强化学习笔记—马尔科夫决策过程(MDP)
2017-12-28 15:41
627 查看
写在前面
最近刚接触强化学习,系统的学习资料感觉很少,不过好像最近有一本强化学习的书要出来,还是蛮期待的。结合师兄给的一些资料和网络资源进行“艰难”的摸索过程,任重道远。将学习过程中的一些知识记录在这里,加深印象,特别感谢这个专栏。强化学习
强化学习目前越来越火,从AlphaGo到AlphaZero让大家见识到了强化学习的力量,有很多AI大牛也公开表示强化学习是改变未来重要的工具。这里就以及不专业的理解说一下对强化学习的理解吧。假如我们训练一只狗狗,希望它能按照我们的要求坐下、站着等等,起先它会很笨,老是做不对。后来随着训练时间和训练次数的增加,10000次中终于有一次做对了,我们就给它一根骨头奖励它,再后来,它变聪明了,知道做对了就有骨头,所以时间再增加,次数再增多,它便每次都很听话,每一次都能按照我们的要求做动作。强化学习类似于这样的过程,我们对系统每一步都会给一个奖励来刺激它获取更大的奖励,直到总的奖励最大,这个系统也就变成了我们想要的东西。这是个人对强化学习的比较直观的理解,马尔科夫决策过程是一个简单的强化学习模型,我们就从它开始下手吧!!马尔科夫随机过程
大学概率统计中有过马尔科夫随机过程的描述,这里只是简单的对这些概念进行回顾,若需要详细了解可以找本概率的书本或者百度一下,相对还是比较简单的一个知识,作用很大。马尔科夫性
马尔科夫性简单来说就是指在一个随机过程中,下一时刻的状态只和当前状态有关,与之前的状态无关。用数学语言描述是:P(st+1|st,st−1...s1)=P(st+1|st)如果一个随机过程中,任意两个状态之间都满足马尔科夫性,那么该随机过程就是一个马尔科夫随机过程。一个马尔科夫过程可以用一个二元组(S,P)描述,S是该过程的有限状态集合,P是这些状态之间的转移概率矩阵。这个矩阵并不是一定对称的,也就是说si−>sj的转移概率并不一定等于sj−>si的转移概率。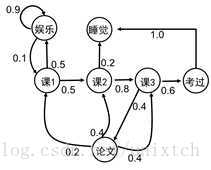
以上面这副图为例,该图中的状态有:{娱乐,课1,课2,课3,考过,论文,睡觉},边上面的数字就是这些状态之间的转移概率,例如:p(课1|娱乐)=0.1,p(课2|课1)=0.5。
马尔科夫决策过程
马尔科夫决策过程(Markov Decision Process, MDP)以马尔可夫随机过程为理论基础,马尔科夫决策过程也可以用一个元组(S,A,P,R,γ)来表示。S是决策过程中的状态集合;A是决策过程中的动作集合;P是状态之间的转移概率;R是采取某一动作到达下一状态后的回报(也可看作奖励)值;γ是折扣因子。特别地,这里的转移概率与马尔科夫随机过程不同,这里的转移概率是加入了动作A的概率,如果当前状态采用不同动作,那么到达的下一个状态也不一样,自然转移概率也不一样。转移概率形式化描述是:pass^=p(s^|s,a)=p(St+1=s^|St=s,At=a)意思是:在t时刻所处的状态是s,采取a动作后在t+1时刻到达s^的概率。以上面的图为例,不过我们改变了图中的形式: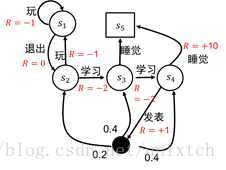
图中的状态集变成了{s1,s2,s3,s4,s5},动作集合为{玩,退出,学习,睡觉,发表},图中红色的字就是回报。
这里可以这样来看,在马尔科夫随机过程中我们专注于状态之间的改变,而状态之间是怎么改变的我们并不关心,往往是通过转移概率来衡量不同状态之间转移的可能性大小;而在马尔科夫决策过程中,多了一个决策,这个决策也就是我们前面所说的动作,在采用什么动作后,到达下一时刻的状态,并且给这个决策一个回报值来衡量该决策的好坏。
在MDP中,决策可以用π(a|s)=p(At=a|St=s)来表示,意思是在t时刻处于状态s的情况下,选用a动作的概率。可以看到,在每个状态s采取的动作a并不确定,那么状态序列也不一样,用上图来说明,当初始状态处于s1时,那么整个状态序列可以是:s1−>s1,a1=退出或者s1−>s2−>s3−>s4−>s5,a1=退出,a2=学习,a3=学习,a4=睡觉同样可以是:s1−>s2−>s3−>s5,a1=退出,a2=学习,a3=睡觉那么对于整个过程,我们怎么去衡量中间状态st的好坏呢?我们可以这样来看,状态st到st+1会有一个回报,st+1到st+2同样会有一个回报,以此类推。但st对st+1的影响很大,但对于st+2,st+3...会越来越小,所以提出了一个折扣因子γ来减小后面状态的回报对当前状态衡量的影响。于是我们得出所谓的累计回报函数:Gt=Rt+1+γRt+2+...=∑k=0∞γkRt+k+1由于Gt并非一个确定值(中间涉及到概率选择动作),所以采用期望来计算这个累计回报函数,也叫做状态值函数,也就是:vπ(s)=Eπ[Gt]=Eπ[∑k=0∞γkRt+k+1|St=s]在这个式子中,状态值函数vπ(s)仅仅和策略π有关,也就是说策略唯一确定了状态值函数的分布。而策略由动作a确定,所以将动作加入其中:qπ(s,a)=Eπ[∑k=0∞γkRt+k+1|St=s,At=a]qπ(s,a)又叫做状态-动作函数。可以发现vπ(s)存在如下关系:vπ(s)=E[Gt|St=s]=E[Rt+1+γRt+2+...|St=s] =E[Rt+1+γ(Rt+2+γRt+3)|St=s] =E[Rt+1+γGt+1|St=s] =E[Rt+1+γvπ(St+1)|St=s]这个关系叫做贝尔曼方程,同样可以得到状态—行为函数的贝尔曼方程:qπ(s,a)=Eπ[Rt+1+γqπ(St+1,At+1)|St=s,At=a]
由于状态值函数是以期望定义的,根据期望的计算规则,状态值函数应该是:vπ(s)=∑a∈Aπ(a|s)qπ(s,a)
粗略的理解是在t时刻的状态s,以某以概率选择动作a,动作a产生的状态—动作值是qπ(s,a),于是也就有上面的期望计算式。再将qπ(s,a)改写成:qπ(s,a)=Ras+γ∑s^∈SPass^vπ(s^)所以:vπ(s)=∑a∈Aπ(a|s)(Ras+γ∑s^∈SPass^vπ(s^)) 而:vπ(s^)=∑a^∈Aπ(a^|s^)qπ(s^,a^)
定义最优的状态值函数v∗(s)=maxπvπ(s),也就是所有策略中最大的状态值函数;同理最优的抓状态—动作函数q∗(s,a)=maxπq(s,a),所有策略中最大的状态-动作值函数值。根据上面的式子有:v∗(s)=maxRas+γ∑s^∈SPass^v∗π(s^) q∗(s,a)=Ras+γ∑s^∈SPass^maxa^q∗π(s^,a^) 这里的符号很多,容易混,细心看一下。
强化学习的目的
通过上面的说明,强化学习的目的就是找到最优的策略,使累计回报函数最大,同时,如果累计回报函数最大时,采用的策略也是最优的。所以强化学习的优化有两种方法:(1)基于策略的优化;(2)基于累计回报函数的优化。另外,强化学习算法根据策略是否是随机的,分为确定性策略强化学习和随机性策略强化学习。根据转移概率是否已知可以分为基于模型的强化学习算法和无模型的强化学习算法。另外,强化学习算法中的回报函数R十分关键,根据回报函数是否已知,可以分为强化学习和逆向强化学习。逆向强化学习是根据专家实例将回报函数学出来。过程理解总结
整体来说,强化学习是一个最优化的过程:根据初始状态,一步一步的寻找一个状态动作轨迹,从而使累计回报最大。根据状态t时刻的状态s,随机选择一个动作a,跳转到下一时刻的某一个状态s^,这一步跳转由于涉及随机性,所以不能直接用回报值来决定选择下一步的去向,所以根据期望值来决定。再来说状态值函数和状态—动作值函数的关系,状态—动作值函数意思是才用了某一动作a后的回报,但是该动作是随机性的,所以状态—动作值函数乘以选择动作的概率,这就是状态—动作值函数的期望,也就是状态函数值了。而状态值函数以及状态—动作函数的贝尔曼方程将两者从理论上联系到了一起,并且可以看作是递归计算方式。最后是折扣因子,越往后,折扣因子的乘积越小,其实可以这样理解,如果第一步走错了,那么后面可能会越走越错,所以后面的影响相对开始会较小。这是目前个人的理解,希望指正。
相关文章推荐
- 【CS229 lecture16】强化学习-马尔科夫决策过程(MDP)
- 强化学习笔记1--马尔科夫决策过程
- 强化学习入门第一讲 马尔科夫决策过程
- 强化学习读书笔记 - 03 - 有限马尔科夫决策过程
- 增强学习(一)——马尔科夫决策过程(MDP)
- 人工智障学习笔记——强化学习(1)马尔科夫决策过程
- 强化学习入门第一讲 马尔科夫决策过程
- 强化学习入门第一讲 马尔科夫决策过程
- David Silver强化学习公开课之二 马尔科夫决策过程
- 深度增强学习David Silver(二)——马尔科夫决策过程MDP
- 增强学习与马尔科夫决策过程
- MDP:马尔科夫决策过程(二)
- 漫谈机器学习经典算法—增强学习与马尔科夫决策过程
- 增强学习与马尔科夫决策过程
- 强化学习(二)——MDP:马尔科夫决策过程
- 增强学习-马尔科夫决策过程
- 《Reinforcement Learning》 读书笔记 3:有限马尔科夫决策过程
- 强化学习(二)马尔科夫决策过程(MDP)
- MDP:马尔科夫决策过程(三)
- MDP:马尔科夫决策过程(一)