强化学习(马尔科夫决策过程)
强化学习笔记:
强化学习是机器学习的子领域。机器学习包括监督学习,非监督学习,强化学习。
强化学习的定义:
Reinforcement learning is a learning paradigm concerned with learning to control asystem so as to maximize a numerical performance measure that expresses a long-term objective。
Reinforcement learning is learning what to do—how to map situations to actions—so
as to maximize a numerical reward signal.
强化学习是一种学习控制系统的学习范式,以最大化表达长期目标。强化学习引起了极大的兴趣,因为它可以用来解决大量的实际应用,从人工智能问题到运筹学或控制工程。
强化学习正在学习如何做 - 如何将情境映射到行动 - 以便最大化数字奖励信号。
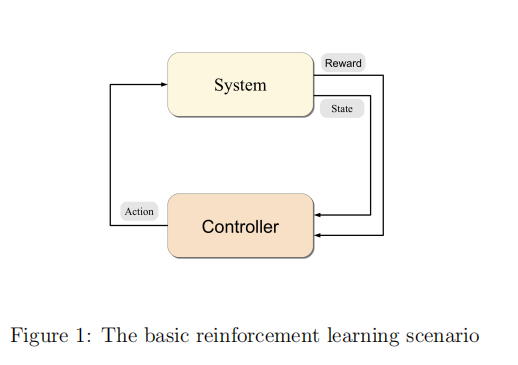
A controller receives the controlled system’s state and a reward associated with the last state transition. It then calculates an action which is sent back to the system. In response, the system makes a transition to a new state and the cycle is repeated. The problem is to learn a way of controlling the system so as to maximize the total reward.
一个 controller接收控制系统的状态和当前这个状态的immediate reward;之后计算应该发回到行动,系统作为应答,系统会发生一个状态转换,之后过程重复。目标是最大化长期奖励。
Problems with these characteristics are best described in the framework of Markovian Decision Processes (MDPs). The standard approach to ‘solve’ MDPs is to use dynamic programming, which transforms the problem of finding a good controller into the problem of finding a good value function.
马尔可夫决策过程是强化学习的基础。
MDP(Markov Decision Processes):
Markov Property:

St表示当前状态,在St已知时,可以不必考虑当前状态之前的历史信息,即St包含了所有的历史信息,对于将来状态的确定,具有足够的信息。
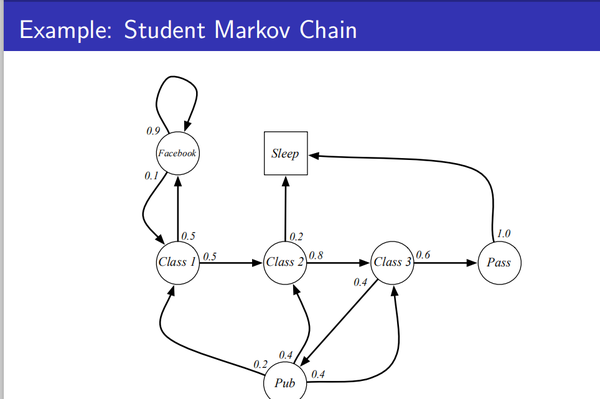
马尔科夫过程:
对于马尔科夫状态当前s,后继状态s',状态转移概率定义如下:
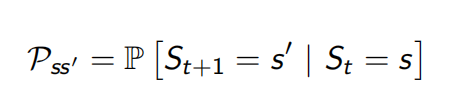
表示为矩阵形式如下:
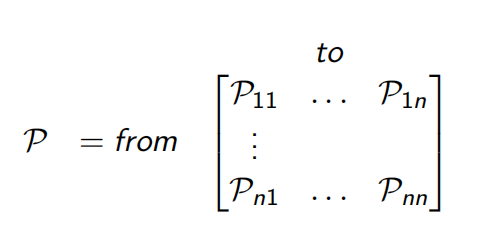
马尔可夫过程是一个无记忆的随机过程,随机序列S1,S2,....具有马尔科夫性质( Markov property.)
马尔科夫奖励过程(Markov Reward Process)MRP:
定义:每个状态中有一个immediate reward
a tuple :
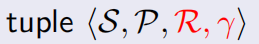
S:表示有限的非空状态集合;
A:有限的非空行动集合;
P代表状态转移概率,从当前状态转移到所有后继状态的概率。
R:代表一个奖励函数:Rs = E [Rt+1 | St = s]
γ is a discount factor, γ ∈ [0, 1]
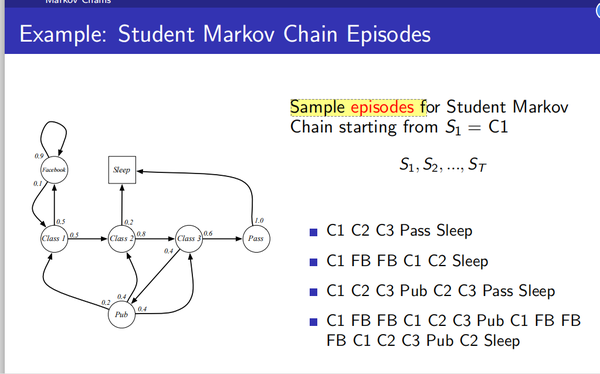
Return:
Gt:是一个当前状态的以后的所有奖励;是一个从当前时刻所处的状态往后的时间内获得奖励的例子:
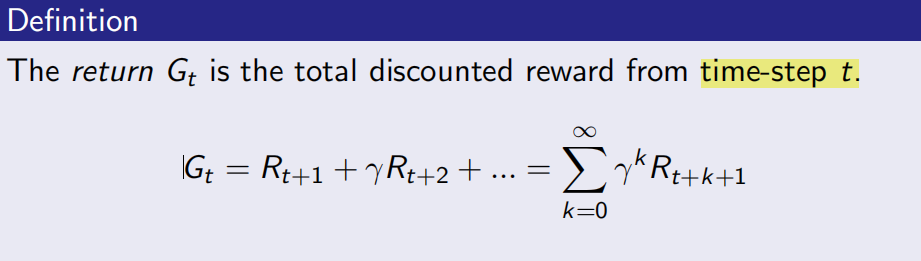
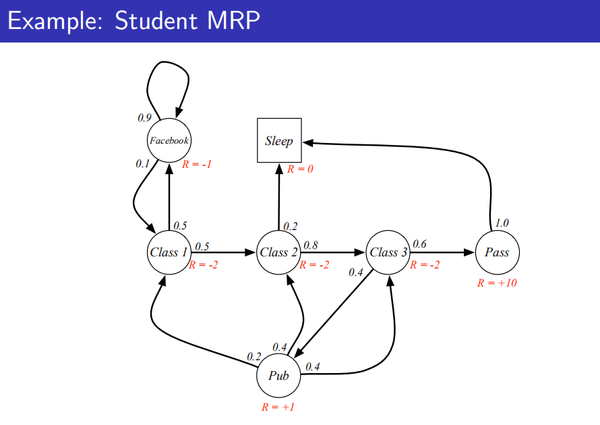
举例如下:
当前状态是S1=C1,折扣因子是1/2;分别几次的采样结果如下所示,对每次采样分别计算return。

Value Function
状态值函数(The value function v(s) )给出了当前状态之后可能获得return的期望;用值函数来表示当前状态在将来可能具有的价值。
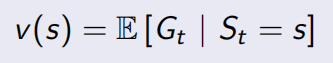
上述公式的分解:
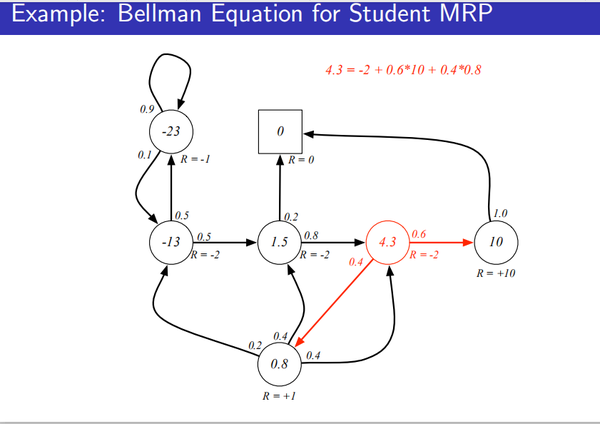
Bellman equation:
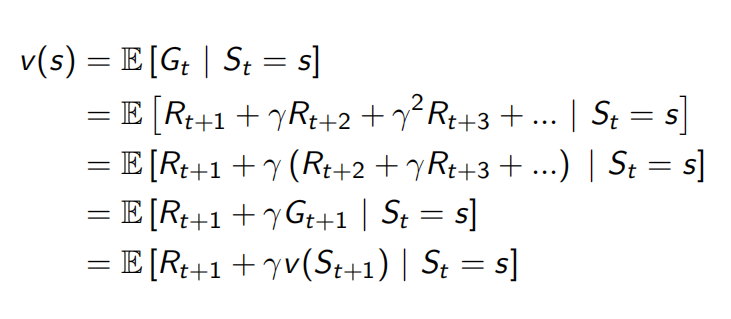
认为这里向上述公式这样表示并不是很好理解,下述公式较好理解:
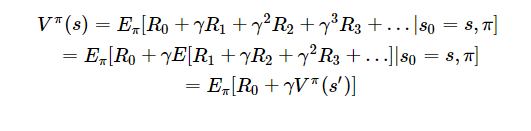

给定策略Π和初始状态s0,则动作a0在Π给定下是唯一的,但下个时候将以概率转向下个状态s’;即当前状态采取动作后,由动作转向下一个状态有多种可能;
即R0(当前状态的immediate reward)是已知;而后面的奖励R则是未知。直接以Gt表述不够充分;Gt是一个状态后的一个确定序列的return;而上述是未知的;所以第二种公式表达方法更正确。

上述公式表示:当前状态的值函数等于immediate reward加上下一个状态的值函数。其中 对上述公式的具体表示如下:
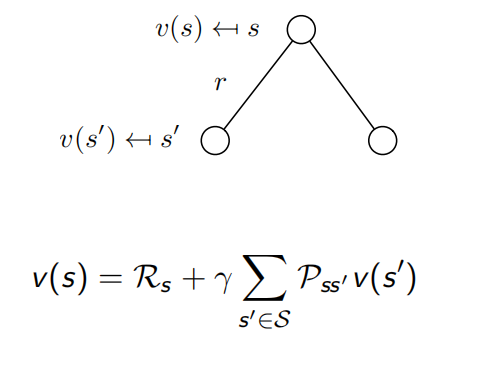
把上述公式表示为矩阵形式如下:
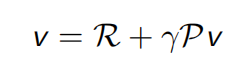
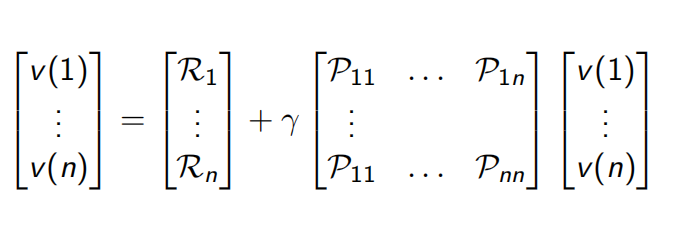
MDP:
A Markov decision process (MDP) is a Markov reward process with decisions.

策略(policy):
已经处于某个状态s时,我们会以一定的策略π来选择下一个动作a执行,然后转换到另一个状态s′。我们将这个动作的选择过程称为策略(policy),每一个policy其实就是一个状态到动作的映射函数π:S→A。给定π也就是给定了a=π(s),也就是说,知道了π就知道了每个状态下一步应该执行的动作。
策略π是给定状态的动作分布,
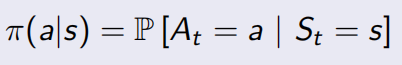
A policy fully defines the behaviour of an agent。
MDP policies depend on the current state (not the history)
i.e. Policies are stationary (time-independent),
一个策略确定的话,则每个状态下执行的动作确定。
下面的第一个公式表示:在策略π下,从当前状态转换到下一个状态的概率表述为下述形式:
从当前策略中选择一个动作的概率乘以在这个动作下转移到下一个状态的概率,再对当前策略可以选择的所有动作求和。
下面的第二个公式表示:在策略下,获得的immediate reward的值可以表述为:
在当前状态,策略下,选择一个动作的概率乘以当前动作下获得的immediate reward;然后再对当前策略下所有可能的动作进行求和。
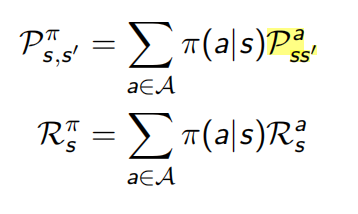
The state-value function vπ(s) of an MDP is the expected return starting from state s, and then following policy π。价值函数为特定的策略π所定义。策略π固定时,价值函数是唯一的。
vπ(s) = Eπ [Gt| St = s]
The action-value function qπ(s, a) is the expected return starting from state s, taking action a, and then following policy π
qπ(s, a) = Eπ [Gt| St = s, At = a]
The state-value function can again be decomposed into immediate reward plus discounted value of successor state,
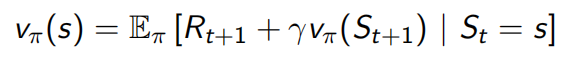
The action-value function can similarly be decomposed,
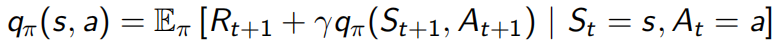

下面是大佬的代码实现:
algorithmdog/Reinforcement_Learning_Bloggithub.com

参考文献:
视频和讲义:
Teachingwww0.cs.ucl.ac.uk
Reinforcement learning an introduction
Algorithms for Reinforcement Learning
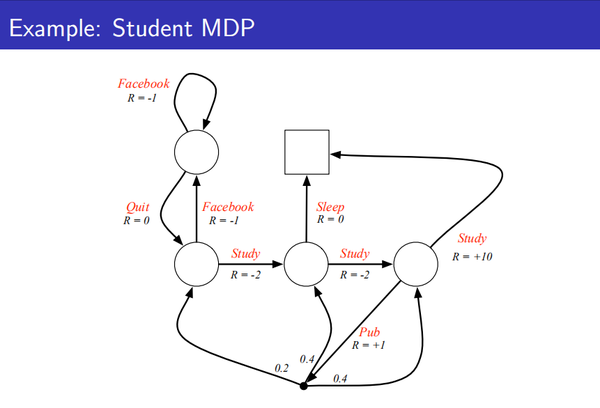
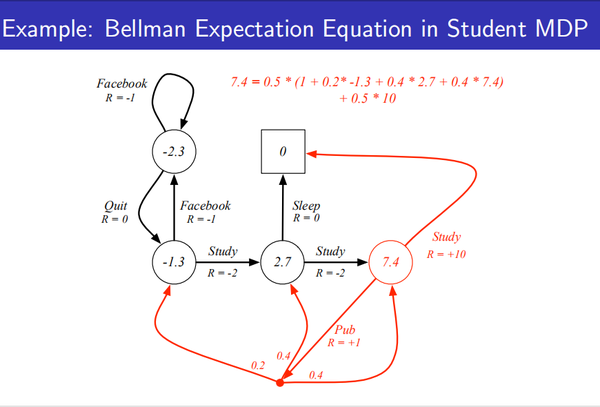
强化学习:马尔科夫决策过程 下面ppt截图:
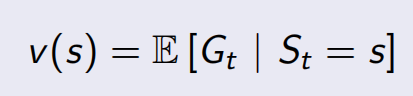













策略π是给定状态的动作分布,








- 强化学习入门第一讲 马尔科夫决策过程
- 强化学习笔记1--马尔科夫决策过程
- David Silver深度强化学习第2课 - 马尔科夫决策过程
- 强化学习入门第一讲 马尔科夫决策过程
- 【CS229 lecture16】强化学习-马尔科夫决策过程(MDP)
- 强化学习入门第一讲 马尔科夫决策过程
- 强化学习笔记—马尔科夫决策过程(MDP)
- 强化学习读书笔记 - 03 - 有限马尔科夫决策过程
- David Silver强化学习公开课之二 马尔科夫决策过程
- 漫谈机器学习经典算法—增强学习与马尔科夫决策过程
- 增强学习与马尔科夫决策过程
- 人工智障学习笔记——强化学习(1)马尔科夫决策过程
- 强化学习第4课:这些都可以抽象为一个决策过程
- 增强学习与马尔科夫决策过程
- 增强学习(一)——马尔科夫决策过程(MDP)
- 深度增强学习David Silver(二)——马尔科夫决策过程MDP
- 增强学习-马尔科夫决策过程
- MDP:马尔科夫决策过程(二)
- 强化学习系列之一:马尔科夫决策过程
- David silver 的 reinforcement learning 课程笔记(二):马尔科夫决策过程