【论文翻译】ZERO-SHOT VISUAL IMITATION
摘要:目前主导范式依旧是依靠“专家行为”的强监督学习。我们追求一种无监督学习的模式来探索世界,并把经验提炼成目标导航策略,并具有“前向一致性损失”。策略在学习到了一组图像序列后开始模仿专家的行为。我们提出“zero-shot”方法:agent在训练期间无法接触到专家的行为。我们用了两个真实世界的实验来评估“zero-shot”:用Baxter-robot 做复杂绳索操作&用TurtleBot在新办公环境导航。通过在VizDoom环境的进一步实验,我们证明:更好的探索机制可以学习性能更好的策略。
-
1 .INTRODUCTION
“对专家演示进行模仿”指的是:“从原始感官输入来学习如何执行任务”的强大机制。当前主导范式是:人工移动or远程控制机器人来执行任务。专家在训练期间为任务提供多个这样的演示,同时以agent的视角产生成对的“observastion-action”数据。agent根据这些数据学习策略。这种依靠人工的强监督方法对专家来说很无聊乏味。并且每次机器人学习新任务之前,都需要专家提前做演示(手把手)。 - 取而代之的,是一种通用的方法:专家只需要以视频或者图片序列的方式给出环境的observation。agent根据视频自己推断出如何行动。在心理学中,这被称为观察学习。尽管有难度,但是这很有趣,毕竟通过这样的方式,专家更容易演示很多任务给agent。
- 对于一个没有任何先验知识的agent来说(除了最简单的情况外)仅仅通过观看演示来模仿一项任务是很困难的。问题来了:想要成功的模仿,agent应该拥有什么样的先验知识呢?人们做了许多工作:人工预定义一些“一定会从observation中推断出的状态”。然后agent根据这些状态来执行任务。不幸的是,计算机系统无法准确估计这些状态变量。
- 本篇论文,我们着力于一个agent在无监督的情况下探索环境,并把经验数据提炼成目标导向的策略。我们的agent通过一个函数预测一个从当前observation到goal的动作序列。我们称这个函数为goal-conditioned skill policy (GSP)。GSP通过这样的自监督学习方式:把agent在探索过程中到过的states标记为goal,把agent执行过的action标记为targets。在一个实例中,给出目标的observations,GSP可以推测出如何到达目标,从而一步步的完成模仿专家的任务。
- GSP的一个重要挑战是:不同states之间往往存在多条路径。我们使用forward consistency loss(前向一致性损失)来解决这个问题,这样做的原因是:“于大多数任务来说,实现目标比如何实现更重要”。为了实现这一点,我们首先学习这样一个前向模型:输入action和当前observation,输出下一个observation。我们使用前向模型的输出和下一个状态的真实observation的差分作为损失函数来训练模型。这种损失函数的效果是:对于一些采取了不同action但是到达了相同observation的情况,此时agent不会受到惩罚。考虑到达到不同目标需要不同的步骤数,我们提出:加入目标识别器(确定当前目标是否达到),与前向模型共同来优化GSP。GSP架构图,见图1。

- 我们给提出的方法起名为zero-shot是因为,agent在训练阶段和任务示范阶段都不接触到专家的action。相比之下,近期关于 one-shot imitation learning的研究在训练期间都需要充分的action知识和大量的专家示范。总的来说,我们提出的方法:(1)在学习过程中不需要任何外在奖励或专家监督 (2)只在推断过程中需要示范 (3)示范仅限于视觉的observation,而不是state-actions。总是,我们的agent不是通过模仿来学习,而是学会模仿。
- 我们用“TurtleBot办公室导航”和“Baxter执行绳索操纵任务”来在真实世界评估我们的工作。结果显示:我们提出的前向一致性损失在“打结”这个复杂任务上,准确率从36%提升到了60%。在导航试验中,我们让机器人在部分可见的办公室四周行驶,并且表明GSP可以推广到没见过的环境。此外,通过在VizDoom环境中进行导航实验,我们发现,在学习GSP的过程中,相比于使用随机探索,使用curiosity-driven的探索策略可以更准确的模仿演示。总体而言,我们的实验表明,前向一致的GSP可以用来模拟各种任务,而无需做出特定于环境或任务的假设。
2 .LEARNING TO IMITATE WITHOUT EXPERT SUPERVISION
S : {x1,a1,x2,a2, ...... xT } 是agent使用策略a = πE(s)探索环境时生成的“observations--actions对”。探索得到的数据用来学习GSP,具体方法是:输入为(xi,xg),输出为动作序列(aτ : a1,a2...aK) ,动作序列从当前observation xi 到达 目标observation xg 。其中,aτ =π( xi , xg ; θπ )。xi,xg是从S从采样得到的。
xi ,xg从S中采样。行动的步数K也是从模型中推断出来的。我们把 策略π 用参数为θπ 的深度网络表示,目的是表达observation到action的复杂映射。π可以看做是逆动力学模型的多步衍生物,或者对应于通用值函数的一个策略。注意,xg不一定是任务的最终目标,也可以是一个中间子目标。
把需要模仿的任务以图像序列的形式提供—D : {x1d , x2d , ..., xNd },专家演示任务的同时,这个序列被记录。序列在时间上可以是暂时密集的也可以是稀疏的。agent通过来模仿序列D来学习策略GSP-π。agent起始位置在x0,依据策略π(x0,x1d;θπ)来选择第一个动作。执行策略预测出的动作后,得到的observation称为x′0。因为接近 x1d 可能需要执行多个action,agent会循环的查询目标识别网络来确认当前observation是否接近目标。如果当前observation和目标不符,agent会执行动作 a = π( x′0 , x1d ; θπ )。上述过程重复进行,直到目标识别器显示当前observation已经接近goal,或者已经到达步数值上限。当agent接近x1d后,agent再把目标设置为x2d ,并且重复这个过程。当被模仿序列中的所有observation都被访问过之后,agent停止。
注意:上述方法中专家不需要向agent传达“哪一个action应该被采用”。接下来的部分,我们会描述:如何学习GSP / 前向一致性损失 / 目标识别网络 ,以及一些baseline方法。
2.1 LEARNING THE GOAL-CONDITIONED SKILL POLICY (GSP)
我们先介绍”one-step-GSP“,接下来再把他拓展到”variable length multi-step skills“。one-step版本的轨迹形式是:(xt,at,xt+1)。策略aˆt= π(xt,xt+1;θπ) 是由最小化标准交叉熵损失函数 L(at,aˆt) = p(at| xt, xt+1)*log(aˆt) 得到的。其中,aˆt是预测出的动作分布。尽管我们没有接触真实的动作分布,我们从探索阶段中抽样从而对真实动作分布at进行经验近似。为了最小化交叉熵函数,通常把p假设为一个在at处的狄拉克δ函数。但是,当p就是高维且多路径(多种选择)的时候,这个假设就不成立了。如果我们在假设p为δ函数的函数下去优化神经网络,会出现这样的情况:“同样的输入对应不同的优化目标”,这导致了梯度方差很高,神经网络难以学习。多路径问题之所以出现,是因为我们的问题中有许多actions可以导航到相同的goal。多路径的问题很重要,因为在轨迹越长的时候,从起点到终点的可行路径越多。此外,需要大量的样本才能获得“高维多路径的动作分布”的较好的经验估计。2.2 FORWARD CONSISTENCY LOSS
- 解决多路径问题的方法之一是:使用类似自动编码器的东西。然而实际中,为每个可行路径都获取足够数据是不可能的。本文中我们提出了一种替代方案:只关心是否到达终点而不关心怎么样到达终点。我们不再对action进行惩罚使得预测动作逼近真实动作,我们通过这样的方式来学习GSP:“最小化xˆt+1 (执行”策略aˆt=π(xt,xt+1;θπ)预测出动作“,得到的observation)和xt+1(执行真实的动作at,得到的observation,这部分可以直接由训练数据得到)之间的距离,尽管预测的行为和真实行为是不同的action,只要他们导向相同的observation,那么就不会受到惩罚”。虽然这个方法无法显示维护环境中所有可行路径,但是这样可以降低梯度的方差,有利于学习。我们称这种惩罚为“前向一致性损失”。
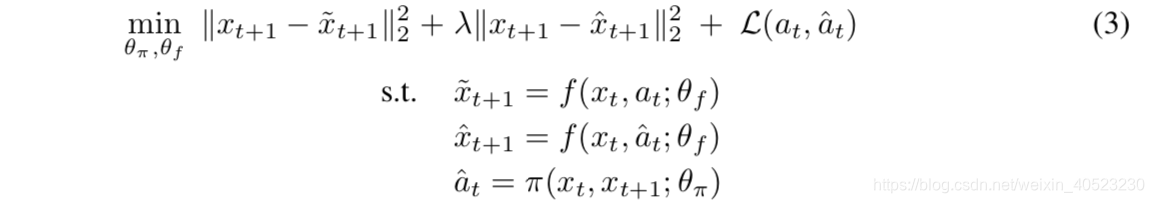

φ(.)表示一个具有参数θφ的神经网络。多步GSP需要的步数是可变的,取决于目标识别器。注意,若φ(x)=x,那么该目标就直接简化为之前使用observation作为输入的模型。我们在VizDoom 3D导航中分析了基于特征空间的预测,并在绳索实验和office实验中使用observation空间。
多步前向一致性GSP-πm通过这样的方法实现:使用一个循环神经网络,每一时间步的输入为:
(1) 当前状态xt和目标状态xT的特征表示:φ(xt) and φ(xT )
(2) 上一个时间步的动作at-1
(3) 循环单元的内部隐藏层表示ht-1
(4)当前预测的动作结果aˆt 。
注意,每个时间步输入的之前预测的动作at-1可能是冗余的,因为隐藏层的潜在的表示已经在维护轨迹历史了。尽管如此,显示地为这段轨迹历史建模是有益的。这个公式等效于建立了一个联合诸多动作的自回归模型:“每个时间步计算P(at|x1,a1,...at−1,xt,xg)”。未来还可以考虑继续努力建立一个前向多步模型。
2.3 GOAL RECOGNIZER
- 我们训练目标识别网络来确定是否已经达到目标(因此允许agent以不固定的步数到达终点)。目标识别器很重要在agent经过中间状态的时候很重要,否则累积误差会产生和演示的分歧。在给出真实物理环境的前提下实现目标识别器很简单,但当使用视觉observation时很困难。除了视觉识别本身带来的困难,observation依赖于agent本身的动力属性,也使得目标识别复杂化,比如“相同的目标在前进或转弯时可能呈现出不同。”
2.4 ABLATIONS AND BASELINES
- 我们提出的GSP由以下部分组成:(a) 循环变长策略网络 ,(b) 在循环中显式编码以前的动作 ,(c) 目标识别器,(d) 正向一致性损失函数,(w)在特征空间而不是原始observation空间中学习正向动力学模型。我们系统地分析了这些前向一致性GSP的组成部分,定量的评估这些组成部分的重要性,然后与之前一些视觉模拟的方法进行比较。

3 . EXPERIMENTS
- 我们进行绳索实验&办公室实验&虚拟导航实验。关键的需求是可以在未接触过的环境中对新目标进行导航,并且对无关的环境干扰鲁棒,比如“让机器人模仿一个在探索过程中没见过的绳结”,或者“在虚拟or显示导航中,测试新的目标”。
3.1 ROPE MANIPULATION
让机器人操纵非刚性可变形物体是一个挑战。即使是人类也得看着实验或者收到清晰的指令才能完成绳索任务。我们进行这样一个实验:机器人只通过观察人类的演示来实现操纵绳索。我们使用Nair et al. (2017)的数据:baxer操作绳索。探索过程中,机器人和绳子交互,使用一个pick and place原语,选择绳索上的一个随机点,并以随机选择的长度和方向替换它。收集60K的形如(xt , at , xt+1 )的交互动作对,用来训练GSP。探索阶段中没有打结这一环节,所以GSP必须泛化并能模仿人类的演示。3.2 NAVIGATION IN INDOOR OFFICE ENVIRONMENTS
- 命令机器人在室内办公环境中移动的一种很自然的方式是:让它靠近某个指定的位置。本文中,我们不是用语言指令来控制机器人,而是通过向机器人展示一个目标图像,或者是一系列指向目标的图像,来与机器人进行交流。在这两种情况下,机器人都需要自主决定移动目标的电机指令。我们使用turtlebot2进行导航,使用机载摄像机感知RGB图像。为了学习GSP,设计了一个不需要人工监督的自监督数据收集方案。该机器人从一座学院楼的两层中采集了大量的导航轨迹,总共包含230K的交互数据,形如(xt,at,xt+1)。然后,我们将学习到的模型部署到一个建筑的单独楼层,该楼层的纹理和家具布局有很大的不同。我们通过这种方式对视觉模拟进行测试。补充材料——A.2节详细描述了GSP的机器人设置、数据收集和网络结构。
(2)VISUAL IMITATION :之前的段落中,机器人可以在同一个房间寻找到目标。然而,我们的agent无法达到遥远的目标,如在其他房间设立一个目标。在这种情况下,专家可能会传达指令,比如走到门口,向右转,走到最近的椅子上等等。代替语言指令,在我们的设置中,我们提供了一系列地标的图像来传达同样的高级思想。当专家将机器人从起点移动到目标位置时,这些具有里程碑意义的地标图像就被机器人的摄像机拍下来。然而,请注意,专家没有必要控制机器人去捕捉图像,因为我们没有利用专家的动作,而仅仅利用图像。在演示过程中,我们并没有在每次操作之后都记录图像,而是只提供了第五张图像。这种选择背后的基本原理是,我们希望对演示进行稀疏抽样,以最小化代理对专家演示的依赖。这种子抽样(如图5所示)降低了任务复杂性。
我们对两次专家演示(即迷宫演示)进行多次运行评估,机器人应该在迷宫般的路径中导航,并进行循环演示,机器人应该按照演示图像的指示做一个完整的循环。循环演示比迷宫更长,也更困难。相对于演示,我们从不同的起始位置和方向启动agent。每个方向都被初始化,这样演示初始框架的任何部分都不可见。结果如表2所示。当我们对每一帧进行采样时,来自运动的方法和经典结构都可以用于跟踪演示。然而,在五次采样率下,基于筛选的特征匹配方法不起作用,ORBSLAM2未能生成map,而我们的方法是成功的。注意,提供稀疏的地标图像而不是密集的视频,增加了视觉模拟任务的健壮性。特别是,考虑到环境在演示过程中所发生的变化。由于不需要代理逐帧匹配每个演示图像,它对环境的变化就不那么敏感了。
3.3 3D NAVIGATION IN VIZDOOM
- 到目前为止,我们已经在真实的机器人场景中评估了我们的方法。为了通过大规模实验进一步分析我们的方法的性能和鲁棒性,我们在模拟VizDoom环境中实验和前一节相同的导航任务。我们的目标是测量:(1)每个方法的鲁棒性与适当的误差 (2)自监督数据收集策略对视觉模仿性能的影响 (3)特征空间中前向一致性损失建模与原始视觉空间建模的定量差异。在VizDoom中,我们采用两种探索策略来收集数据:随机策略和好奇心驱动探索。假设是,如果机器人接收的初始数据是由一个比随机的更好的探索策略得到的,那么这将最终帮助机器人更好地模仿长距离演示。我们的环境总共由两张地图组成。我们在一张地图上训练,从5个不同的起始位置来探索收集数据。为了进行验证,我们收集了5个人类的专家演示,它们的布局与训练中的相同,但是纹理不同。为了实现zero-shot的泛化,我们收集了5个具有新纹理的人类演示。关于数据收集和训练设置的详细信息请参阅补充资料A.3节。
Metric 在给定机器人图像序列的情况下,我们展示机器人到达的最大距离的中值。到达的最大距离是agent连续到达的最远地标点的距离,不遗漏任何中间地标。测量达到的最远的地标并不能反映它达到的效率。因此,我们进一步测量agent的效率,即agent所采取的步骤数与人类演示中所显示的步骤数之比,以达到最远的连续地标。
Visual Imitation 这里的任务与真正的机器人导航中的任务相同,在这个任务中,agent接受一个稀疏的图像序列。结果见表3。我们发现好奇心探索相对于随机探索策略,显著提高了所有方法的最终模仿性能。拥有前向正则化的基线GSP模型相比于一致性损失模型最终在新的布局下过拟合。相比之下,我们的前向一致的GSP模型在推广到具有新纹理的新地图方面优于其他方法。这说明前向一致性损失不仅仅是对策略的特征做了正则化。即使基于图像的模型和特征空间模型在训练环境上表现相似,训练前向一致性损失也进一步增强了泛化能力。
5 .DISCUSSION
- 在这项工作中,我们提出了一种仅从视觉observation模仿专家演示的方法。与大多数模仿学习的工作相比,我们从不需要专家的行动。其关键思想是利用自监督探索收集的数据来学习GSP。然而,勘探数据限制了学习到的GSP的质量。例如,我们在现实世界的导航机器人上部署了随机探索,这意味着机器人无法模仿跨越房间的轨迹。因此,学习到的GSP无法在不给出中间子目标的情况下,无法导航到另一个房间内的目标图像。agent学会了沿着走廊走,在房间之间转换纯粹是出于好奇。在这样的结构化数据上对GSP进行训练,可以使代理具备更有趣的搜索行为,例如穿过房间寻找目标。一般来说,使用更好的探索方法来训练GSP可能是推广zero-shot模仿的有效方向。
-
A.2 NAVIGATION IN INDOOR OFFICE ENVIRONMENTS
机器人设置:TurtleBot2 & Kobuk轮式底座 & Orbbec Astra摄像头 。动作空间有四个动作:前,左,右,停住。前进的动作大约是10cm的前进平移,转弯动作大约是14-18度的旋转。这些数字因速度而变化。一台强大的车载笔记本电脑被用来处理图像和推断电机指令。对默认的TurtleBot设置做了几处修改:电池底座换成了更耐用的电池,NVIDIA Jetson TK1预装板换成了功能更强大的GigaByte Aero笔记本电脑和配套的便携式充电电源。
- 自监督数据搜集: 我们设计了一种不需要人工监督的自动数据采集自监督方案。在我们的方案中,机器人首先对四个动作中的一个进行采样,然后是选择动作的次数(即动作重复)。对无op动作的抽样概率为0.05,对其他三个动作的抽样概率为相等。如果选择了no-op操作,则重复1~2次。选择了其他op,则重复1~5次。机器人自主地重复了这个过程,并从一座学术楼的两层收集了230K的互动信息。如果机器人撞到一个物体,它会进行重置操作,首先向后移动,然后以90-270度的采样一个角度,并左右转动。建筑的一个单独的楼层,有明显不同的家具布局和视觉纹理,然后用来测试学习的模型。
- 实施细节 :自监督探索收集到的数据用来训练我们的循环前向一致性GSP。我们的基础架构是用ImageNet预训练的ResNet-50。输入是图像,输出是机器人的动作。正向一致性模型首先经过预训练,然后联合GSP,进行端到端微调。前向模型的权重是0.1,用5e − 4学习率的adam对目标进行最小化。
A.3 3D NAVIGATION IN VIZDOOM
- 自监督数据搜集:我们的环境由两张地图组成。一个映射用于训练和验证,验证时具有不同的纹理。第二张地图有不同于前者的纹理,用于测试泛化。对于好奇心探索和随机探索,我们总共收集了150万帧,每个帧的动作重复4次,都是在标准的DoomMyWayHome地图中收集的。三分之二的数据来自随机房间reset,三分之一的数据来自一个固定房间reset。好奇心策略是:一半是抽样的,一半是贪婪的(0% greedy policy random-room reset, 25% sample policy random-room reset, 25% sample policy fixed-room reset, and 10% greedy policy fixed-room reset)
ImplementationDetails 训练模型的batch-size为64,Adam学习率为1e-4,每个batch隔5~15个action选一个地标。observation是单通道,48*48。所有的模型都使用了同一个目标识别器,它是在好奇心数据上训练的。对于前向正则器、基于像素的前向一致性模型,基于特征的前向一致性模型的超参数,我们选择了最佳系数{0.01, 0.05, 0.1}。

- [论文阅读] Low-shot Visual Recognition by Shrinking and Hallucinating Features
- Hierarchical Convolutional Features for Visual Tracking(CF2)论文翻译
- Single Shot MultiBox Detector论文翻译——中文版
- 读论文-DARLA:Improving Zero-Shot Transfer in Reinforcement Learning
- SSD: Single Shot MultiBox Detector 论文翻译
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文阅读理解 - Zero-shot Image Tagging by Hierarchical Semantic Embedding
- 目标追踪——相关滤波追踪论文翻译:Visual Object Tracking using Adaptive Correlation Filters
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- jQuery Visual Studio 2008 智能代码提示文件简体中文翻译
- 【NIPS最佳论文引发深度学习论战】AlphaZero能击败冷扑大师吗?No(Science论文)
- [论文笔记]DSSD : Deconvolutional Single Shot Detector
- CVPR2013一些论文集合供下载(visual tracking相关)
- 论文翻译:Deep Occlusion Reasoning for Multi-Camera Multi-Target Detection
- Spark学习(一)—— 论文翻译
- 经典论文翻译导读之《Google File System》
- 【AlphaGo Zero】AlphaGo Zero横空出世,DeepMind Nature论文解密不使用人类知识掌握围棋
- 论文翻译:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Faster R-CNN论文翻译——中英文对照
- ZM-Net: Real-time Zero-shot Image Manipulation Network 论文理解