python使用selenium自动访问网站运行hivesql并取数(版本一)
2018-02-09 15:49
603 查看
最近接了一个日报的自动化项目,主要是需要我们自动访问数据库,运行查询语句取数,并根据下载结果生成昨日日报,最终发送给领导们昨日一些主要数据指标。 需求方给了我们日报模板和hivesql代码,我们就吭哧吭哧的准备开干,怎么办呢?我之前曾经就自动爬取过知乎的问答列表及单个问答页面数据,用的就是selenium自动化测试模拟鼠标操作网页,也没啥问题(主要是我们的hive服务器为了防范数据泄露,没有开10000端口,大数据部门搭建了一个hue来供我们访问,所以不能直接通过hiveSQL包来直接访问hive服务器,只能通过登录hue访问)
如果需要使用selenium自动化测试需要首先搭建selenium服务器(貌似是搭建在google上的服务),我是直接去官网下载的(www.seleniumhq.org/download),我的系统是64位的windows,
4000
选择64bit下载,下载后我将文件解压到c盘,如下图:
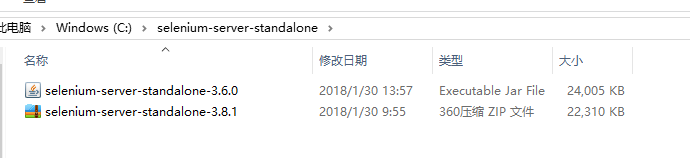
在进入命令行界面后,输入java -jar selenium-server-standalone-3.8.1.zip(下载的jar文件被自动识别为zip文件,建议大家在下载后看看文件后缀,总之命令行需要输入正确的后缀才能运行)

总之在输入后,需要看到server is up and running才算是启动成功。
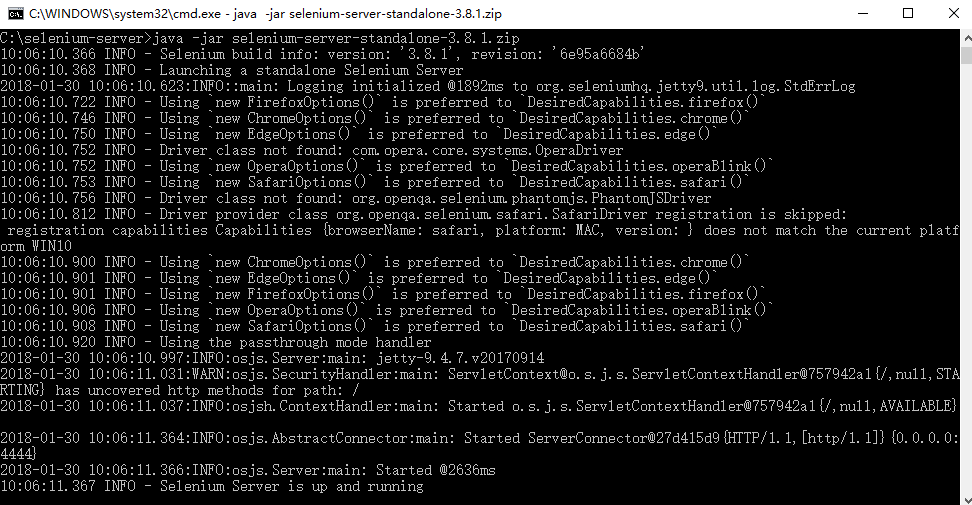
之前我是用R爬取数据,现在再尝试,结果发现没办法访问selenium服务器(即使在命令行说明已经启动server的前提下),R里面的错误如下图:
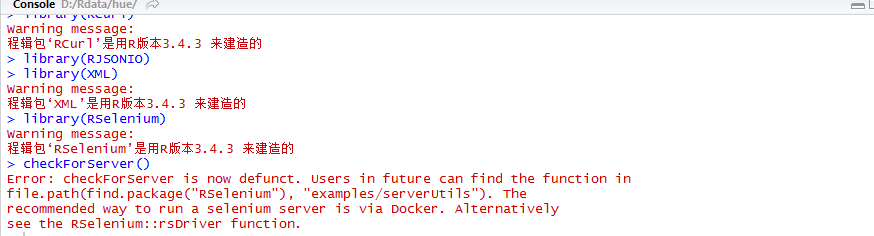
在我重新安装了R最新版,已经更新了rstudio后,仍然会出现这样的问题。折腾了两天,果断放弃,着手寻找用python来实现自动化测试的方法。还好自己还有一定的python基础,直接上代码:Created on Thu Feb 1 18:00:06 2018@author: gos
"""# -*- coding: utf-8 -*-
"""
Spyder EditorThis is a temporary script file.
"""
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from time import sleep
import sys,os
'''配置firefox自动下载设置及清空下载文件夹(保证每次下载数据最新)'''
fp=webdriver.FirefoxProfile()
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showWhenStarting",False)
downloadpath="D:\\pythondata\\hue\\csv"
fp.set_preference("browser.download.dir",downloadpath)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/csv,text/csv")
#清空数据文件夹
dellist=[]
dellist=os.listdir(downloadpath)
for f in dellist:
filePath = os.path.join(downloadpath,f)
if os.path.isfile(filePath):
os.remove(filePath)
#设置读取sql的文件夹
sqlpath="D:\\pythondata\\hue\\sql"
list=os.listdir(sqlpath)
'''自动操作浏览器进行登录hue运行代码并下载数据'''
driver = webdriver.Firefox(firefox_profile=fp)
driver.get('http://101.201.153.2:8888/')
driver.implicitly_wait(500)
input=driver.find_element_by_id('id_username')
input.send_keys('name')
input=driver.find_element_by_id('id_password')
input.send_keys('password')
driver.find_element_by_xpath('/html/body/div[2]/div[1]/div/form/div[3]/input[1]').click()
sleep(2)
driver.find_element_by_xpath('//*[@id="jHueTourModalClose"]').click()
sleep(2)
'''循环读取sql文件并在浏览器中执行'''
for i in range(1,7):
try:
driver.find_element_by_link_text('Hive').click()
sleep(2)
p=open(os.path.join("D:\\pythondata\\hue\\sql",list[i]),encoding='utf-8')
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[5]/div/div[1]/div/div/div/div[3]').click()
sleep(1)
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[1]/textarea').send_keys(p.read())
sleep(5)
driver.find_element_by_xpath('//*[@id="executeQuery"]').click()
sleep(500-50*i)
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[4]/div[1]/a[3]/h4/i').click()
p.close()
except Exception as e:
driver.find_element_by_link_text('Hive').click()
sleep(2)
p=open(os.path.join("D:\\pythondata\\hue\\sql",list[i]),encoding='utf-8')
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[5]/div/div[1]/div/div/div/div[3]').click()
sleep(1)
elem_pos = driver.switch_to_active_element()
elem_pos.send_keys(Keys.CONTROL, 'a')
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[1]/textarea').send_keys(p.read())
sleep(5)
driver.find_element_by_xpath('//*[@id="executeQuery"]').click()
sleep(800)
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[4]/div[1]/a[3]/h4/i').click()
p.close()
'''关闭浏览器'''
driver.quit()
这段代码里面主要有三个坑:
1、每次通过server打开一个firefox浏览器,都会清空你的默认设置,所以你在加载浏览器的时候需要导入你的设置,要不然浏览器在下载csv文件的时候,是没办法自行判断下载的(会出一个下载窗口,不能通过selenium调试,这样会导致自动化程序终止),所以我们事先会定义好自动下载文件位置,格式,是否自动弹出下载窗口等下载设置,并导入webdriver要调入的浏览器窗口即可;2、每次运行代码都会自动下载7个文件,如果不删除,文件夹肯定会越来越大,所以这段代码里面还加了一段自动清除文件的代码;另外系统在切换页面的时候持续时间较长,运行代码的时候时间更长,所以代码中我设置了一个sleep强制休息时间,但是这中间每段代码运行时间不一,还是需要有更为合理的等待方式;
3、因为有7段代码,所以我这边使用了一个循环分别读取sql并每次下载输出,程序中会动态跟随光标;由于本人电脑在运行程序的时候还需要操作去处理其他事情,所以经常会出现错误,所以我在循环里面也加入了一段出错处理代码,保证一段代码出错了之后还能再运行一次。
后续主要是把这些代码封装成类,模块化处理效果会更好。
代码已经封装成类,具体从我的码云找到:https://gitee.com/goskiller/codes/vq7b85gr1tc0pfjk9dzli41
如果需要使用selenium自动化测试需要首先搭建selenium服务器(貌似是搭建在google上的服务),我是直接去官网下载的(www.seleniumhq.org/download),我的系统是64位的windows,
4000
选择64bit下载,下载后我将文件解压到c盘,如下图:
在进入命令行界面后,输入java -jar selenium-server-standalone-3.8.1.zip(下载的jar文件被自动识别为zip文件,建议大家在下载后看看文件后缀,总之命令行需要输入正确的后缀才能运行)
总之在输入后,需要看到server is up and running才算是启动成功。
之前我是用R爬取数据,现在再尝试,结果发现没办法访问selenium服务器(即使在命令行说明已经启动server的前提下),R里面的错误如下图:
在我重新安装了R最新版,已经更新了rstudio后,仍然会出现这样的问题。折腾了两天,果断放弃,着手寻找用python来实现自动化测试的方法。还好自己还有一定的python基础,直接上代码:Created on Thu Feb 1 18:00:06 2018@author: gos
"""# -*- coding: utf-8 -*-
"""
Spyder EditorThis is a temporary script file.
"""
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from time import sleep
import sys,os
'''配置firefox自动下载设置及清空下载文件夹(保证每次下载数据最新)'''
fp=webdriver.FirefoxProfile()
fp.set_preference("browser.download.folderList",2)
fp.set_preference("browser.download.manager.showWhenStarting",False)
downloadpath="D:\\pythondata\\hue\\csv"
fp.set_preference("browser.download.dir",downloadpath)
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/csv,text/csv")
#清空数据文件夹
dellist=[]
dellist=os.listdir(downloadpath)
for f in dellist:
filePath = os.path.join(downloadpath,f)
if os.path.isfile(filePath):
os.remove(filePath)
#设置读取sql的文件夹
sqlpath="D:\\pythondata\\hue\\sql"
list=os.listdir(sqlpath)
'''自动操作浏览器进行登录hue运行代码并下载数据'''
driver = webdriver.Firefox(firefox_profile=fp)
driver.get('http://101.201.153.2:8888/')
driver.implicitly_wait(500)
input=driver.find_element_by_id('id_username')
input.send_keys('name')
input=driver.find_element_by_id('id_password')
input.send_keys('password')
driver.find_element_by_xpath('/html/body/div[2]/div[1]/div/form/div[3]/input[1]').click()
sleep(2)
driver.find_element_by_xpath('//*[@id="jHueTourModalClose"]').click()
sleep(2)
'''循环读取sql文件并在浏览器中执行'''
for i in range(1,7):
try:
driver.find_element_by_link_text('Hive').click()
sleep(2)
p=open(os.path.join("D:\\pythondata\\hue\\sql",list[i]),encoding='utf-8')
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[5]/div/div[1]/div/div/div/div[3]').click()
sleep(1)
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[1]/textarea').send_keys(p.read())
sleep(5)
driver.find_element_by_xpath('//*[@id="executeQuery"]').click()
sleep(500-50*i)
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[4]/div[1]/a[3]/h4/i').click()
p.close()
except Exception as e:
driver.find_element_by_link_text('Hive').click()
sleep(2)
p=open(os.path.join("D:\\pythondata\\hue\\sql",list[i]),encoding='utf-8')
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[5]/div/div[1]/div/div/div/div[3]').click()
sleep(1)
elem_pos = driver.switch_to_active_element()
elem_pos.send_keys(Keys.CONTROL, 'a')
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[2]/div[3]/div/div/div[3]/div[1]/textarea').send_keys(p.read())
sleep(5)
driver.find_element_by_xpath('//*[@id="executeQuery"]').click()
sleep(800)
driver.find_element_by_xpath('/html/body/div[5]/div[1]/div/div[3]/div[4]/div[1]/a[3]/h4/i').click()
p.close()
'''关闭浏览器'''
driver.quit()
这段代码里面主要有三个坑:
1、每次通过server打开一个firefox浏览器,都会清空你的默认设置,所以你在加载浏览器的时候需要导入你的设置,要不然浏览器在下载csv文件的时候,是没办法自行判断下载的(会出一个下载窗口,不能通过selenium调试,这样会导致自动化程序终止),所以我们事先会定义好自动下载文件位置,格式,是否自动弹出下载窗口等下载设置,并导入webdriver要调入的浏览器窗口即可;2、每次运行代码都会自动下载7个文件,如果不删除,文件夹肯定会越来越大,所以这段代码里面还加了一段自动清除文件的代码;另外系统在切换页面的时候持续时间较长,运行代码的时候时间更长,所以代码中我设置了一个sleep强制休息时间,但是这中间每段代码运行时间不一,还是需要有更为合理的等待方式;
3、因为有7段代码,所以我这边使用了一个循环分别读取sql并每次下载输出,程序中会动态跟随光标;由于本人电脑在运行程序的时候还需要操作去处理其他事情,所以经常会出现错误,所以我在循环里面也加入了一段出错处理代码,保证一段代码出错了之后还能再运行一次。
后续主要是把这些代码封装成类,模块化处理效果会更好。
代码已经封装成类,具体从我的码云找到:https://gitee.com/goskiller/codes/vq7b85gr1tc0pfjk9dzli41

相关文章推荐
- python selenium使用chrome/firefox的已存在的cookie访问网站
- selenium之python自动化测试系列:使用chrome或firefox的已存在的cookie访问网站
- selenium之python自动化测试系列:使用chrome或firefox的已存在的cookie访问网站
- selenium之python自动化测试系列:使用chrome或firefox的已存在的cookie访问网站
- 在asp.net里使用指定的用户运行访问Sharepoint网站的代码
- 使用python+selenium完成qq空间自动登录小程序
- python成长日记1:使用python访问网站,下载图片
- 使用squid代理后某些网站无法访问的解决办法(3.1.7版本)
- 使用Python控制IE访问网站
- 使用notepad++开发python的配置——代码缩进、自动补齐、运行
- web监控:zabbix自动发现+python之pycur模块对网站访问质量监控
- python selenium chrome使用代理自动登录,并可以远程调用
- 手机访问网站如何自动跳转到手机版本自动转到手机网站
- python3使用代理ip访问指定网站
- [Python爬虫] Selenium自动访问Firefox和Chrome并实现搜索截图
- 使用python访问网站遇到的问题
- 使用Python控制IE访问网站
- 手机访问网站如何自动跳转到手机版本自动转到手机网站
- 模拟登陆网站 之 Python版(内含两种版本的完整的可运行的代码)
- windows10下使用pyopenssl, pycurl 访问https网站(python)