论文翻译- Residual Networks Behave Like Ensembles of Relatively Shallow Networks
-
原文链接:
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/303409435
-
标题:Residual Networks Behave Like Ensembles of Relatively Shallow Networks
摘 要 :本文提出了一个新的解释,残差网络可以被看作是许多不同长度的新的网络的解释。而且,残差网络似乎可以在训练中只使用短的路径实现很深的网络。为了支持这个观测,我们将残差网络重写为路径的显示集合。与传统模型不同,残差网络的路径长度不同。此外,一份研究表明,这些路径显示了它们之间并不是强烈依赖的。最后,也是最令人惊讶的是,大多数路径都比预期的要短,而且在训练过程中只需要短路径,因为较长的路径不会产生任何梯度。例如,在一个有110层的残差网络中,大多数梯度来自只有10-34层的路径。我们的结果揭示了一个似乎可以帮助训练非常深网络的关键特征:残差网络通过引入短路径来避免梯度消失的问题,这种短路径可以在非常深的网络中传递梯度。
1 . Introduction 介绍:
大多数现代计算机视觉系统遵循一个熟悉的体系结构,处理从低级特性到特定任务的高级特性的输入。最近提出的“残差网络[5,6]”从三个方面挑战了这一传统观点。首先,引入了特定的“skip-connections”层,允许数据从任何层流向后续的层。这与传统的严格顺序管道形成了鲜明对比。其次,“skip-connections”层产生的网络比之前的模型深两个数量级,最多有1202层。这与alexnet甚至是生物系统的结构完全不同,可以在几层之间捕获复杂的概念。第三,在最初的实验中,我们观察到在测试时,从残差网络中移除单独的层并不会显著影响整体的性能。这很令人惊讶,因为从传统架构(如VGG[18])中删除一个单独的层会导致性能的显著损失。
在这项工作中,我们调查研究了这些差异的影响。为了解决“skip-connections”层的影响,我们引入了一个阐明的观点。这种新的表示方式表明,残差网络可以看作是多个路径的集合,而不是单个深层网络。此外,残差网络的“the perceived resilience“提出了问题:路径是否相互依赖,或者它们是否显示一定程度的冗余。为了找到答案,我们做一个研究。结果表明,从某种意义上讲,通过“删除层或者通过重新排序层”来破坏路径,只会对性能产生温和而平稳的影响。最后,我们研究了残差网络的深度,与传统模型不同,通过残差网络的路径长度不同。路径长度的分布遵循二项分布,这意味着在一个有110层的网络中,大多数路径只有大约55层深。此外,在训练过程中,我们发现大部分梯度来自于更短的路径,即10-34层。
这揭示了一种局面。一方面,随着层数的增加,残差网络的性能得到了提高。然而,另一方面,残差网络可以被看作是许多路径的集合而有效的路径又是相对较浅的。我们的结果可以提供一种解释:残差网络不会通过“保护整个网络的整个深度”来解决梯度消失问题。更确切的说,残差网络通过缩短有效路径的长度来激活深层网络。就目前而言,短路径似乎仍然是训练非常深的网络的必要条件。
在本文中,我们做出以下贡献:
我们介绍了分解视图,它说明了残差网络可以看作是许多路径的集合,而不是单个超深网络。
我们进行了一些研究,以表明这些路径并不相互依赖,即使它们是共同训练的。此外,它们表现出类似于集体的行为,因为它们的性能与有效路径的数量平稳相关。
研究了残差网络中的梯度流,发现在训练过程中只有短路径对梯度有贡献,在训练过程中并不需要有很深的路径。
2 . Related Work 相关工作:
顺序和层次的计算机视觉管道 ——长期以来,视觉处理一直被认为是一个从简单到复杂的特征分析的层次化过程。这种形式是建立在“接受域”的发现之上的,接受域将视觉系统描述为一个层次系统和前馈系统。早期视觉区域的神经元具有小的接受区,对基本的视觉特征如边缘和条状敏感。层次结构更深一层的神经元捕捉基本的形状,甚至更深一层的神经元对完整的物体做出反应。从早期的神经网络如Neocognitron,到传统的Malik和Perona手工制作的feature管道,再到卷积神经网络,这个组织在计算机视觉和机器学习文献中得到了广泛的应用。最近非常深入的神经网络的强有力的结果导致人们普遍认为是神经网络的深度决定了它们的表达能力和表现。而在本文的工作中,我们表明残差网络不一定遵循这一传统认识。
残差网络 ——残差网络是一种神经网络,每一层由“残差模块 fi ”和跳过 fi 的“skip connection”组成。由于残差网络中的层可以包含多个卷积层,因此在本文的其余部分中我们将其统称为“残差块”。为了符号的清晰,我们省略了最初的预处理和最终的分类步骤。以 y i−1 为输入,递归定义第i个块的输出为
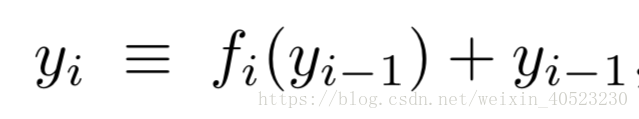
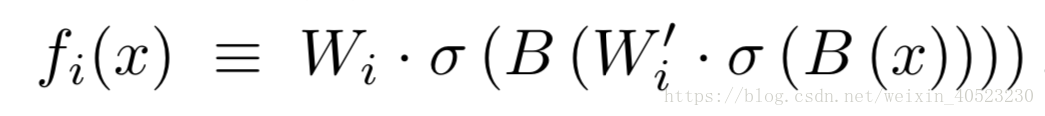
Highway networks ——残差网络可以看作是公路网络的一个特例。 公路网各层的输出定义为
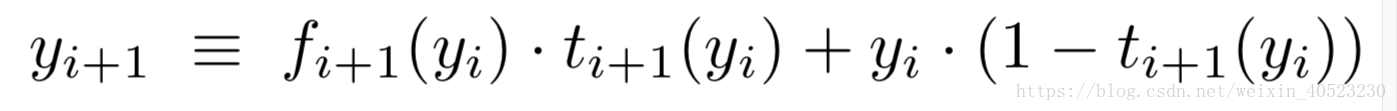
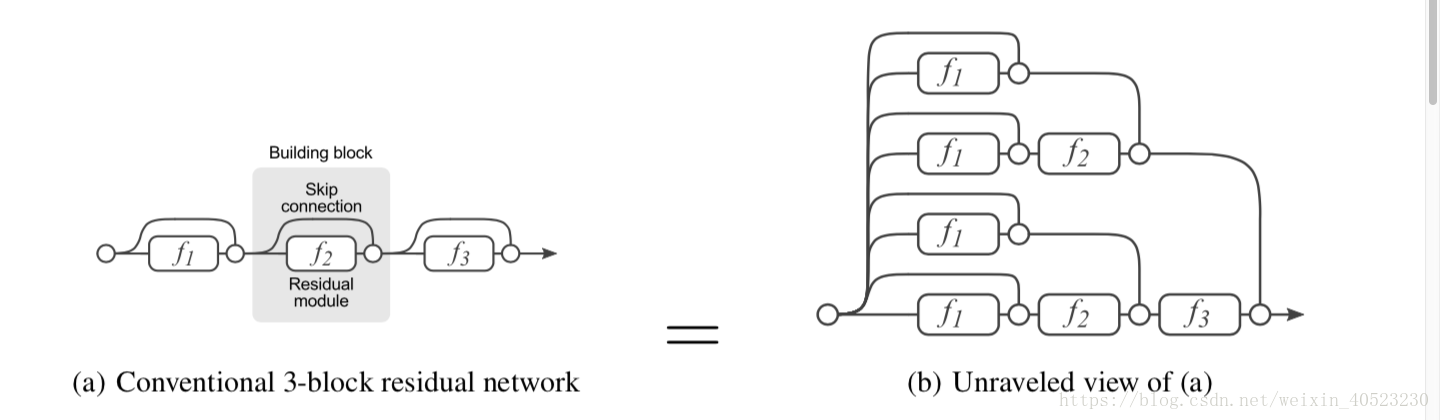
图1:残差网络常规表示为(a),是式(1)
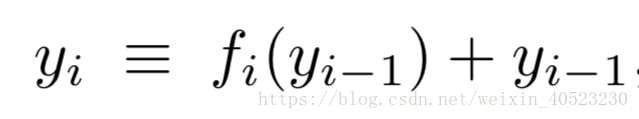
Investigating neural networks研究神经网络 —— 一些调查研究试图更好地理解卷积神经网络。例如,Zeiler和Fergus将卷积滤波器可视化,以揭示单个神经元所学习的概念。此外,Szegedy等人还研究了神经网络学习到的函数,以及在对抗样本的输入中发生的微小变化是如何会导致输出的巨大变化。在这项研究中,与我们工作最接近的研究来自Yosinski等人,他们在AlexNet上进行研究。他们发现早期的层表现出很少的共同适应,而后期的层表现出更多的共同适应。这些论文和我们的论文都有一个共同的主线:都是在探索神经网络性能的具体方面。而在我们的研究中,我们将重点研究神经网络的结构特性。
Ensembling —— 从神经网络的早期开始,研究人员就使用简单的集成技术来提高性能。虽然过去使用了boost技术,一个简单的方法是在一个投票方案中安排一个神经网络委员会,委员会最后输出预测的平均值。在一些比赛中,表现最好的选手几乎都是事后才想到这个技巧。一般来说,作为整体所拥有的一个关键特征是与成员数目有关的平滑的性能。特别地,随着整体规模的增加,额外成员带来的性能增加会变得更小。尽管他们不是严格的整体,但我们显示残差网络也有类似的表现。
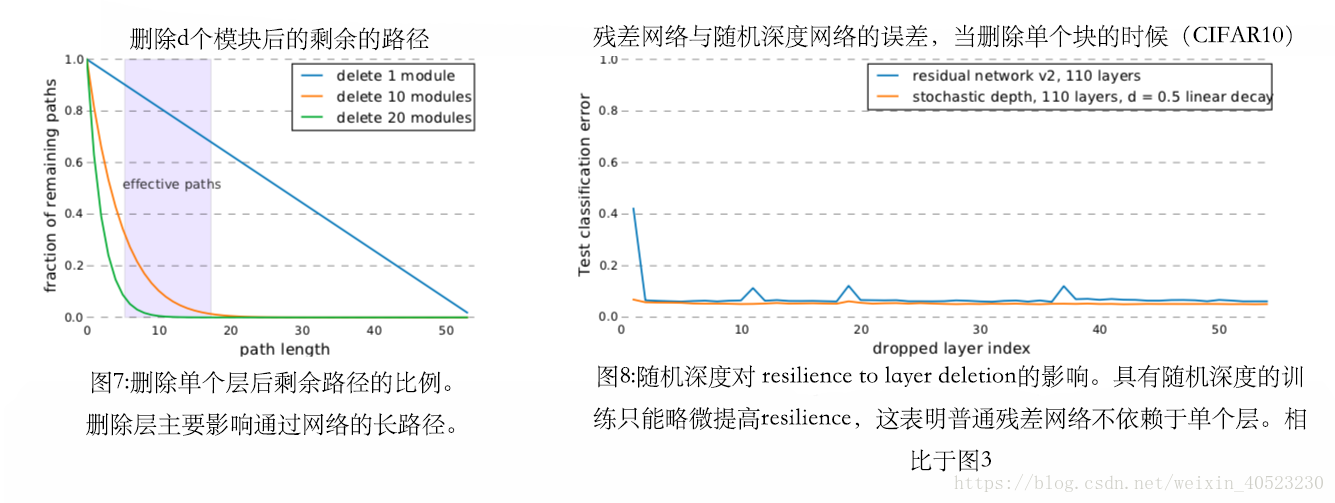
Dropout —— Hinton等人的研究表明,在训练过程中丢失单个神经元后得到的网络,效果相当于指数级多个网络的平均水平。在本质上类似于用随机深度训练一组网络,训练时随机丢掉一组网络层。本文中,我们展示了一种不需要特殊技巧的训练策略,例如随机深度训练来丢弃层。在不影响性能的情况下,可以从普通的残差网络中删除整个层,这表明它们之间没有很强的依赖性。
3. The unraveled view of residual networks 残差网络的分解观点:
- 为了更好地理解残差网络,我们引入了一种公式,使其更容易理解它们的递归性质。对于一个包含三个building blocks的残差网络,从输入 y0 到输出 y3。方程(1):
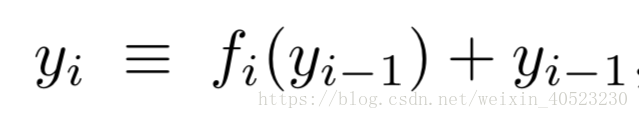 递归的给出了残差网络的定义。每个阶段的输出是两个子项的组合。通过将递归展开成指数数量的嵌套项,我们可以使残差网络的共享结构更加明显,具体方法是在每个替换步骤中展开一个层。
20000
递归的给出了残差网络的定义。每个阶段的输出是两个子项的组合。通过将递归展开成指数数量的嵌套项,我们可以使残差网络的共享结构更加明显,具体方法是在每个替换步骤中展开一个层。
20000
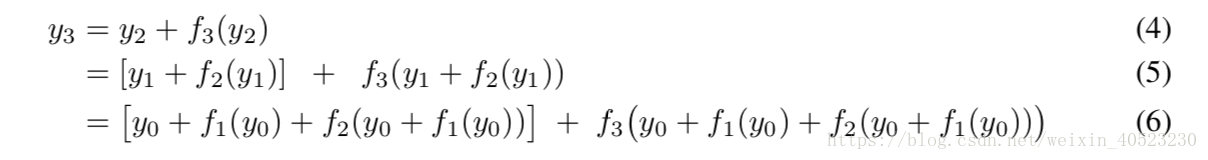 我们在图1 (b)中图形化地说明了这个表达式树。由于功能模块中的下标表示权重共享,此图相当于原残差网络的公式。该图清楚地表明,数据沿着从输入到输出的许多路径流动。每条路径都是一个独特的配置模块可以选择流入,也可以跳过。可以想象,每一个存在于网络中的独特路径可以通过一个二进制代码 b ∈ { 0,1 }n 被索引,其中n是网络中残差模块的数量。如果输入流通过残差模块fi,则bi = 1,如果输入跳过残差模块fi,则bi = 0。由此可见,残差网络有 2的n次方 条路径连接输入层和输出层。
我们在图1 (b)中图形化地说明了这个表达式树。由于功能模块中的下标表示权重共享,此图相当于原残差网络的公式。该图清楚地表明,数据沿着从输入到输出的许多路径流动。每条路径都是一个独特的配置模块可以选择流入,也可以跳过。可以想象,每一个存在于网络中的独特路径可以通过一个二进制代码 b ∈ { 0,1 }n 被索引,其中n是网络中残差模块的数量。如果输入流通过残差模块fi,则bi = 1,如果输入跳过残差模块fi,则bi = 0。由此可见,残差网络有 2的n次方 条路径连接输入层和输出层。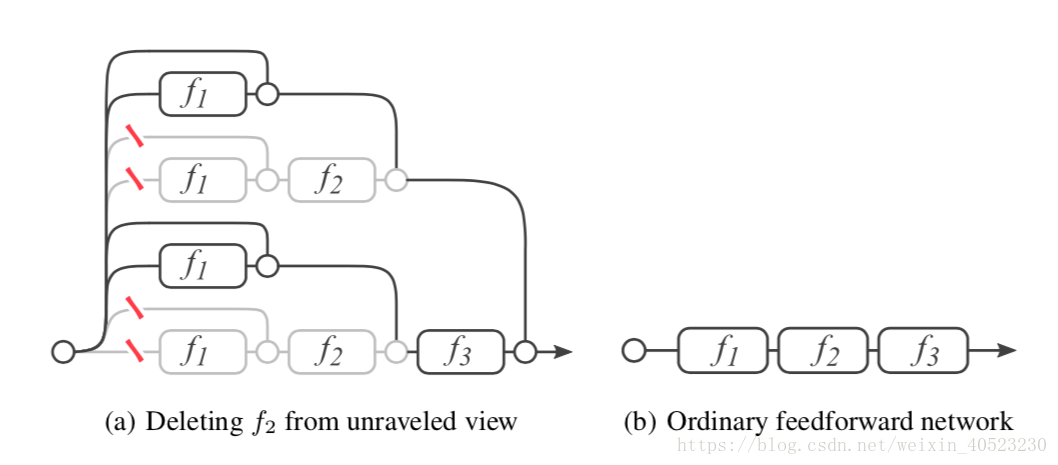
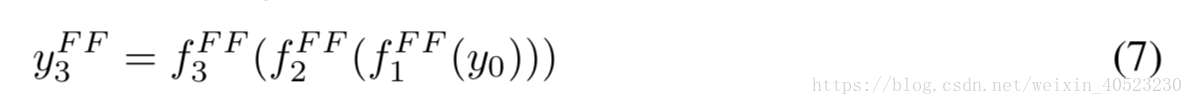 ,其中
,其中
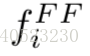 通常是一个卷积层后接BN层和ReLU层。在这些网络中,每个
通常是一个卷积层后接BN层和ReLU层。在这些网络中,每个
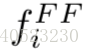 只从单个路径配置中获取数据,即输出
只从单个路径配置中获取数据,即输出
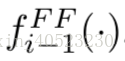 。
。4 . Lesion study
- 在本节中,我们使用三个实验表明,残差网络中的路径并不存在很强地相互依赖,并且它们表现得像一个整体。所有实验均在CIFAR-10数据集上进行。在ImageNet上的实验表现出了类似的结果。我们用标准的训练策略,数据增强和学习率策略来训练残差网络。在我们的CIFAR-10实验中,我们利用在第一步使用了BN的“预激活”模块训练了一个110层(54模块)残差网络。对于ImageNet,我们使用200层(66个模块)。值得注意的是,我们没有使用任何特殊的训练策略来适应这个网络。特别地,我们在训练中没有使用任何扰动,例如随机深度等。
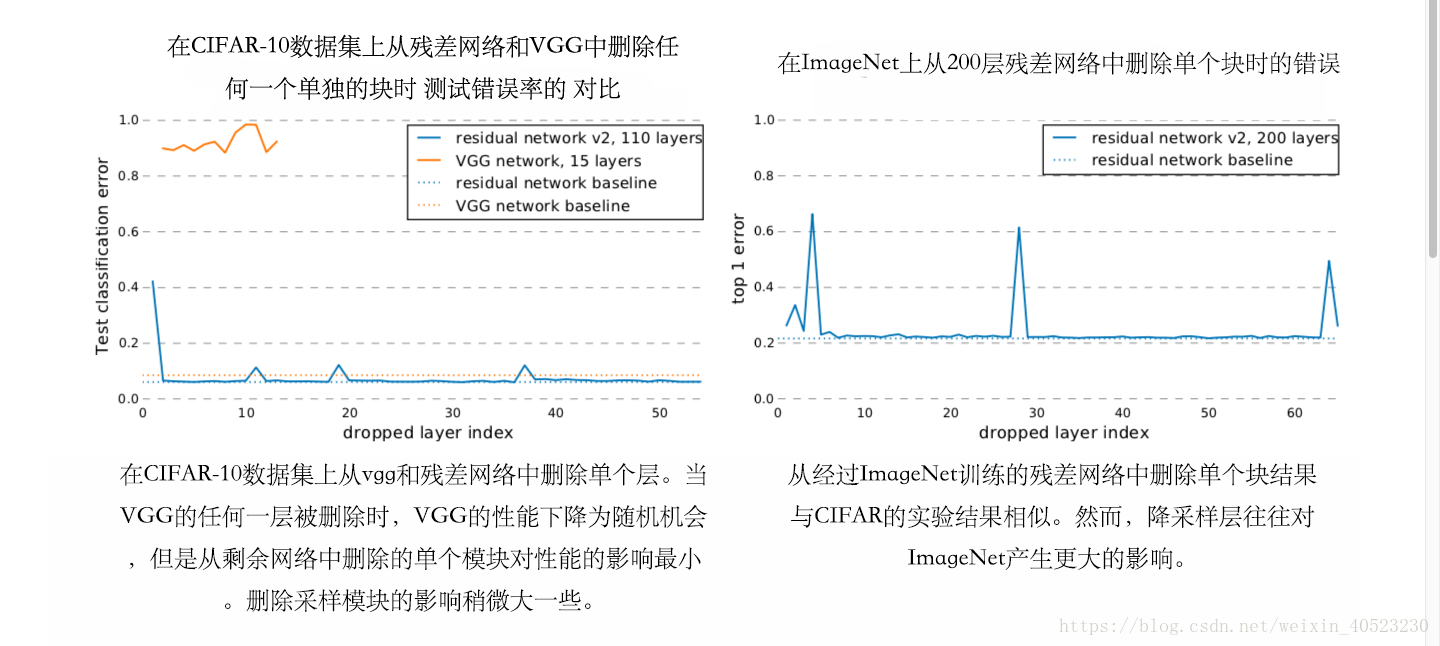
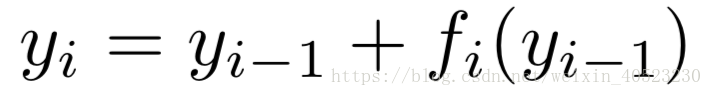 改为
改为
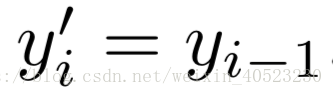 。我们可以通过改变移除的残差模块来衡量每个building block的重要性。与传统的卷积神经网络相比,我们训练了一个具有15层的VGG网络,将所有层的通道数设置为128个,以允许删除任何层。
。我们可以通过改变移除的残差模块来衡量每个building block的重要性。与传统的卷积神经网络相比,我们训练了一个具有15层的VGG网络,将所有层的通道数设置为128个,以允许删除任何层。- 我们已经证明了这些路径并不依赖于彼此,接下来我们会研究这些路径的集合是否表现出了类似于集体的行为。集体的一个关键特征是:集体的性能平稳地取决于成员的数量。
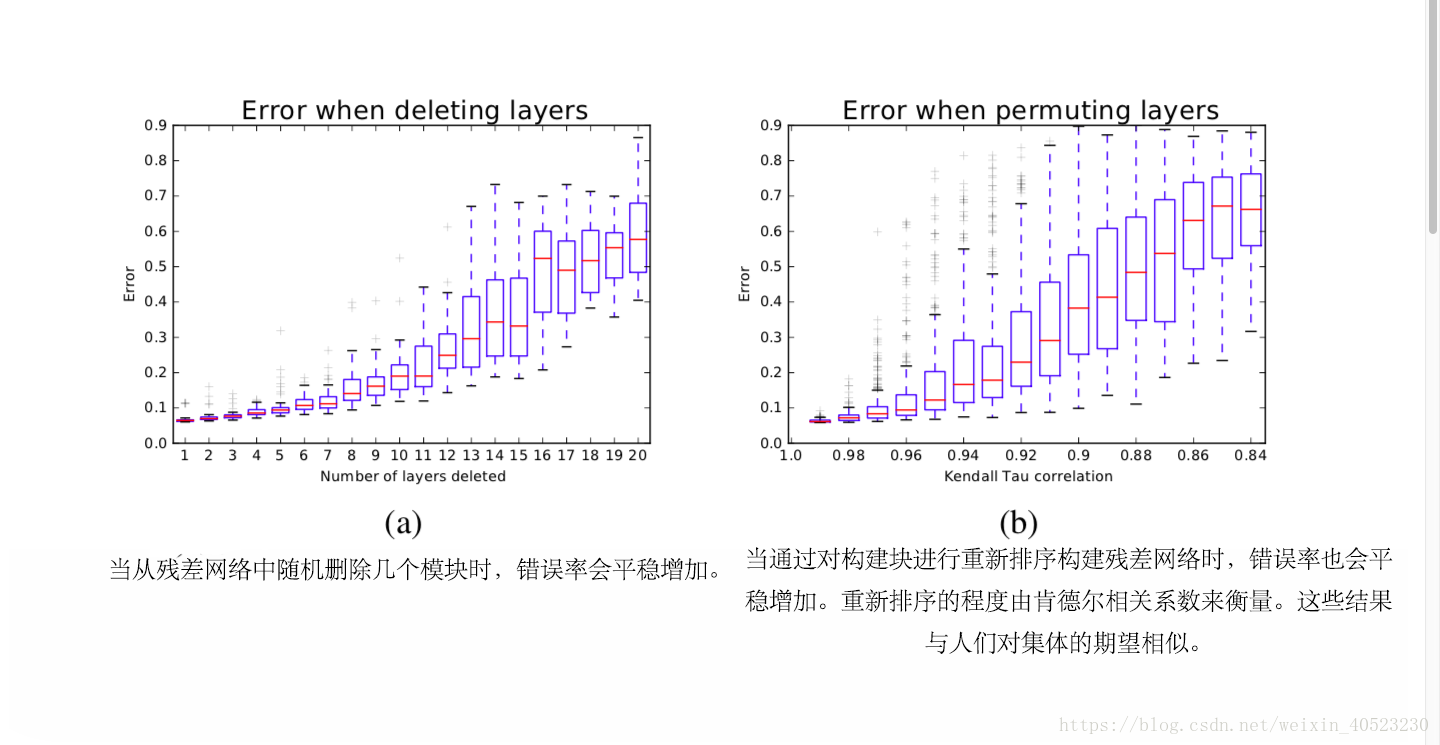
- 我们之前的实验仅仅是关于删除层,这就产生了从网络中移除路径的效果。在这个实验中,我们考虑通过重新排列构建块来改变网络的结构。这样做的效果是:删除一些路径并插入在训练过程中从未看到过的新路径。特别是,它在底层转换前移动高级的转换。
5 . 残差网络中短路径的重要性
- 现在我们已经看到,残差网络有很多路径,它们不一定相互依赖,我们研究它们的特征。
路径长度的分布 :并不是所有残差网络的路径都具有相同的长度。例如,有一条路径穿过所有模块,而n条路径只穿过一个模块。根据这一推理,所有残差网络可能的路径长度的分布遵循二项分布。因此,我们知道路径长度与n/2的均值密切相关。图6 (a)显示了带有54个模块的残差网络的路径长度分布;超过95%的路径通过了19到35个模块。
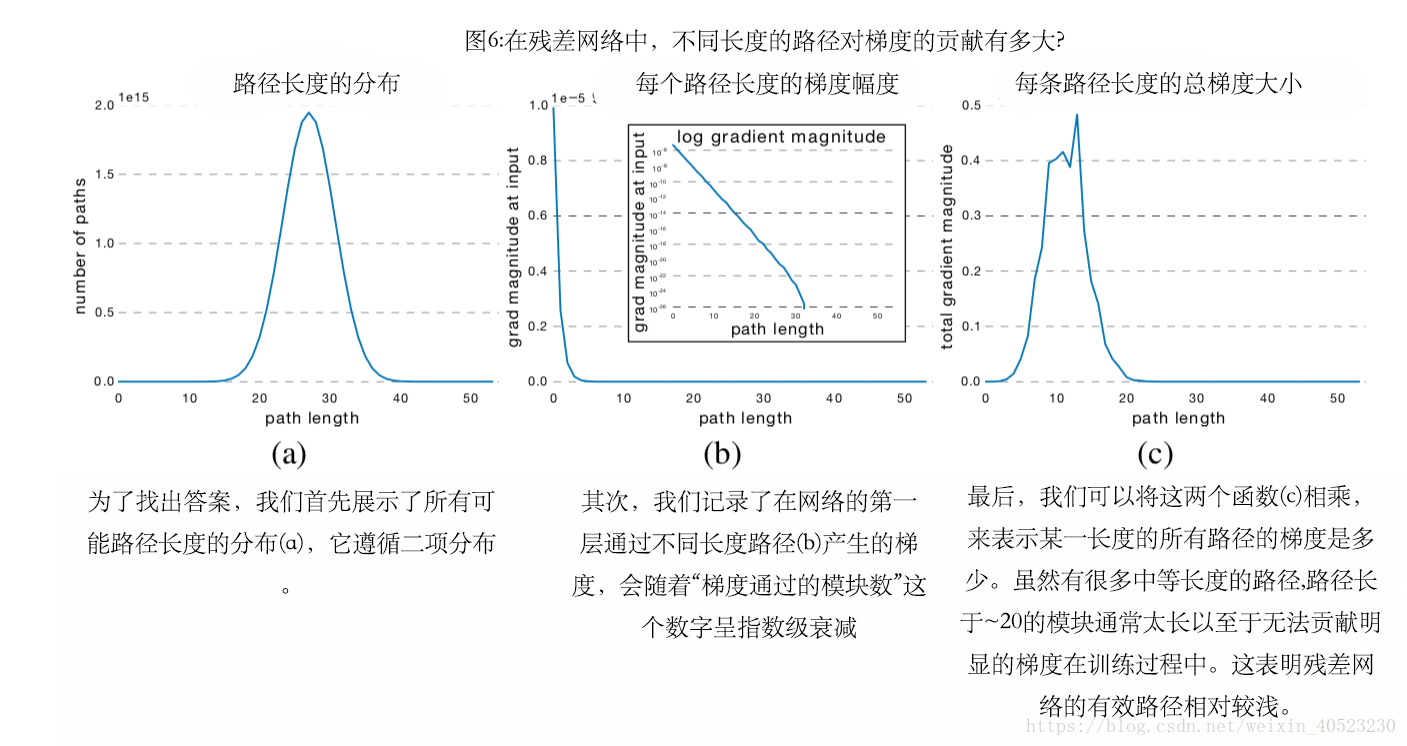
残差网络中的梯度消失 :通常,数据沿残差网络中的所有路径流动。然而,并不是所有的路径都传递了相同的梯度。其中,路径长度影响了反向传播过程中的梯度幅度[1,8]。为了实证研究梯度消失对剩残差网络的影响,我们进行了以下实验。训练具有54个building block的网络,我们采样一个特定长度的路径并且测量到达输入端的梯度的norm。为了采样长度为k的路径,我们首先对整个网络以前馈的方向送入一个batch的数据。在反向传递过程中,我们随机抽取k个残差模块。对于这k个块,我们只通过残差模块传播;剩下的n−k个块,我们只通过skip connection传播。因此,我们只测量长度为流经k个残差模块的单条路径的梯度。我们对每一个长度的k进行了1000次测量,使用的是训练集中的随机批次。结果表明,路径的梯度随其在反向传递中通过的残差模块的数量呈指数递减,如图6 (b)所示。
残差网络的有效路径相对较浅 : 最后,我们可以利用这些结果来推断在训练过程中,较短还是较长的路径对梯度的贡献最大。为求各长度路径所贡献的梯度幅值,我们将每个路径长度的频率乘以期望的梯度大小,结果如图6 (c)所示。令人惊讶的是,几乎所有在训练期间的梯度更新都来自经过5到17个模块的长度的路径。这些是有效路径,尽管它们只占这个网络中所有路径的0.45%。与网络总长度相比,有效路径相对较浅。
为了验证这个结果,我们从头重新训练一个“在训练过程只使用有效路径”的残差网络。这确保了长路径不被使用。如果重新训练的模型与训练完整的网络相比性能更好,那么我们知道,在残差网络的训练期间,其实并不需要使用长路径。我们通过在每个mini-batch中只训练一部分残差模块来实现这一点。特别地,我们选择的模块数量,使得训练过程中的路径分布与网络中有效路径的分布一致。对于有54个模块的网络,这意味着我们在每个训练批次中只抽样23个模块。然后,训练过程中的路径长度在11.5个模块左右,与有效路径长度相匹配。在我们的实验中,只使用有效路径训练出来的网络错误率为5.96%,而完整残差网络的错误率为6.10%,差异无统计学意义。这确实表明,残差网络中只有 有效的路径 是必要的。
6.Discussion
- 移除残差模块主要是移除长路径 : 从残差网络中删除模块主要是删除残差网络中的长路径。特别地,当从长度为n的网络中删除d个残差模块时,针对每个长为x的路径,删除若干模块后,该长度所剩余的路径数量占原来数量的比例为
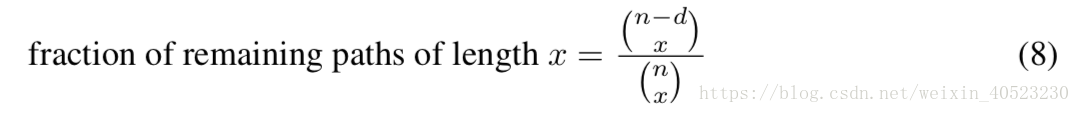 图7展示了从54个模块的残差网络中删除1个、10个和20个模块后剩下的部分路径。显然,残差模块的删除主要影响长路径。即使删除了10个残差模块,长度在5到17个模块之间的许多有效路径仍然是有效的。主要是有效路径对性能起了很重要的作用,所以这个结果与图5 (a)的实验结果一致。去除10个残差模块时,性能仅略有下降,但是当,去除20个残差模块时,我们观察到性能有严重的下降。
图7展示了从54个模块的残差网络中删除1个、10个和20个模块后剩下的部分路径。显然,残差模块的删除主要影响长路径。即使删除了10个残差模块,长度在5到17个模块之间的许多有效路径仍然是有效的。主要是有效路径对性能起了很重要的作用,所以这个结果与图5 (a)的实验结果一致。去除10个残差模块时,性能仅略有下降,但是当,去除20个残差模块时,我们观察到性能有严重的下降。
图7 图8
7.Conclusion
- 残差网络性能提高的原因是什么?在最近新的残差网络中,xx等人提出了一个假设:"我们通过一个简单但重要的概念得到了这些结果——going deeper"。虽然它们比以前的方法更深,但我们提出了一个补充的解释。
首先,我们提出的观点揭示了:残差网络可以看作是许多路径的集合,而不是单个超深网络。

- Residual Networks Behave Like Ensembles of Relatively Shallow Networks
- 《Residual Networks Behave Like Ensembles of Relatively Shallow Networks》笔记
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
- PolyNet A pursuit of structural diversity in very deep networks(翻译笔记)
- Data-Driven Sparse Structure Selection for Deep Neural Networks 论文翻译
- 论文笔记: Inferring Networks of Substituable and Complementary Products
- 论文笔记-Identity Mappings in Deep Residual Networks
- 论文笔记 | Identity Mappings in Deep Residual Networks
- Like What You Like: Knowledge Distill via Neuron Selectivity Transfer 论文翻译
- 经典论文翻译导读之《Dremel: Interactive Analysis of WebScale Datasets》
- 论文笔记 | Wide Residual Networks
- 论文笔记之: Wide Residual Networks
- AlphaGo论文的译文,用深度神经网络和树搜索征服围棋:Mastering the game of Go with deep neural networks and tree search
- [论文阅读]Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks
- [深度学习论文笔记][Image Classification] Identity Mappings in Deep Residual Networks
- 论文笔记之:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
- 论文阅读笔记:Intriguing properties of neural networks
- End-To-End Memory Networks 论文翻译
- Very Deep Convolutional Networks for Large-Scale Image Recognition—VGG论文翻译—中文版
- [深度学习论文笔记][Weight Initialization] Data-dependent Initializations of Convolutional Neural Networks