[DataAnalysis]数据挖掘常见的几种分类算法
2018-04-02 15:24
274 查看
转载自:https://blog.csdn.net/TOMOCAT/article/details/79102867一、数据挖掘任务分类
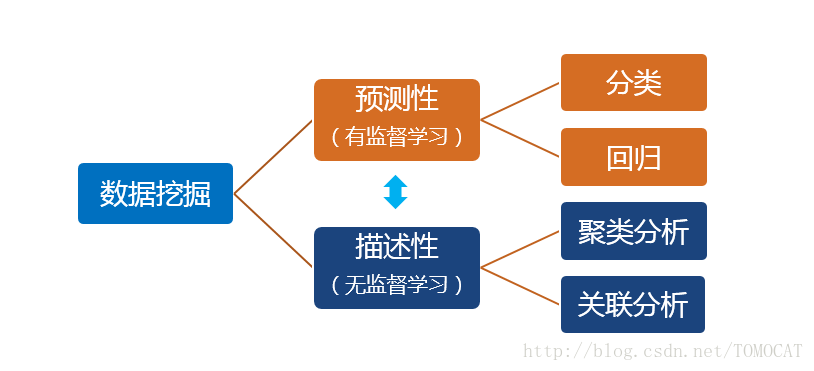
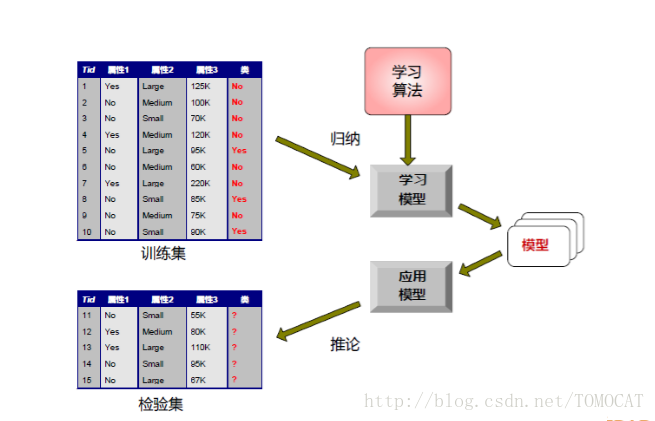
1、预测性和描述性的主要区别在于是否有目标变量2、预测性包括分类和回归:(1)分类:输出变量为离散型,常见的算法包括(朴素)贝叶斯、决策树、逻辑回归、KNN、SVM、神经网络、随机森林。(2)回归:输出变量为连续型。3、描述性包括聚类和关联:(1)聚类:实现对样本的细分,使得同组内的样本特征较为相似,不同组的样本特征差异较大。例如零售客户细分。(2)关联::指的是我们想发现数据的各部分之间的联系和规则。常指购物篮分析,即消费者常常会同时购买哪些产品,从而有助于商家的捆绑销售。4、建立分类模型的一般方法:
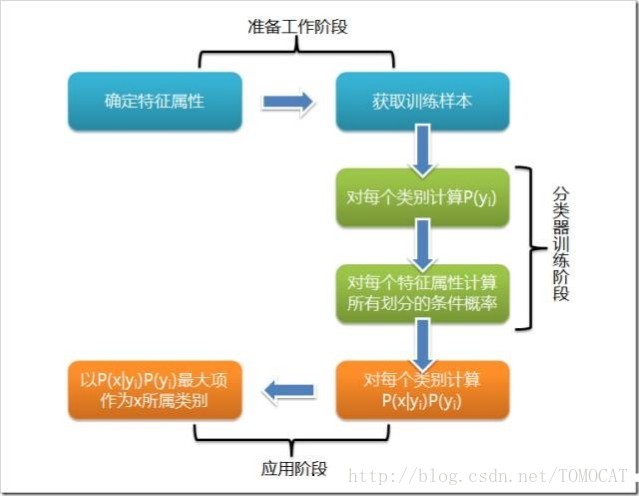
二、朴素贝叶斯1、贝叶斯定理:

2、原理:对于给出的待分类项(即特征属性的集合),求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。3、朴素贝叶斯分类流程
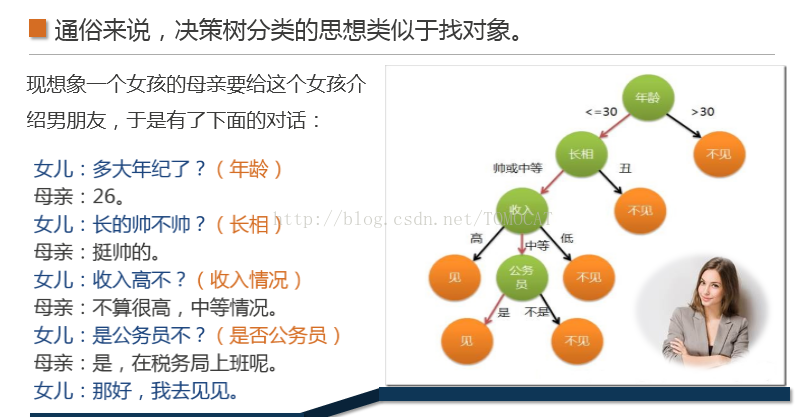
三、决策树1、原理,相当于找对象
2、决策树定义:决策树(DecisionTree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。3、决策树构造:

其中属性选择度量的算法很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。ID3和C4.5是两种常用算法。4、ID3算法:

信息增益是特征选择中的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。基本信息包括:熵,期望信息和信息增益。(1)熵:设D为用类别对训练元组进行的划分,则D的熵表示为:
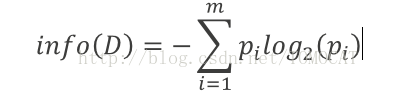
其中?i表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。(2)期望信息:现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
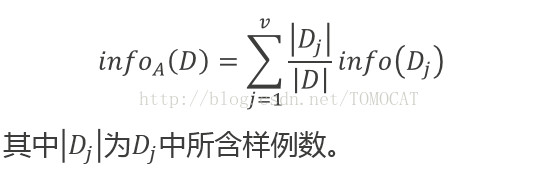
(3)信息增益:

(4)待补充案例:SNS社区中不真实账号检测的例子如中使用ID3算法构造决策树。5、C4.5算法:(1)ID3算法存在的问题:偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。(例如会选择主键)(2)原理:C4.5算法是基于ID3算法进行改进后的一种重要算法,使用信息增益率来选择属性。

四、逻辑回归1、原理:



1、预测性和描述性的主要区别在于是否有目标变量2、预测性包括分类和回归:(1)分类:输出变量为离散型,常见的算法包括(朴素)贝叶斯、决策树、逻辑回归、KNN、SVM、神经网络、随机森林。(2)回归:输出变量为连续型。3、描述性包括聚类和关联:(1)聚类:实现对样本的细分,使得同组内的样本特征较为相似,不同组的样本特征差异较大。例如零售客户细分。(2)关联::指的是我们想发现数据的各部分之间的联系和规则。常指购物篮分析,即消费者常常会同时购买哪些产品,从而有助于商家的捆绑销售。4、建立分类模型的一般方法:
二、朴素贝叶斯1、贝叶斯定理:
2、原理:对于给出的待分类项(即特征属性的集合),求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。3、朴素贝叶斯分类流程
三、决策树1、原理,相当于找对象
2、决策树定义:决策树(DecisionTree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。3、决策树构造:
其中属性选择度量的算法很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。ID3和C4.5是两种常用算法。4、ID3算法:
信息增益是特征选择中的一个重要指标,它定义为一个特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。基本信息包括:熵,期望信息和信息增益。(1)熵:设D为用类别对训练元组进行的划分,则D的熵表示为:
其中?i表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。(2)期望信息:现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
(3)信息增益:
(4)待补充案例:SNS社区中不真实账号检测的例子如中使用ID3算法构造决策树。5、C4.5算法:(1)ID3算法存在的问题:偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。(例如会选择主键)(2)原理:C4.5算法是基于ID3算法进行改进后的一种重要算法,使用信息增益率来选择属性。
四、逻辑回归1、原理:

相关文章推荐
- [DataAnalysis]数据挖掘常见的几种分类算法
- 【CSDN学院视频】以性别预测为例,谈谈数据挖掘中常见的分类算法
- 数据挖掘算法分类别示例
- 数据挖掘十大经典算法(10) CART: 分类与回归树
- 数据挖掘回顾六:分类算法之 AdaBoost 集成算法
- 数据挖掘分类算法的优缺点总结
- 数据挖掘中分类算法小结
- 常见数据挖掘算法的Map-Reduce策略(2)
- 数据挖掘十大经典算法学习之C4.5决策树分类算法及信息熵相关
- 数据挖掘--分类--决策树--算法
- 数据挖掘中分类算法小结
- 数据挖掘系列(7)分类算法评价
- 数据挖掘系列(6)决策树分类算法
- 数据挖掘经典算法--朴素贝叶斯分类
- 数据挖掘算法(一)提高文本分类算法准确率和性能的10条建议
- 一小时了解数据挖掘②:分类算法的应用和成熟案例解析
- 数据挖掘分类算法(2)
- 数据挖掘-决策树ID3分类算法的C++实现
- 数据挖掘---分类算法之SOFM算法
- 数据挖掘笔记-分类-回归算法-梯度上升