k-means聚类复杂度探讨
2018-03-22 23:07
357 查看
k-means聚类一种无监督的学习方法(也就是不需要人为告诉计算机如何处理)
一般流程:
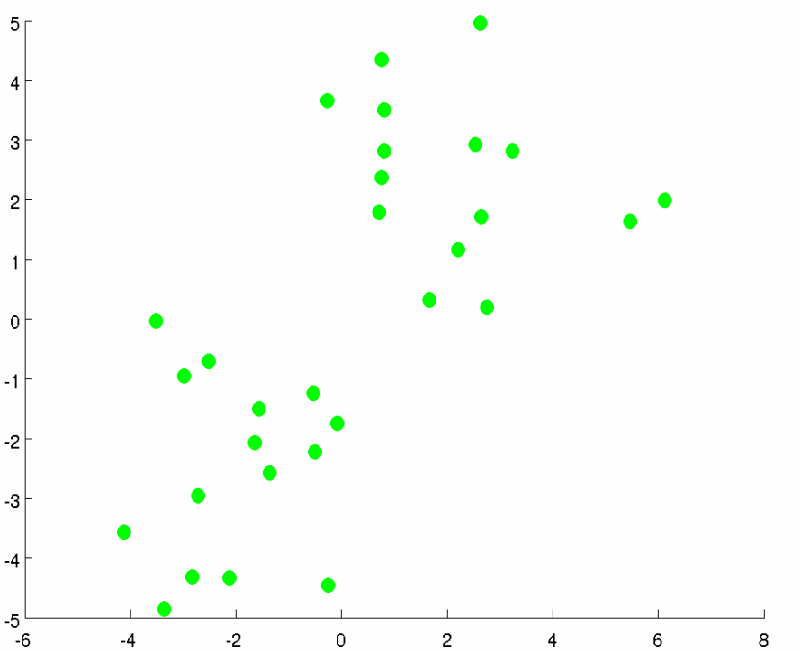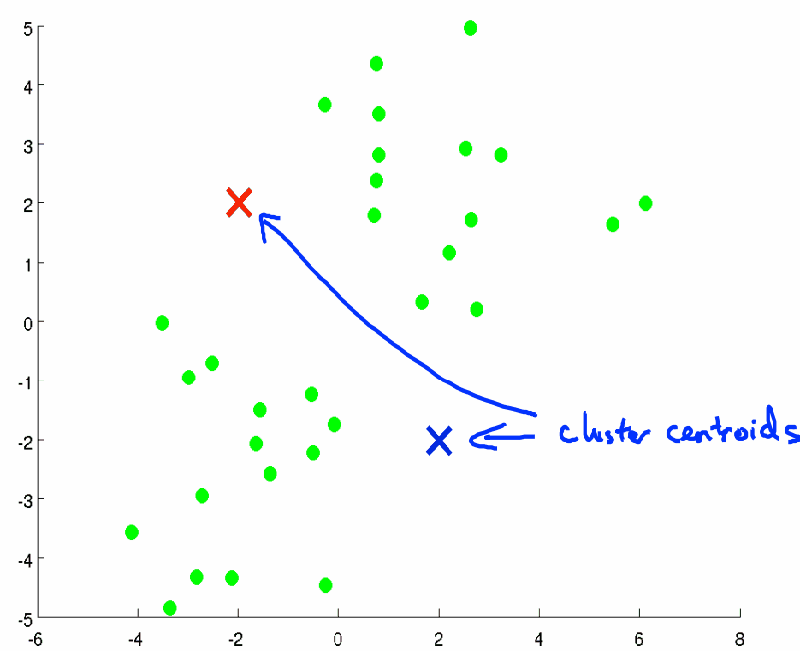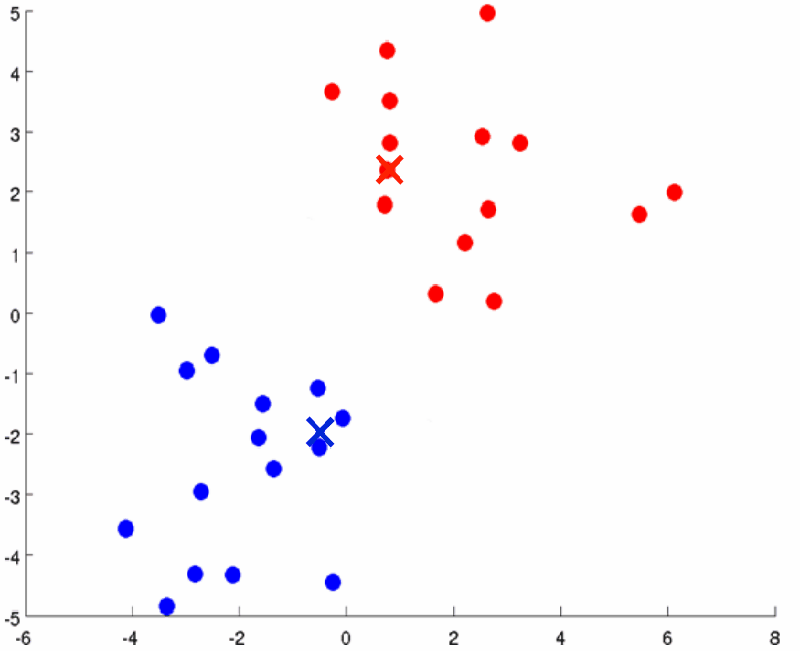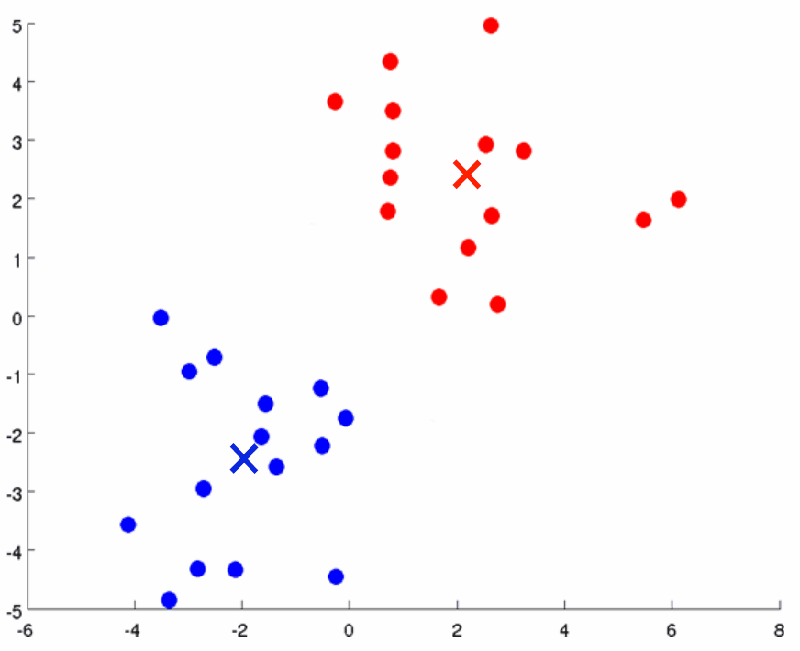
先随机设定k个聚类中心(此处的k决定了最终的k类)
然后计算n个点到k个点的距离,单个图像与图像距离计算的复杂度为d(涉及到sift的可以自己查阅一下复杂度多少,这里不一一赘述。)
聚类完成之后,我们需要进一步迭代。首先计算聚的k个类的聚类中心,然后用找到的k个聚类中心进行再次聚类。当聚类中心不再变动时,聚类停止。设此时迭代次数为t次。
因此可以看出,k-means聚类复杂度为O1=k*n*d*t
此处为了说明k-means聚类的优点,引入比较无脑的全比较算法
也就是n个点和n个点进行比较,比较的单个复杂度为d
因此我们的计算量为O2=(n^2)*d
O2/O1=n/kt
一般我们所做的分类问题涉及到的数量级都是上万的,n非常的大,而我们的kt相比来说就小很多了。虽然我们的精度没有全比较法找到最接近的另一点,但是在类别差距不是很大时,我们对k进行适当选择,是可以得到我们想要的分类结果的。
一般流程:
先随机设定k个聚类中心(此处的k决定了最终的k类)
然后计算n个点到k个点的距离,单个图像与图像距离计算的复杂度为d(涉及到sift的可以自己查阅一下复杂度多少,这里不一一赘述。)
聚类完成之后,我们需要进一步迭代。首先计算聚的k个类的聚类中心,然后用找到的k个聚类中心进行再次聚类。当聚类中心不再变动时,聚类停止。设此时迭代次数为t次。
因此可以看出,k-means聚类复杂度为O1=k*n*d*t
此处为了说明k-means聚类的优点,引入比较无脑的全比较算法
也就是n个点和n个点进行比较,比较的单个复杂度为d
因此我们的计算量为O2=(n^2)*d
O2/O1=n/kt
一般我们所做的分类问题涉及到的数量级都是上万的,n非常的大,而我们的kt相比来说就小很多了。虽然我们的精度没有全比较法找到最接近的另一点,但是在类别差距不是很大时,我们对k进行适当选择,是可以得到我们想要的分类结果的。

相关文章推荐
- 机器学习读书笔记03 聚类(K-Means)
- 【聚类】- 聚类之K-means基础
- 关于算法的时间复杂度的探讨
- 机器学习中的k-means聚类及其Python实例
- K-means++ 聚类
- python sklearn:聚类-k-means,聚类趋势,簇数确定,测定聚类质量
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
- 聚类 python中k-means几种初始化质心的方式
- 机器学习实战之k-means聚类_代码注释
- 基于距离的聚类方法--K-means
- 聚类练习3——k-means 聚类
- 用scikit-learn学习K-Means聚类
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
- Spark 实战,第 4 部分: 使用 Spark MLlib 做 K-means 聚类分析
- K-Means聚类和EM算法复习总结
- 面试:机器学习--k均值聚类(K-means)
- K-means 聚类
- k-means 聚类hadoop 平台
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
- 聚类、K-Means、例子、细节