【论文翻译】Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning
2018-10-27 16:34
721 查看
标题:在室内场景中基于深度强化学习下的目标驱动的视觉导航
作者:Yuke Zhu1 Roozbeh Mottaghi2 Eric Kolve2 Joseph J. Lim1;5 Abhinav Gupta2;3 Li Fei-Fei1 Ali Farhadi2;
-
摘要:
有两个关于深度强化学习的问题没有得到很好的解决: (1)缺乏对新目标的泛化能力 - (2)数据效率低下,即,模型需要多次(而且往往代价高昂)反复试验和错误才能收敛,将其应用于实际场景是不切实际的。
- (1)比最先进的深度强化学习方法收敛更快
-
I. INTRODUCTION
机器人技术中,许多任务都涉及到与物理环境或对象的交互。我们需要了解agent的“动作”与由于操作而引起环境的“变化”之间的相关性和因果联系。自20世纪70年代以来,人们一直在尝试建立一个能够理解这种联系的系统。近年来,随着深度学习的兴起,基于学习的方法得到了广泛的普及。 - 在本文中,我们关注的问题是如何在空间中导航,从而实现只使用视觉输入来找到给定的目标。成功的导航需要学习动作和环境之间的关系。这个特点使得任务非常适合深度强化学习(DRL)算法。然而,一般DRL算法思路是:策略的学习只依赖于当前状态,而导航的目标被隐式地嵌入到模型参数中。因此,有必要为一个新的目标学习新的模型参数。这是有问题的,因为训练DRL agent需要昂贵的计算成本。
-

- Fig 1 :我们的深度强化学习模型的目标是:用最少的步骤导航到一个视觉目标。我们的模型将当前的观测和目标图像作为输入,并在3D环境中生成一个动作作为输出。我们的模型学习如何在场景中导航到不同的目标并且不需要重新训练。
- 为了获得更高的适应性和灵活性,我们引入了目标驱动模型。我们的模型将可视化的目标作为输入。因此,我们可以避免对每一个新目标进行重新训练。我们的模型学习了一种策略,它共同输入目标和当前状态。从本质上说,一个agent采取下一个动作时,条件是它的当前状态和目标,而不仅仅是它的当前状态。因此,不需要为新的目标重新训练模型。我们依赖的一种关键直觉是:不同的训练集分享信息。例如,agents在训练阶段探索共同的路线,同时被训练去寻找不同目标。各种各样的场景也有相似的结构和统计数据(例如,冰箱很可能靠近微波炉)。简而言之,我们利用了这样一个事实:为其他目标训练的模型学习新的目标将会更容易。
- 不幸的是,在实际环境中训练和定量评估DRL算法常常是乏力的。其中一个原因是:在物理空间中运行系统会耗费时间。此外,通过常见的图像数据集收集技术在真实环境中获取大规模的动作和交互数据很麻烦。为此,我们开发了第一个具有高质量3D场景的模拟框架,称为“交互之家”(AI2-THOR)。我们的模拟框架使我们能够收集大量的”不同环境下的动作和反馈“的视觉观察。例如,agent可以自由导航(即在各种真实的室内场景中移动和旋转),并能够与对象进行低水平和高水平的交互(例如,施加力或打开/关闭微波)。
- 我们对以下任务进行评估: (1)目标泛化(目的:在训练过的场景中,对未使用过的目标进行导航)
- (2)场景泛化(目的:在未训练过的场景中,进行导航,寻找到目标)
- (3)在现实世界的推广中,我们演示了如何使用一个真正的机器人来导航目标
II. RELATED WORK
- 在视觉导航方面有大量的工作要做。我们提供了一些相关工作的简要概述。基于地图的导航算法需要环境的全局地图来帮助导航做决策。我们的算法相比这些算法的主要优势之一是:它不需要预先的环境地图。另一种导航算法可以在飞机上重建地图,并用其导航,或者是通过一个由人类引导的训练阶段来构建地图。相比之下,我们的方法不需要环境地图,因为它不需要对环境的地标做任何假设,也不需要人工指导的训练阶段。无地图导航方法也很常见。这些方法主要关注于输入图像的避障。我们的方法被认为是无地图的。然而,它拥有对环境的隐性知识。视觉导航方法的研究可以在《Visual navigation for mobile robots: A survey》一文中找到。

III. THE AI2-THOR FRAMEWORK
- 为了训练和评估我们的模型,我们需要一个框架来执行动作并在3D环境中感知动作的结果。将我们的模型与不同类型的环境融合是我们模型泛化的主要需求。因此,框架应该具有一个多功能的架构,这样不同类型的场景就可以很容易地结合在一起。此外,框架应该有一个关于场景物理性质的详细模型,这样动作和对象的交互就会被正确地表示出来。
IV. TARGET-DRIVEN NAVIGATION MODEL
- 在本节中,我们首先定义目标驱动视觉导航的公式。然后,我们描述了我们在这项任务中的深度孪生actor-critic 网络。
A. Problem Statement
我们的目标是:找到将agent从当前位置移动到由RGB图像指定的目标位置的最小长度序列。我们开发了一个深度强化学习模型,以当前观测RGB图像和目标RGB图像作为输入。模型的输出是一个3D的动作,比如向前移动或右转。注意,模型学习了从2D图像到3D空间中的动作的映射。
B. Problem Formulation
- 基于视觉的机器人导航需要从感官信号到运动指令的映射。先前关于强化学习的工作中,通常不考虑高维感知输入。最近的深度强化学习(DRL)模型提供了一个端到端学习框架,用于将像素信息转换为动作。然而,DRL模型在很大程度上专注于学习特定的目标,这些模型单独处理单个任务。这种训练方式对于任务目标的改变是相当不灵活的。例如,Lake指出,改变游戏规则将对基于DRL的 GO-play系统产生破坏性能的影响。这种局限性源于这样一个事实:即标准DRL模型的目标是寻找---从状态s到策略p(s)的直接映射(由深度神经网络p表示)。在这种情况下,目标位置以硬编码固化在了神经网络的参数里面。因此,目标的改变将需要更新相应的网络参数。
C. Learning Setup
- 在介绍我们的模型之前,我们首先描述了强化学习设置的关键要素:动作空间、观察和目标,以及奖励设计:
1) 动作空间 :现实世界移动机器人必须涉及底层的机械。然而,这样的机械细节使得学习变得更具挑战性。常见的方法是在特定的抽象层次上学习,其中下层的物理由低级控制器(例如,3D物理引擎)来处理。我们用命令级别的行动来训练我们的模型。对于我们的视觉导航任务,我们考虑四个动作:前进、后退、左转和右转。我们使用定步长(0.5米)和转弯角度(90度)。这本质上将场景空间离散为网格世界。为了模拟真实系统动力学中的不确定性,我们在步骤N(0;0.01)中加入高斯噪声,并在每个位置上都旋转N(0;1.0)。
D. Model
- 我们的重点是通过深度强化学习来学习目标驱动的策略函数p。我们设计了一种新的深度神经网络作为pi的非线性函数逼近器,其中在t时刻的动作可以用下式表示:
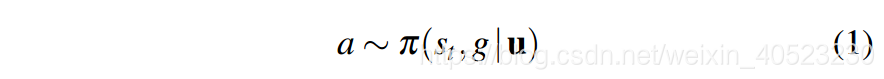
E. Training Protocol
- 传统的RL模型对分离的单个任务进行学习,导致目标更改缺乏灵活性。由于我们的深度孪生表演评论家网络共享不同任务的参数,它可以从同时学习多个目标中获益。A3C是一种强化学习模型,它通过并行运行多个训练线程副本来学习,并以异步方式更新一组共享的模型参数。事实证明,这些并行的训练线程相互稳定,在视频游戏领域达到了最先进的性能。我们采用的是类似A3C的训练程序。然而相比于运行单个游戏的副本,每个线程都使用不同的导航目标运行。因此,梯度从执行者-批评家输出反向传播回较低层次层。特定场景层由场景中导航任务的梯度更新,而通用的孪生层则由所有目标更新。
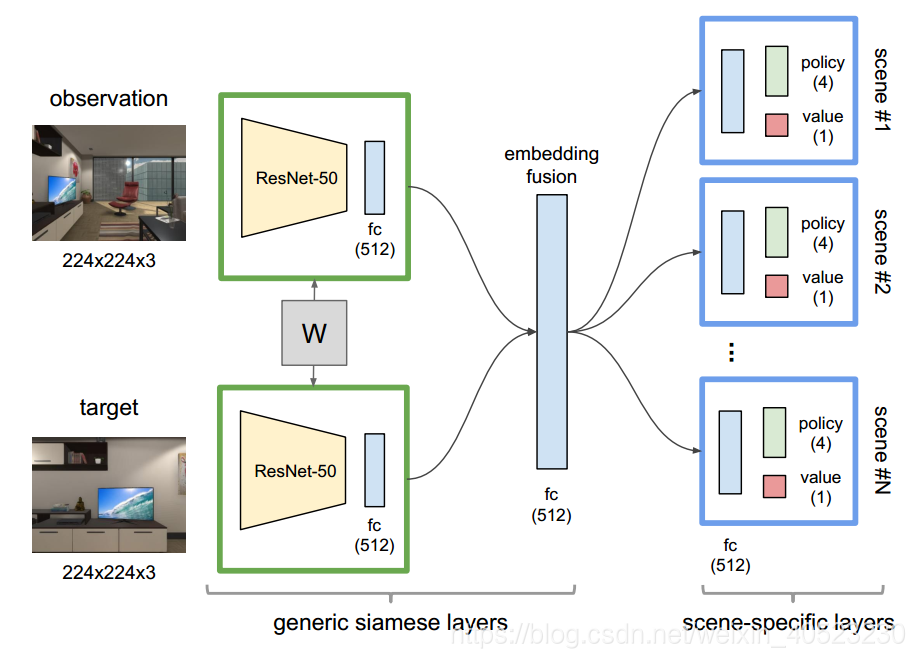
F. Network Architectures
- 孪生层的下半部分是ImageNet预训练的ResNet-50(截断了softmax层),在224*224*3RGB图像上产生2048-d特征。我们在训练时冻结这些ResNet参数。我们将4个历史帧的特征连接起来,以解释agent过去的动作。来自两个流的8192-d输出矢量被投影到512-d嵌入空间中。融合层对状态和目标进行1024-d串联嵌入,生成512-d的联合表示。这个矢量被进一步传递到两个全连接的特定场景层,产生4个策略输出(动作的概率)和一个单值输出。我们共享学习速率为7×10−4RMSProp的优化器,从而训练了这个网络。
V. EXPERIMENTS
- 目标驱动导航的主要目标是找到从当前位置到目标的最短轨迹。我们首先使用基于启发式和标准深度RL模型的基线导航模型来评估我们的模型。我们提出的模型的一个主要优点是能够推广到新的场景和目标。我们做了另外两个实验来评估我们的模型跨目标和跨场景传递知识的能力。同时,我们展示了模型对连续空间的扩展。最后,我们用一个真正的机器人来演示我们的模型在一个复杂的真实环境中的性能。
A. Navigation Results
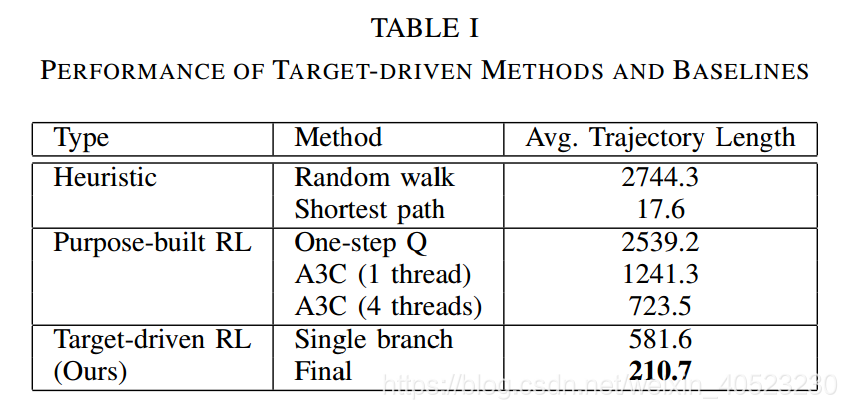
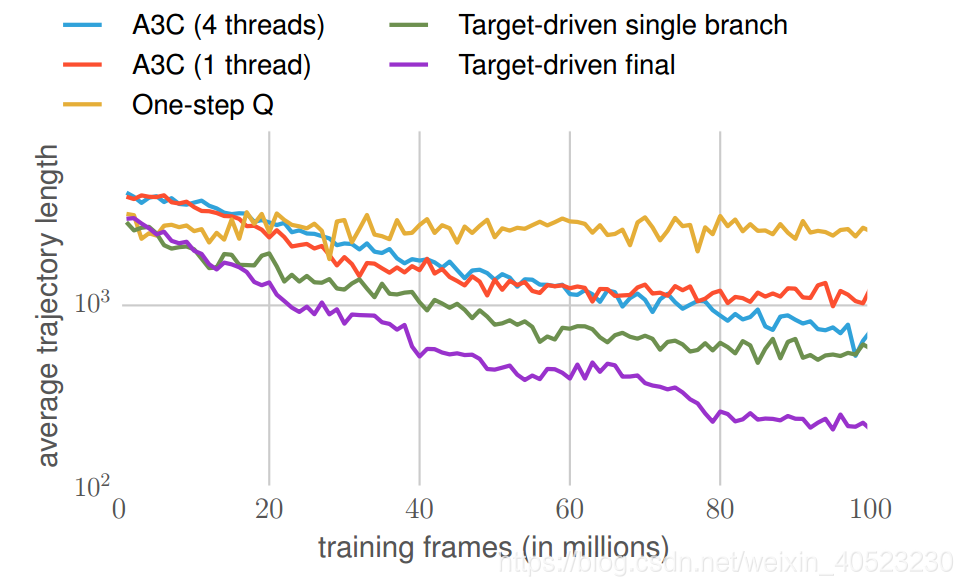
我们在Tensorflow中实现我们的模型,并在Nvidia GeForce GTX Titan X GPU上进行训练。我们遵循Sec中描述的x训练协议。IV-E用100个线程训练我们的深度孪生演员-批评家模型(见图4),每个线程学习不同的目标。在所有线程上完成100万个训练帧大约需要1.25小时。我们将性能表示为从随机起点到达目标所需的平均步数(即平均轨迹长度)。从我们数据集中的20个室内场景中随机抽取100个不同的目标,测试了导航性能。我们将最终的模型与启发式策略、标准深度RL模型以及模型的变体进行了比较。我们选取比较的模型是: 1)随机漫步:是最简单的导航启发式算法,在这个基线模型中,agent在每个步骤中随机抽取四个动作中的一个。计算从起始点到目标点的最短路径。注意,对于计算最短路径,我们需要能访问环境的完整地图,而我们系统的输入只是一个RGB图像。
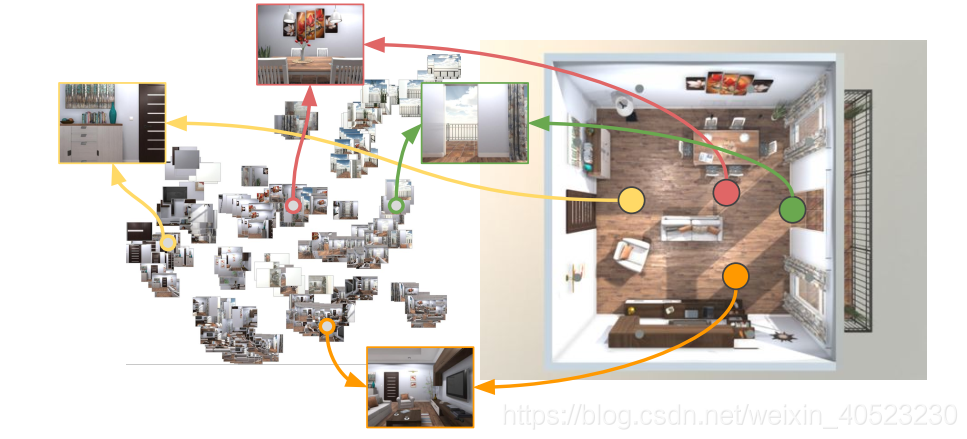
B. Generalization Across Targets
- 除了我们的目标驱动的RL模型的数据效率之外,它还有内置的泛化能力,这比专门构建的基线模型有很大的优势。我们在两个方面评估其泛化能力:1.在一个场景泛化到新的目标 2.泛化到新的场景。在本节中,我们将重点讨论目标间的泛化,并在下一节中解释场景泛化。我们测试模型以导航到新的目标。这些新目标没有经过训练,但它们可能与经过训练的目标共享相同的路线,从而允许知识转移。
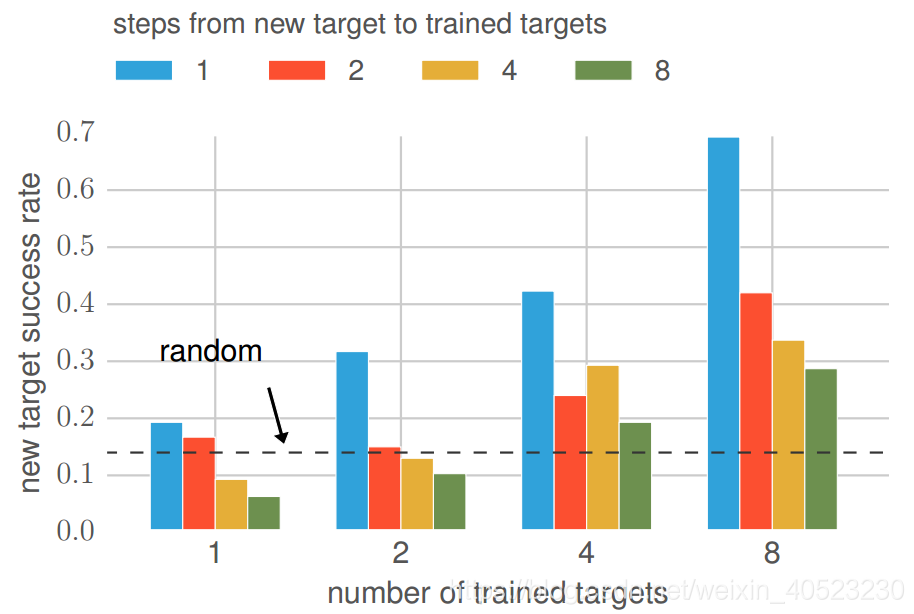
C. Generalization Across Scenes
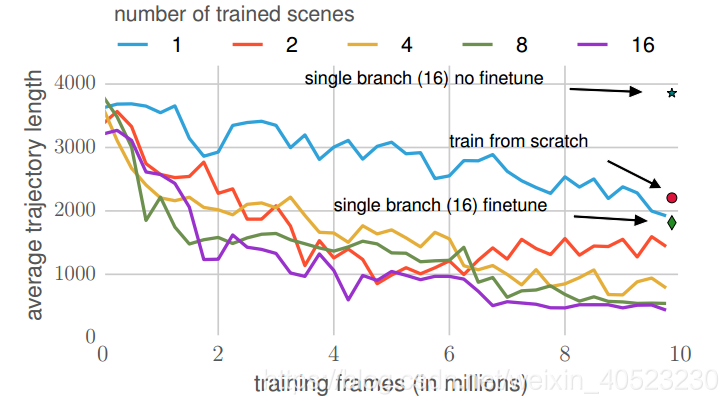
- 我们进一步评估我们的模型在场景间的泛化能力。由于通用的孪生层在所有场景中都是共享的,我们研究了将知识从这些层转移到新场景的可能性。此外,我们还研究了训练场景的数量将如何影响泛型层参数的可转移性。我们将训练后的场景从1个逐渐增加到16个,对4个看不见的场景进行测试。我们从每个场景中选择5个随机目标进行训练和测试。为了适应看不见的场景,我们在固定一般的孪生层的同时,训练特定场景层。结果如图8所示。随着训练场景的增加,我们观察到更快的收敛速度。与从头开始的训练相比,转移通用层可以显著提高在新环境中学习的数据效率。我们还对相同设置中的单个分支模型进行了评估。chan由于单个分支模型包含单个场景特定层,我们可以将经过训练的模型(在16个场景中训练)应用到新的场景中,而无需额外的训练。然而,它的性能比偶然的更糟,这表明了适应特定场景层的重要性。单个分支模型比从头开始的训练稍微快一些,但比我们的最终模型要慢得多。
D. Continuous Space
- 空间离散消除了对复杂系统动力学的处理,如电机控制中的噪声。在本节中,我们给出了经验结果:相同模型能够应对更具挑战性的连续空间。为了说明这一点,我们在一个大型客厅的场景中,训练了同一个目标驱动模型,我们的目标是通过一扇门到达阳台。我们使用与之前相同的4个动作(参见IV-C小节);然而,agent的移动和转弯是由物理引擎控制的。在这种情况下,该方法应该显式地处理力和碰撞,因为agent可能会被障碍物阻止或沿着重物滑动。虽然这个设置需要更多的训练帧(大约50M)来训练一个目标,但是相同的模型平均需要15步能到达门,而随机代理平均需要719步。我们在视频中提供了样本测试片段。
E. Robot Experiment
- 为了验证我们的方法对真实世界设置的推广,我们使用[53]修改的SCITOS移动机器人进行了实验(见图9)。我们在三种不同的设置下训练我们的模型:1)从零开始训练真实图像;2)只对场景特定层进行训练,对20个模拟场景进行通用层参数冻结;3)训练场景特定层和微调通用层参数。

VI. CONCLUSIONS
- 我们提出了一种用于目标驱动视觉导航的深度强化学习(DRL)框架。目前技术水平下的的DRL方法通常被应用到电子游戏和不模拟自然图像分布的环境中。这项工作是向更现实的设置迈出的一步。

相关文章推荐
- Target-Driven Visual Navigation In Indoor Scenes Using DRL 讲解
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- [深度学习论文笔记][Scene Classification] Learning Deep Features for Scene Recognition using Places Database
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文笔记:Personalized Tag Recommendation for Images Using Deep Transfer Learning
- 【论文精读】Deep Learning under Privileged Information Using Heteroscedastic Dropout
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
- Deep Reinforcement Learning for Dialogue Generation 翻译
- 论文引介 | Deep Reinforcement Learning for Dialogue Generation
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition--SPP-net论文笔记
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
- 深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 【翻译+原创】Deep Learning Face Representation from Predicting 10,000 Classes 论文笔记
- Human-Level Control Through Deep Reinforcement Learning论文解读
- 论文阅读笔记:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
- 场景识别“Learning Deep Features for Scene Recognition using Places Database”
- 零基础10分钟运行DQN图文教程 Playing Flappy Bird Using Deep Reinforcement Learning (Based on Deep Q Learning DQN
- Human-level control through deep reinforcement learning(中文翻译)