Python爬虫实战——豆瓣电影Top250
2017-02-23 10:07
906 查看
第一篇博客,用我昨天学的爬虫来见证一下,纯粹记录自己的学习。
废话不多说,show your code!!
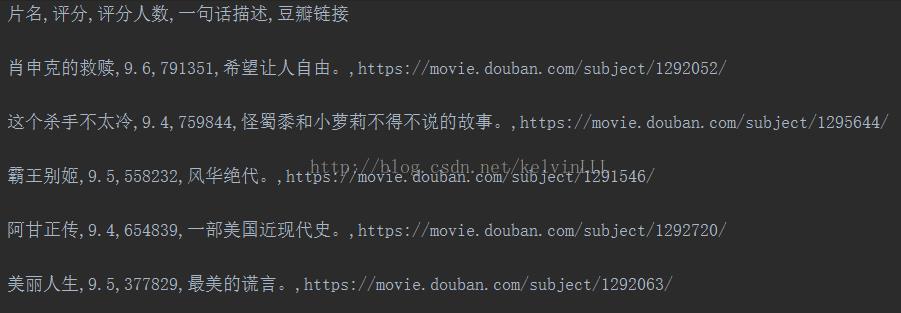
结果截图如下:
主要用了BeautiSoup这个强大的节点搜索库,所以实现思路比较简单。
不过有几点需要注意:
1.编码问题
不同编译器默认编码形式不一致,要在文件头声明编码字符集,另外还要用sys.setdefultencoding
2.find()与find_all()
find()找到的是距离节点最近的一个,以树结构返回,findall找到所有满足条件的,以列表形式返回
3.存csv文件的问题
用csv.DictWriter()时,注意writerows(),writerow()的区别,前者写入多行,当数据只有一行时会报Error:Key0 ;后者写入单行,用字典指定对应字段需要写入的内容。
废话不多说,show your code!!
#!/usr/bin/python
# -*- encoding:utf-8 -*-
"""
@author : kelvin
@file : douban_movie
@time : 2017/2/22 23:04
@description :
"""
import sys
import requests
import re
from bs4 import BeautifulSoup
import csv
reload(sys)
sys.setdefaultencoding('utf-8') # 由于编译器的问题,需要设置默认字符集格式,不然会报unicodeError
# 先创建一个csv文件,写好头部
with open("douban_top250_movies.csv", 'w') as filed: # a+为添加,w为擦除重写
csv_writer = csv.DictWriter(filed, [
u'片名',
u'评分',
u'评分人数',
u'一句话描述',
u'豆瓣链接',
])
csv_writer.writeheader()
def get_mov_info(response):
mov_info = {}
soup = BeautifulSoup(response.text, "lxml")
movies = soup.find_all('div', class_="info")
for info in movies:
# 获得电影的中文名
mov_info['mov_name'] = info.find('span', class_='title').text # find()只找到一个,结果以树结构返回
# 获得电影在豆瓣中的链接
mov_info['mov_link'] = info.find('a').get('href')
# 找到评分以及评价人数
rating_num = info.find(class_='rating_num')
mov_info['rating_score'] = rating_num.text
comment = rating_num.find_next_sibling().find_next_sibling()
# 对评价字段切分
comment_num = re.findall('\d{0,}', comment.text)
mov_info['comment_nums'] = comment_num[0] # 正则匹配re中没有find(),findall()以列表形式返回结果
# 获得一句话评价
comment_one = info.find('span', class_='inq')
if comment_one is None:
mov_info['inq_comment'] = u' '
else:
mov_info['inq_comment'] = comment_one.text
print mov_info
# 一条条存入csv文件
write_csv(mov_info)
def write_csv(info_dict):
with open("douban_top250_movies.csv", 'a+') as f:
csv_write = csv.DictWriter(f, [
u'片名',
u'评分',
u'评分人数',
u'一句话描述',
u'豆瓣链接',
])
csv_write.writerow({ # writerow()写入单行,writerows写入多行,这里只有一行数据,用writerows报错
u'片名': info_dict['mov_name'],
u'评分': info_dict['rating_score'],
u'评分人数': info_dict['comment_nums'],
u'一句话描述': info_dict['inq_comment'],
u'豆瓣链接': info_dict['mov_link']
})
for num in xrange(0, 10):
page = num * 25
response = requests.get("https://movie.douban.com/top250?start=%d&filter=" % page)
print response
get_mov_info(response)结果截图如下:
主要用了BeautiSoup这个强大的节点搜索库,所以实现思路比较简单。
不过有几点需要注意:
1.编码问题
不同编译器默认编码形式不一致,要在文件头声明编码字符集,另外还要用sys.setdefultencoding
2.find()与find_all()
find()找到的是距离节点最近的一个,以树结构返回,findall找到所有满足条件的,以列表形式返回
3.存csv文件的问题
用csv.DictWriter()时,注意writerows(),writerow()的区别,前者写入多行,当数据只有一行时会报Error:Key0 ;后者写入单行,用字典指定对应字段需要写入的内容。

相关文章推荐
- Python爬虫实战——豆瓣电影top250
- python3[爬虫基础入门实战] 爬取豆瓣电影排行top250
- python 爬虫 保存豆瓣TOP250电影海报及修改名称
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
- 1.【python爬虫学习笔记】爬取豆瓣电影top250
- [Python爬虫]1.豆瓣电影Top250
- Python爬虫----抓取豆瓣电影Top250
- (7)Python爬虫——爬取豆瓣电影Top250
- Python爬虫初学(2)豆瓣电影top250评论数
- Python爬虫初学(1)豆瓣电影top250评论数
- python 爬虫实战(一)爬取豆瓣图书top250
- Python爬虫实战(一):爬取豆瓣电影top250排名
- Python爬虫获取豆瓣电影TOP250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- 萌新的Python学习日记 - 爬虫无影 - 爬取豆瓣电影top250并入库:豆瓣电影top250
- python3--爬虫实战一:爬取豆瓣电影250
- Python爬虫——豆瓣电影Top250
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- Python爬虫豆瓣电影top250
- Python爬虫小案例:豆瓣电影TOP250