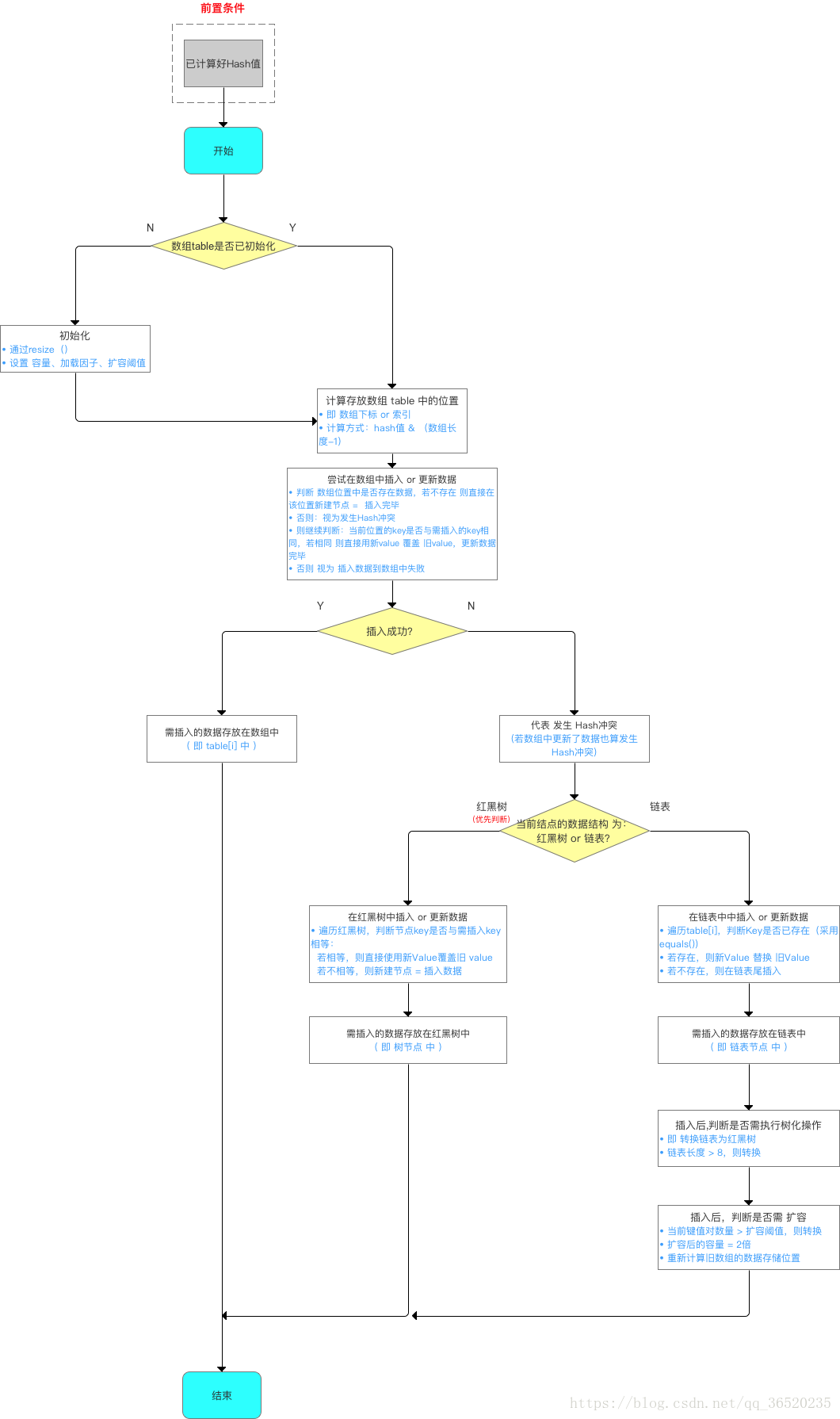
(二)哈希表如何解决Hash冲突?
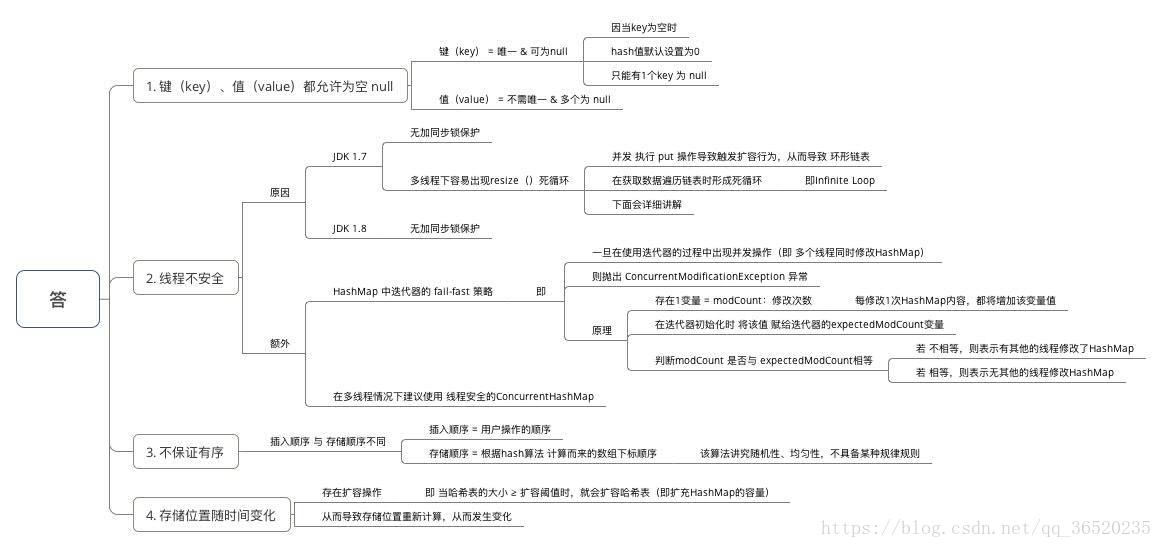
(三)为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化
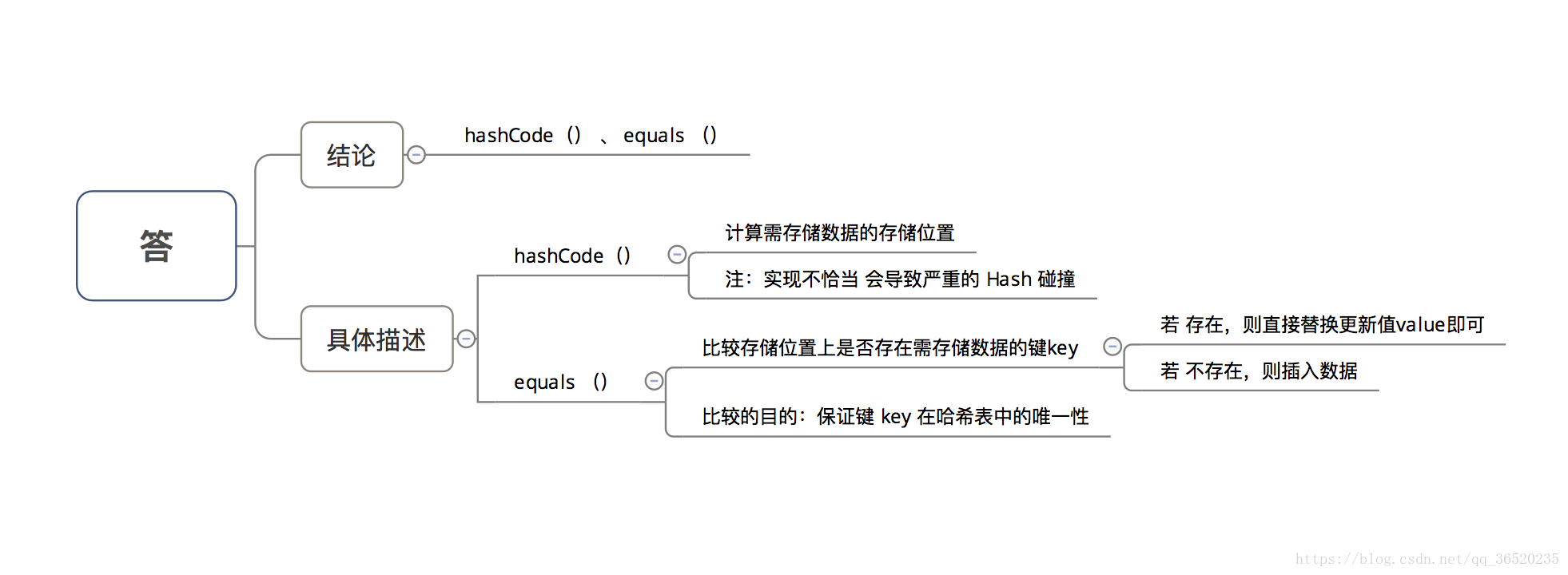
(五)HashMap 中的 key若 Object类型, 则需实现哪些方法?
---------------------
作者:依本多情
来源:CSDN
原文:https://blog.csdn.net/qq_36520235/article/details/82417949
版权声明:本文为博主原创文章,转载请附上博文链接!

- HashMap链表在Java1.7与1.8中的区别
- HashMap在Java1.7与1.8中的区别
- HashMap在Java1.7与1.8中的区别
- HashMap在Java1.7与1.8中的区别
- hashmap 在1.7和1.8中的区别?concurrenthashmap
- HashMap学习笔记,比较JDK1.7/1.8的区别
- HashMap在Java1.7与1.8中的区别
- HashMap 在 Java1.7 与 1.8 中的区别
- 一文读懂JDK1.7,JDK1.8,JDK1.9的hashmap,hashtable,concurrenthashmap及他们的区别
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
- HashMap的容量大小增长原理(JDK1.6/1.7/1.8)
- jdk源码剖析四:JDK1.7升级1.8 HashMap原理的变化
- 关于Linklist、Arraylis、Hashmap、Hashset、Hashtable t的特点、区别以及其数据结构
- HashMap 在JDK1.8中的实现(与JDK1.7对比)
- 【Java并发编程】23、ConcurrentHashMap原理分析(1.7和1.8版本对比)
- HashMap,HashTable,TreeMap,WeakHashMap有哪些区别?
- 牛客网Java刷题知识点之什么是HTTP协议、什么是HTTP隧道、HTTP响应的结构是怎么样的、HTTP报头包含哪些、HTTP中GET与POST方法有什么区别
- Collection结构图,及HashMap和Hashtable的区别
- jdk1.7和jdk1.8的区别
- str.split("")在JDK1.7和JDK1.8中的区别