Python爬虫入门2 | 爬取豆瓣电影信息
2018-04-26 11:00
1071 查看
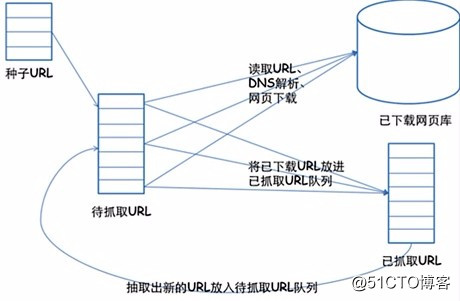
这是一个适用于小白的Python爬虫免费教学课程,只有7节,让零基础的你初步了解爬虫,跟着课程内容能自己爬取资源。看着文章,打开电脑动手实践,平均45分钟就能学完一节,如果你愿意,今天内你就可以迈入爬虫的大门啦~好啦,正式开始我们的第二节课《爬取豆瓣电影信息》吧!啦啦哩啦啦,都看黑板~1. 爬虫原理1.1 爬虫基本原理听了那么多的爬虫,到底什么是爬虫?爬虫又是如何工作的呢?我们先从“爬虫原理”说起。爬虫又称为网页蜘蛛,是一种程序或脚本。但重点在于:它能够按照一定的规则,自动获取网页信息。爬虫的通用框架如下:1.挑选种子URL;2.将这些URL放入待抓取的URL队列;3.取出待抓取的URL,下载并存储进已下载网页库中。此外,将这些URL放入待抓取URL队列,进入下一循环;4.分析已抓取队列中的URL,并且将URL放入待抓取URL队列,从而进入下一循环。
咳咳~
还是用一个具体的例子,来说明吧!
1.2 一个爬虫例子
爬虫获取网页信息和人工获取信息,其实原理是一致的,比如我们要获取电影的“评分”信息:

人工操作步骤:获取电影信息的页面定位(找到)到评分信息的位置复制、保存我们想要的评分数据爬虫操作步骤:请求并下载电影页面信息解析并定位评分信息保存评分数据感觉是不是很像?1.3 爬虫的基本流程简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~2. Requests+Xpath 爬取豆瓣电影Python 中爬虫相关的包很多:Urllib、requsts、bs4……我们从 requests+xpath 讲起,因为太容易上手了!学习之后你就会发现,BeautifulSoup 还是稍微有点难的。下面我们用 requests+xpath 爬取豆瓣电影:2.1 安装 Python 应用包:requests、lxml如果是首次使用Requests+Xpath,首先需要安装两个包:requests和lxml,在终端分别输入以下两行代码即可(安装方法在第1节中已讲过):
pip install requests
pip install lxml
2.2 导入我们需要的 Python 模块我们在jupyter中编写代码,首先导入我们需要的两个模块:import requests
from lxml import etree
Python中导入库直接用”import+库名“,需要用库里的某种方法用”from+库名+import+方法名“。这里我们需要requests来下载网页,用lxml.etree来解析网页。2.3 获取豆瓣电影目标网页并解析我们要爬取豆瓣电影《肖申克的救赎》上面的一些信息,网站地址是:https://movie.douban.com/subject/1292052/

给定 url 并用 requests.get() 方法来获取页面的text,用 etree.HTML() 来解析下载的页面数据“data”。url = 'https://movie.douban.com/subject/1292052/'
data = requests.get(url).text
s=etree.HTML(data)
2.4 获取电影名称获取元素的Xpath信息并获得文本:file=s.xpath('元素的Xpath信息/text()')
这里的“元素的Xpath信息”是需要我们手动获取的,获取方式为:定位目标元素,在网站上依次点击:右键 > 检查
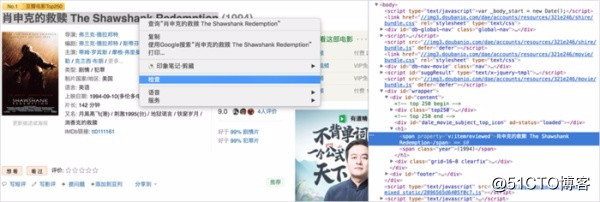
(http://i2.51cto.com/images/blog/201804/26/5e2eddc1caa0a6a405f762c444761fc2.jpg?x-oss-process=image/watermark,size_16,text_QDUxQ1RP
b60
5Y2a5a6i,color_FFFFFF,t_100,g_se,x_10,y_10,shadow_90,type_ZmFuZ3poZW5naGVpdGk=)
这样我们就把元素中的Xpath信息复制下来了://*[@id=]br/>快捷键“shift+ctrl+c”,移动鼠标到对应的元素时即可看到对应网页代码:

这样我们就把元素中的Xpath信息复制下来了://*[@id="content"]/h1/span[1]
print(film)
2.5 代码以及运行结果以上完整代码如下:import requests
from lxml import etree
url = '[url=https://movie.douban.com/subject/1292052/]https://movie.douban.com/subject/1292052/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
在 Jupyter 中运行完整代码及结果如下:

至此,我们完成了爬取豆瓣电影《肖申克的救赎》中“电影名称”信息的代码编写,可以在 Jupyter 中运行。2.6 获取其它元素信息除了电影的名字,我们还可以获取导演、主演、电影片长等信息,获取的方式是类似的。代码如下:director=s.xpath('//[@id="info"]/span[1]/span[2]/a/text()') #导演
actor1=s.xpath('//[@id="info"]/span[3]/span[2]/a[1]/text()') #主演1
actor2=s.xpath('//[@id="info"]/span[3]/span[2]/a[2]/text()') #主演2
actor3=s.xpath('//[@id="info"]/span[3]/span[2]/a[3]/text()') #主演3
time=s.xpath(‘//[@id="info"]/span[13]/text()') #电影片长
观察上面的代码,发现获取不同“主演”信息时,区别只在于“a[x]”中“x”的数字大小不同。实际上,要一次性获取所有“主演”的信息时,用不加数字的“a”表示即可。代码如下:actor=s.xpath('//[@id="info"]/span[3]/span[2]/a/text()') #主演
完整代码如下:import requests
from lxml import etree
url = 'https://movie.douban.com/subject/1292052/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//[@id="content"]/h1/span[1]/text()')
director=s.xpath('//[@id="info"]/span[1]/span[2]/a/text()')[url=http://blog.51cto.com/13719825/mailt
27e4
o:br/>actor=s.xpath('/*[@id=]br/>actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
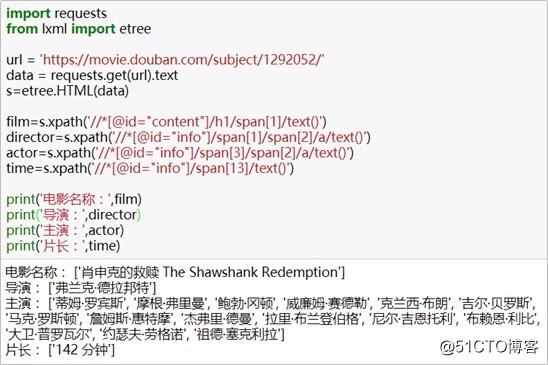
print('导演:',director)
print('主演:',actor)
print('片长:',time)
在jupyter中运行完整代码及结果如下:
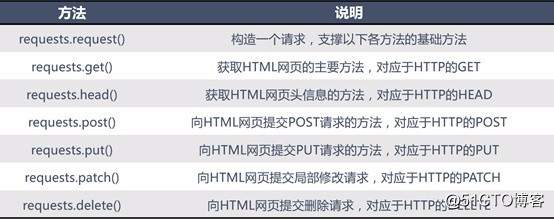
关于RequestsRequests库官方的介绍有这么一句话:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。这句话直接并霸气地宣示了 Requests 库是 python 最好的一个HTTP库。为什么它有这样的底气?如有兴趣请阅读 Requests 官方文档 。Requests 常用的七种方法:
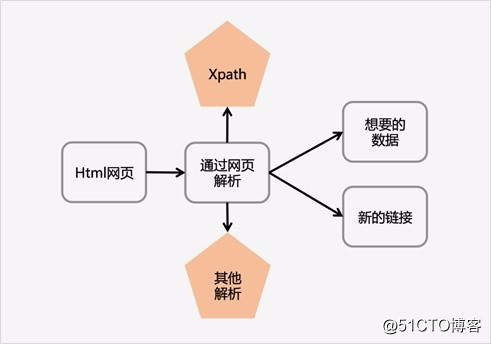
关于解析神器 XpathXpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。可以阅读该文档了解更多关于 Xpath 的知识。Xpath解析网页的流程:1.首先通过Requests库获取网页数据2.通过网页解析,得到想要的数据或者新的链接3.网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 在是一个非常好用的网页解析工具
常见的网页解析方法比较
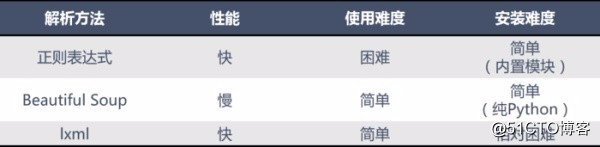
正则表达式使用比较困难,学习成本较高
BeautifulSoup 性能较慢,相对于 Xpath 较难,在某些特定场景下有用
Xpath 使用简单,速度快(Xpath是lxml里面的一种),是入门最好的选择
好了,这节课就到这里!
咳咳~
还是用一个具体的例子,来说明吧!
1.2 一个爬虫例子
爬虫获取网页信息和人工获取信息,其实原理是一致的,比如我们要获取电影的“评分”信息:
人工操作步骤:获取电影信息的页面定位(找到)到评分信息的位置复制、保存我们想要的评分数据爬虫操作步骤:请求并下载电影页面信息解析并定位评分信息保存评分数据感觉是不是很像?1.3 爬虫的基本流程简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~2. Requests+Xpath 爬取豆瓣电影Python 中爬虫相关的包很多:Urllib、requsts、bs4……我们从 requests+xpath 讲起,因为太容易上手了!学习之后你就会发现,BeautifulSoup 还是稍微有点难的。下面我们用 requests+xpath 爬取豆瓣电影:2.1 安装 Python 应用包:requests、lxml如果是首次使用Requests+Xpath,首先需要安装两个包:requests和lxml,在终端分别输入以下两行代码即可(安装方法在第1节中已讲过):
pip install requests
pip install lxml
2.2 导入我们需要的 Python 模块我们在jupyter中编写代码,首先导入我们需要的两个模块:import requests
from lxml import etree
Python中导入库直接用”import+库名“,需要用库里的某种方法用”from+库名+import+方法名“。这里我们需要requests来下载网页,用lxml.etree来解析网页。2.3 获取豆瓣电影目标网页并解析我们要爬取豆瓣电影《肖申克的救赎》上面的一些信息,网站地址是:https://movie.douban.com/subject/1292052/
给定 url 并用 requests.get() 方法来获取页面的text,用 etree.HTML() 来解析下载的页面数据“data”。url = 'https://movie.douban.com/subject/1292052/'
data = requests.get(url).text
s=etree.HTML(data)
2.4 获取电影名称获取元素的Xpath信息并获得文本:file=s.xpath('元素的Xpath信息/text()')
这里的“元素的Xpath信息”是需要我们手动获取的,获取方式为:定位目标元素,在网站上依次点击:右键 > 检查
(http://i2.51cto.com/images/blog/201804/26/5e2eddc1caa0a6a405f762c444761fc2.jpg?x-oss-process=image/watermark,size_16,text_QDUxQ1RP
b60
5Y2a5a6i,color_FFFFFF,t_100,g_se,x_10,y_10,shadow_90,type_ZmFuZ3poZW5naGVpdGk=)
这样我们就把元素中的Xpath信息复制下来了://*[@id=]br/>快捷键“shift+ctrl+c”,移动鼠标到对应的元素时即可看到对应网页代码:

这样我们就把元素中的Xpath信息复制下来了://*[@id="content"]/h1/span[1]
print(film)
2.5 代码以及运行结果以上完整代码如下:import requests
from lxml import etree
url = '[url=https://movie.douban.com/subject/1292052/]https://movie.douban.com/subject/1292052/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
print(film)
在 Jupyter 中运行完整代码及结果如下:
至此,我们完成了爬取豆瓣电影《肖申克的救赎》中“电影名称”信息的代码编写,可以在 Jupyter 中运行。2.6 获取其它元素信息除了电影的名字,我们还可以获取导演、主演、电影片长等信息,获取的方式是类似的。代码如下:director=s.xpath('//[@id="info"]/span[1]/span[2]/a/text()') #导演
actor1=s.xpath('//[@id="info"]/span[3]/span[2]/a[1]/text()') #主演1
actor2=s.xpath('//[@id="info"]/span[3]/span[2]/a[2]/text()') #主演2
actor3=s.xpath('//[@id="info"]/span[3]/span[2]/a[3]/text()') #主演3
time=s.xpath(‘//[@id="info"]/span[13]/text()') #电影片长
观察上面的代码,发现获取不同“主演”信息时,区别只在于“a[x]”中“x”的数字大小不同。实际上,要一次性获取所有“主演”的信息时,用不加数字的“a”表示即可。代码如下:actor=s.xpath('//[@id="info"]/span[3]/span[2]/a/text()') #主演
完整代码如下:import requests
from lxml import etree
url = 'https://movie.douban.com/subject/1292052/'
data = requests.get(url).text
s=etree.HTML(data)
film=s.xpath('//[@id="content"]/h1/span[1]/text()')
director=s.xpath('//[@id="info"]/span[1]/span[2]/a/text()')[url=http://blog.51cto.com/13719825/mailt
27e4
o:br/>actor=s.xpath('/*[@id=]br/>actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
print('导演:',director)
print('主演:',actor)
print('片长:',time)
在jupyter中运行完整代码及结果如下:
关于RequestsRequests库官方的介绍有这么一句话:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。这句话直接并霸气地宣示了 Requests 库是 python 最好的一个HTTP库。为什么它有这样的底气?如有兴趣请阅读 Requests 官方文档 。Requests 常用的七种方法:
关于解析神器 XpathXpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。可以阅读该文档了解更多关于 Xpath 的知识。Xpath解析网页的流程:1.首先通过Requests库获取网页数据2.通过网页解析,得到想要的数据或者新的链接3.网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 在是一个非常好用的网页解析工具
常见的网页解析方法比较
正则表达式使用比较困难,学习成本较高
BeautifulSoup 性能较慢,相对于 Xpath 较难,在某些特定场景下有用
Xpath 使用简单,速度快(Xpath是lxml里面的一种),是入门最好的选择
好了,这节课就到这里!

相关文章推荐
- 爬虫入门:python+pycharm,豆瓣电影信息,短评,分页爬取,mysql数据库连接
- [python爬虫] BeautifulSoup和Selenium对比爬取豆瓣Top250电影信息
- 一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
- Python爬虫学习---------根据分类爬取豆瓣电影的电影信息
- python3[爬虫基础入门实战] 爬取豆瓣电影排行top250
- Python爬虫入门 | 7 分类爬取豆瓣电影,解决动态加载问题
- 爬虫实战【11】Python获取豆瓣热门电影信息
- [python爬虫入门]爬取豆瓣电影排行榜top250
- Python3.6爬虫爬取豆瓣电影Top250信息
- python 爬虫学习三(Scrapy 实战,豆瓣爬取电影信息)
- [置顶] python爬虫实践——零基础快速入门(二)爬取豆瓣电影
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- Python爬虫----抓取豆瓣电影Top250
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
- python 爬虫抓豆瓣电影,并存入数据库
- [Python/爬虫]利用xpath爬取豆瓣电影top250
- python爬虫 豆瓣电影
- python爬虫获取豆瓣正在热播电影
- python爬虫之豆瓣图书信息几行字