HashMap 在 Java1.7 与 1.8 中的区别
hashMap 数据结构
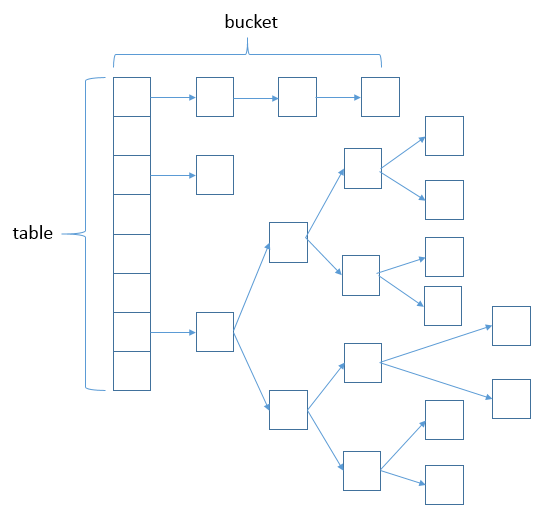
如上图所示,JDK7之前hashmap又叫散列链表:基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
JDK8中,当同一个hash值(Table上元素)的链表节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。这就是JDK7与JDK8中HashMap实现的最大区别。
其下基于 JDK1.7.0_80 与 JDK1.8.0_66 做的分析
JDK1.7中
使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同,或者hashcode取模后的结果相同(hash collision),那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表。
在hashcode特别差的情况下,比方说所有key的hashcode都相同,这个链表可能会很长,那么put/get操作都可能需要遍历这个链表
也就是说时间复杂度在最差情况下会退化到O(n)
JDK1.8中
使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构
如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里。
如果同一个格子里的key不超过8个,使用链表结构存储。
如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树。
那么即使hashcode完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销
也就是说put/get的操作的时间复杂度最差只有O(log n)
听起来挺不错,但是真正想要利用JDK1.8的好处,有一个限制:
key的对象,必须正确的实现了Compare接口
如果没有实现Compare接口,或者实现得不正确(比方说所有Compare方法都返回0)
那JDK1.8的HashMap其实还是慢于JDK1.7的
简单的测试数据如下:
向HashMap中put/get 1w条hashcode相同的对象
JDK1.7: put 0.26s,get 0.55s
JDK1.8(未实现Compare接口):put 0.92s,get 2.1s
但是如果正确的实现了Compare接口,那么JDK1.8中的HashMap的性能有巨大提升,这次put/get 100W条hashcode相同的对象
JDK1.8(正确实现Compare接口,):put/get大概开销都在320ms左右
为什么要这么操作呢?
我认为应该是为了避免Hash Collision DoS攻击
Java中String的hashcode函数的强度很弱,有心人可以很容易的构造出大量hashcode相同的String对象。
如果向服务器一次提交数万个hashcode相同的字符串参数,那么可以很容易的卡死JDK1.7版本的服务器。
但是String正确的实现了Compare接口,因此在JDK1.8版本的服务器上,Hash Collision DoS不会造成不可承受的开销。
参考资料: jdk1.7.0_80的HashMap源码 jdk1.8.0_66的HashMap源码 Java 8系列之重新认识HashMap HASH COLLISION DOS 问题 部分转载自:https://www.geek-share.com/detail/2708601260.html

- HashMap在Java1.7与1.8中的区别
- HashMap在Java1.7与1.8中的区别
- HashMap在Java1.7与1.8中的区别
- HashMap链表在Java1.7与1.8中的区别
- HashMap在Java1.7与1.8中的区别
- Java 1.5, 1.6, 1.7, 1.8的区别
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
- Java并发编程:ConcurrentHashMap原理分析(1.7与1.8)
- 【Java并发编程】23、ConcurrentHashMap原理分析(1.7和1.8版本对比)
- Java集合,HashMap底层实现和原理(1.7数组+链表与1.8+的数组+链表+红黑树)
- 【JAVA秒会技术之ConcurrentHashMap】JDK1.7与JDK1.8源码区别
- HashSet HashTable HashMap的区别 及其Java集合介绍
- registry key 'Java Runtime Environment' has value'1.8',but '1.7' is requaired
- 浅析Java中Map与HashMap,Hashtable,HashSet的区别
- Java中hashmap、linkedhashmap、treemap的区别
- Java基础之集合类如ArrayList、LinkedList、HashMap、HashTable的区别
- Java集合HashSet-ArrayList-HashMap的线程同步控制方法和区别
- 【转】java 容器类使用 Collection,Map,HashMap,hashTable,TreeMap,List,Vector,ArrayList的区别
- Java中List,ArrayList、Vector,map,HashTable,HashMap区别用法
- Java中substring方法在jdk1.6和jdk1.7中的区别