信息、信息熵、条件熵、信息增益、信息增益比、基尼系数、相对熵、交叉熵
2017-02-23 23:29
561 查看
参考:
http://www.cnblogs.com/fantasy01/p/4581803.html?utm_source=tuicool http://blog.csdn.net/xbmatrix/article/details/58248347 https://www.zhihu.com/question/41252833/answer/141598211
引用香农的话,信息是用来消除随机不确定性的东西,则某个类(xi)的信息定义如下:
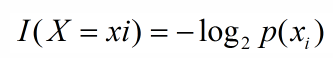
信息熵便是信息的期望值,可以记作:
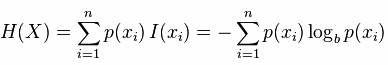
熵只依赖X的分布,和X的取值没有关系,熵是用来度量不确定性,当熵越大,概率说X=xi的不确定性越大,反之越小,在机器学期中分类中说,熵越大即这个类别的不确定性更大,反之越小,当随机变量的取值为两个时,熵随概率的变化曲线如下图:
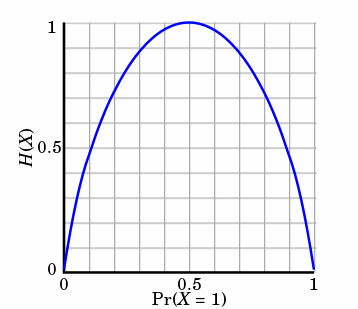
当p=0或p=1时,H(p)=0,随机变量完全没有不确定性,当p=0.5时,H(p)=1,此时随机变量的不确定性最大
更特别一点,如果是个二分类系统,那么此系统的熵为:
H(X)=-(P(c0)log2p(c0)+p(c1)log2p(c1))
X给定条件下Y的条件分布的熵对X的数学期望,在机器学习中为选定某个特征后的熵,公式如下:
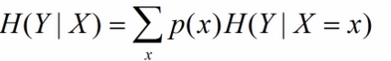
一个特征对应着多个类别Y,因此在此的多个分类即为X的取值x。
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差(这里只的是经验熵或经验条件熵,由于真正的熵并不知道,是根据样本计算出来的),公式如下:
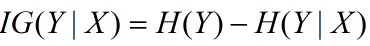
信息增益的一个大问题就是偏向选择特征值比较多的属性从而导致overfitting,那么我们能想到的解决办法自然就是对分支过多的情况进行惩罚(penalty)了。于是我们有了信息增益比:
特征X的熵:
H(X)=−∑i=1npilogpi
特征X的信息增益
:
IG(X)=H(c)−H(c|X)
那么信息增益比为:
gr=H(c)−H(c|X)H(X)
Gini系数的计算方式如下:
Gini(D)=1−∑i=1np2i
其中,D表示数据集全体样本,pi表示每种类别出现的概率。取个极端情况,如果数据集中所有的样本都为同一类,那么有p0=1,Gini(D)=0,显然此时数据的不纯度最低。
7.



http://www.cnblogs.com/fantasy01/p/4581803.html?utm_source=tuicool http://blog.csdn.net/xbmatrix/article/details/58248347 https://www.zhihu.com/question/41252833/answer/141598211
1、信息
引用香农的话,信息是用来消除随机不确定性的东西,则某个类(xi)的信息定义如下:
2、信息熵
信息熵便是信息的期望值,可以记作:熵只依赖X的分布,和X的取值没有关系,熵是用来度量不确定性,当熵越大,概率说X=xi的不确定性越大,反之越小,在机器学期中分类中说,熵越大即这个类别的不确定性更大,反之越小,当随机变量的取值为两个时,熵随概率的变化曲线如下图:
当p=0或p=1时,H(p)=0,随机变量完全没有不确定性,当p=0.5时,H(p)=1,此时随机变量的不确定性最大
更特别一点,如果是个二分类系统,那么此系统的熵为:
H(X)=-(P(c0)log2p(c0)+p(c1)log2p(c1))
3. 条件熵
X给定条件下Y的条件分布的熵对X的数学期望,在机器学习中为选定某个特征后的熵,公式如下:一个特征对应着多个类别Y,因此在此的多个分类即为X的取值x。
4. 信息增益
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差(这里只的是经验熵或经验条件熵,由于真正的熵并不知道,是根据样本计算出来的),公式如下:
5. 信息增益比
信息增益的一个大问题就是偏向选择特征值比较多的属性从而导致overfitting,那么我们能想到的解决办法自然就是对分支过多的情况进行惩罚(penalty)了。于是我们有了信息增益比:特征X的熵:
H(X)=−∑i=1npilogpi
特征X的信息增益
:
IG(X)=H(c)−H(c|X)
那么信息增益比为:
gr=H(c)−H(c|X)H(X)
6. Gini系数
Gini系数是一种与信息熵类似的做特征选择的方式,可以用来数据的不纯度。在CART(Classification and Regression Tree)算法中利用基尼指数构造二叉决策树(选择基尼系数最小的特征及其对应的特征值)。Gini系数的计算方式如下:
Gini(D)=1−∑i=1np2i
其中,D表示数据集全体样本,pi表示每种类别出现的概率。取个极端情况,如果数据集中所有的样本都为同一类,那么有p0=1,Gini(D)=0,显然此时数据的不纯度最低。
7.
交叉熵、相对熵

相关文章推荐
- 信息熵 条件熵 联合熵 交叉熵 互信息
- 信息熵、信息增益、条件熵基本概念及联系
- 【机器学习】信息量,信息熵,交叉熵,KL散度和互信息(信息增益)
- 信息熵 条件熵 信息增益 信息增益比 GINI系数
- 熵、信息熵、交叉熵、相对熵、条件熵、互信息、条件熵的贝叶斯规则
- 信息熵 条件熵 信息增益 信息增益比 GINI系数
- 关于信息增益、信息熵、条件熵
- Data Mining --- Information theory:熵/条件熵/互信息(信息增益)/交叉熵(相对熵/KL距离)
- 数学之美--信息的度量和作用--信息熵,条件熵和交叉熵
- 熵模型—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
- 相对熵(互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度即KL散度)的深入理解
- KL散度(相对熵,信息增益)学习笔记
- 条件熵 信息增益
- 树模型中分裂特征选择标准--信息熵,信息增益,信息增益率的计算
- 信息论基本概念(熵、联合熵、条件熵、相对熵、互信息)讲述与推导
- 信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息。
- 信息论中的熵(信息熵,联合熵,交叉熵,互信息)和最大熵模型
- 信息量、熵、最大熵、联合熵、条件熵、相对熵、互信息
- 熵,互信息,KL距离(相对熵),交叉熵
- 信息熵、gini、信息增益