python爬虫实战---豆瓣电影top250的电影信息抓取
2018-09-01 23:10
986 查看
本文主要抓取豆瓣电影top250榜单里面的电影数据,提取的数据包括电影名称、电影的链接、电影的星级、电影引言、电影的评论 人数等。
导入包
from bs4 import BeautifulSoup as bs---进行网页解析
import requests---用于网页请求
import time---用于延长时间,防止过于快速抓取数据,封ip
import re---正则表达式使用
import csv---数据存储到csv文件
网页分析
通过浏览器右键点击检查,选择netword和里面XHR刷新来看,我们要提取的数据并不是异步加载的,也不是通过其他加密方式加载的,可以直接把网页的源码爬取下来,在进行解析就可以。
网页结构解析
url的结构:
https://movie.douban.com/top250?start=0&filter=,里面的参数start就是对应着哪一页,相当于偏移量,且每次在原来的基础上加25,每次修改start的值就可以获取下一页的信息。
网页结构:
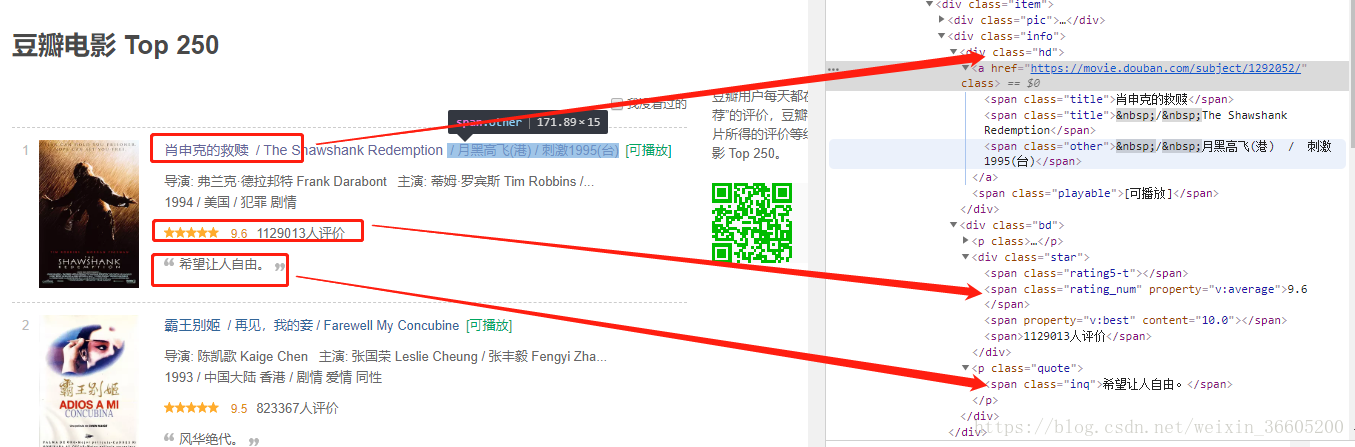
每一部电影的信息都在一个class属性为item的div盒子里面,通过BeautifulSoup的find_all('div',{'class':'item'})来找到该页所有相关的盒子,class属性为hd的div盒子,包含电影链接、电影名称,class属性为start的div盒子,包含星级和评论人数,引言在 class属性为quote的p标签里面。
网页下载
[code]# 获取一页数据
def get_one_page(offset):
# 设置请求头
headers={
'Referer':'https://movie.douban.com/top250?start=0&filter=',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://movie.douban.com/top250?start='+str(offset)+'&filter='
try:
time.sleep(1)
response=requests.get(url,headers=headers)
# 判断相应状态,200表示请求成功
if response.status_code == 200:
return response.content
except Exception as e:
print('出错!')
return None
网页解析
[code]def parse_page(offset):
response=get_one_page(offset)
if response:
# print(response.decode('utf-8'))
html=bs(response.decode('utf-8'),'lxml')
items=html.find_all('div',{'class':'item'})
if items:
for item in items:
a=item.find('div',{'class':'hd'}).a
s=item.find('div',{'class':'star'})
bd=item.find('div',{'class':'bd'})
# 链接
href=a.attrs['href']
# 名称
title=a.span.get_text()
# 引言
quote=bd.find('p',{'class':'quote'}).span.get_text()
# 星级
star=s.find('span',{'class':'rating_num'}).get_text()
# 评价人数
conment_people=re.search(r'[0-9].*[^人评价</span>]',str(s.contents[len(s.contents)-2])).group()
yield{
'title':title,
'href':href,
'star':star,
'quote':quote,
'number':conment_people
}
else:
print('没有找到该节点')
数据存储
参数i的作用判断是否为第一次写进文件,作为标记,避免后面的多次写进的时候会出现多行的名称 链接 星级 引言 评论人数,去遍历生成器的数据,并把每部电影的信息存储到一个csvList列表里面去,再把该列表添加到datalist列表中去,每一个csvfile列表的数据就是csv文件里面的一行数据,最后再把datalist作为参数,传进writerows()方面。
[code]# 保存数据到csv文件里面
def save_csv_files(contents,i):
"""
newline='':去除换行,
encoding='utf-8':指明编码格式,防止中文乱码
"""
with open('douban_top250.csv','a',encoding='utf-8',newline='')as f:
# 将python中的字典转换为json格式,并对输出中文指定ensure_ascii=False
csvFile=csv.writer(f)
if i ==0:
csvFile.writerow(['名称','链接','星级','引言','评论人数'])
datalist=[]
for data in contents:
csvList=[]
csvList.append(data['title'])
csvList.append(data['href'])
csvList.append(data['star'])
csvList.append(data['quote'])
csvList.append(data['number'])
datalist.append(csvList)
csvFile.writerows(datalist)
总结
- BeautifulSoup使用的优点臃肿,在解析网页的时候,可以考虑使用正则表达式去完成。
- csv的文件操作不熟练,有几种方式写进csv文件应该要熟练。
源码:
链接:https://pan.baidu.com/s/1LxSH2J7HA163mZNrhiWGRQ 密码:kzo1
阅读更多
相关文章推荐
- Python3.6爬虫爬取豆瓣电影Top250信息
- python实践2——利用爬虫抓取豆瓣电影TOP250数据及存入数据到MySQL数据库
- python 爬虫学习三(Scrapy 实战,豆瓣爬取电影信息)
- 爬虫实战【11】Python获取豆瓣热门电影信息
- Python爬虫框架Scrapy实战之批量抓取招聘信息
- 用Python爬虫爬取豆瓣电影、读书Top250并排序
- Python爬虫实战---抓取图书馆借阅信息
- Python 爬虫 —— 豆瓣电影爬虫实战
- Python爬虫实战---抓取图书馆借阅信息
- Python爬虫入门2 | 爬取豆瓣电影信息
- Python 爬虫实战:分析豆瓣中最新电影的影评(词云显示)
- Python爬虫实战——豆瓣电影Top250
- Python爬虫实战三 | 蓝奏网盘抓取网盘链接信息
- python爬虫的初体验,爬取豆瓣Top250电影的图片
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- python3.x爬虫实战:阿里巴巴网站定向信息抓取
- Python3爬虫豆瓣电影TOP250将电影名写入到EXCEL
- python爬虫实战 | 爬取豆瓣TOP250排名信息
- Python 爬虫实战:分析豆瓣中最新电影的影评
- 【极客学院】-python学习笔记-4-单线程爬虫 (提交表单抓取信息,实战练习)