信息熵 条件熵 联合熵 交叉熵 互信息
2018-03-07 17:43
295 查看
最近用到信息论的知识表较多,自己也总结下。1 信息熵(entropy)定义式:

其中P(x)是变量出现的概率。从直观上,信息熵越大,变量包含的信息量越大,变量的不确定性也越大。一个事物内部会存在随机性,也就是不确定性,而从外部消除这个不确定性唯一的办法是引入信息。如果没有信息,任何公式或者数字的游戏都无法排除不确定性。几乎所有的自然语言处理,信息与信号处理的应用都是一个消除不确定性的过程。2 条件熵(conditional entropy)知道的信息越多,随机事件的不确定性就越小。
定义式:

3 联合熵设X Y为两个随机变量,对于给定条件Y=y下,X的条件熵定义为:
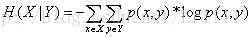
4 交叉熵交叉熵是用来衡量估计模型与真实概率之间的差距。
如果一个随机变量X∼p(x)X∼p(x),q(x)q(x)用于近似p(x)p(x)的分布,那么变量XX与模型qq之间的交叉熵表示为

5 互信息(mutual information)两个事件的互信息定义为:I(X;Y)=H(X)+H(Y)-H(X,Y),也就是用来衡量两个信息的相关性大小的量。互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。
定义式:
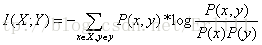
DKL(p||q)=Ep[logp(x)q(x)]=∑x∈Xp(x)logp(x)q(x)DKL(p||q)=Ep[logp(x)q(x)]=∑x∈Xp(x)logp(x)q(x)
=∑x∈X[p(x)logp(x)−p(x)logq(x)]=∑x∈X[p(x)logp(x)−p(x)logq(x)]
=∑x∈Xp(x)logp(x)−∑x∈Xp(x)logq(x)=∑x∈Xp(x)logp(x)−∑x∈Xp(x)logq(x)
=−H(p)−∑x∈Xp(x)logq(x)=−H(p)−∑x∈Xp(x)logq(x)
=−H(p)+Ep[−logq(x)]=−H(p)+Ep[−logq(x)]
=Hp(q)−H(p)=Hp(q)−H(p)
并且为了保证连续性,做如下约定:
0log00=0,0log0q=0,plogp0=∞0log00=0,0log0q=0,plogp0=∞
显然,当p=qp=q时,两者之间的相对熵DKL(p||q)=0DKL(p||q)=0
上式最后的Hp(q)Hp(q)表示在p分布下,使用q进行编码需要的bit数,而H(p)表示对真实分布pp所需要的最小编码bit数。基于此,相对熵的意义就很明确了:DKL(p||q)DKL(p||q)表示在真实分布为p的前提下,使用q分布进行编码相对于使用真实分布p进行编码(即最优编码)所多出来的bit数
交叉熵和KL散度上一节说了信息熵H(X)可以看做,对X中的样本进行编码所需要的编码长度的期望值。这里可以引申出交叉熵的理解,现在有两个分布,真实分布p和非真实分布q,我们的样本来自真实分布p。按照真实分布p来编码样本所需的编码长度的期望为
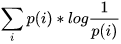
,这就是上面说的信息熵H( p )按照不真实分布q来编码样本所需的编码长度的期望为
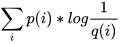
,这就是所谓的交叉熵H( p,q )这里引申出KL散度D(p||q) = H(p,q) - H(p) =
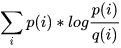
,也叫做相对熵,它表示两个分布的差异,差异越大,相对熵越大。
应用:(1)去计算一个变量的不确定性,可以考虑信息熵;在研究显著性时,可以用信息熵去计算一个区域的信息量的大小,近而来判断其为显著性区域;(2)计算两个变量之间的相关性,可以考虑条件熵;转至:http://blog.csdn.net/Erli11/article/details/21606235
其中P(x)是变量出现的概率。从直观上,信息熵越大,变量包含的信息量越大,变量的不确定性也越大。一个事物内部会存在随机性,也就是不确定性,而从外部消除这个不确定性唯一的办法是引入信息。如果没有信息,任何公式或者数字的游戏都无法排除不确定性。几乎所有的自然语言处理,信息与信号处理的应用都是一个消除不确定性的过程。2 条件熵(conditional entropy)知道的信息越多,随机事件的不确定性就越小。
定义式:
3 联合熵设X Y为两个随机变量,对于给定条件Y=y下,X的条件熵定义为:
4 交叉熵交叉熵是用来衡量估计模型与真实概率之间的差距。
如果一个随机变量X∼p(x)X∼p(x),q(x)q(x)用于近似p(x)p(x)的分布,那么变量XX与模型qq之间的交叉熵表示为
5 互信息(mutual information)两个事件的互信息定义为:I(X;Y)=H(X)+H(Y)-H(X,Y),也就是用来衡量两个信息的相关性大小的量。互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。
定义式:
5相对熵?
相对熵(relative entropy)又称为KL散度(Kullback-Leibler divergence),KL距离,是两个随机分布间距离的度量。记为DKL(p||q)DKL(p||q)。它度量当真实分布为p时,假设分布q的无效性。DKL(p||q)=Ep[logp(x)q(x)]=∑x∈Xp(x)logp(x)q(x)DKL(p||q)=Ep[logp(x)q(x)]=∑x∈Xp(x)logp(x)q(x)
=∑x∈X[p(x)logp(x)−p(x)logq(x)]=∑x∈X[p(x)logp(x)−p(x)logq(x)]
=∑x∈Xp(x)logp(x)−∑x∈Xp(x)logq(x)=∑x∈Xp(x)logp(x)−∑x∈Xp(x)logq(x)
=−H(p)−∑x∈Xp(x)logq(x)=−H(p)−∑x∈Xp(x)logq(x)
=−H(p)+Ep[−logq(x)]=−H(p)+Ep[−logq(x)]
=Hp(q)−H(p)=Hp(q)−H(p)
并且为了保证连续性,做如下约定:
0log00=0,0log0q=0,plogp0=∞0log00=0,0log0q=0,plogp0=∞
显然,当p=qp=q时,两者之间的相对熵DKL(p||q)=0DKL(p||q)=0
上式最后的Hp(q)Hp(q)表示在p分布下,使用q进行编码需要的bit数,而H(p)表示对真实分布pp所需要的最小编码bit数。基于此,相对熵的意义就很明确了:DKL(p||q)DKL(p||q)表示在真实分布为p的前提下,使用q分布进行编码相对于使用真实分布p进行编码(即最优编码)所多出来的bit数
交叉熵和KL散度上一节说了信息熵H(X)可以看做,对X中的样本进行编码所需要的编码长度的期望值。这里可以引申出交叉熵的理解,现在有两个分布,真实分布p和非真实分布q,我们的样本来自真实分布p。按照真实分布p来编码样本所需的编码长度的期望为
,这就是上面说的信息熵H( p )按照不真实分布q来编码样本所需的编码长度的期望为
,这就是所谓的交叉熵H( p,q )这里引申出KL散度D(p||q) = H(p,q) - H(p) =
,也叫做相对熵,它表示两个分布的差异,差异越大,相对熵越大。
应用:(1)去计算一个变量的不确定性,可以考虑信息熵;在研究显著性时,可以用信息熵去计算一个区域的信息量的大小,近而来判断其为显著性区域;(2)计算两个变量之间的相关性,可以考虑条件熵;转至:http://blog.csdn.net/Erli11/article/details/21606235

相关文章推荐
- 信息论中的熵(信息熵,联合熵,交叉熵,互信息)和最大熵模型
- 【基本概念】信息熵 条件熵 联合熵 左右熵 互信息
- 信息、信息熵、条件熵、信息增益、信息增益比、基尼系数、相对熵、交叉熵
- 数学之美--信息的度量和作用--信息熵,条件熵和交叉熵
- 关于信息增益、信息熵、条件熵
- 最大熵模型(Maximum Etropy)—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
- 信息熵、信息增益、条件熵基本概念及联系
- 信息熵 条件熵 信息增益 信息增益比 GINI系数
- 信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息。
- 与信息熵相关的概念梳理(条件熵/互信息/相对熵/交叉熵)
- 信息熵,条件熵,互信息的通俗理解
- 信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息
- Data Mining --- Information theory:熵/条件熵/互信息(信息增益)/交叉熵(相对熵/KL距离)
- 熵、信息熵、交叉熵、相对熵、条件熵、互信息、条件熵的贝叶斯规则
- 【机器学习】信息量,信息熵,交叉熵,KL散度和互信息(信息增益)
- 信息熵 条件熵 信息增益 信息增益比 GINI系数
- 熵模型—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
- 信息论基本概念(熵、联合熵、条件熵、相对熵、互信息)讲述与推导
- 用户信息:奇偶数隔行变色,选中行变色,鼠标变小手样式;姓名查询条件,过滤敏感字符;下拉列表排序;非空验证添加信息;点击按钮删除
- 完美解决mysql in条件语句只读取一条信息问题的2种方案