Python爬虫知识点四--scrapy框架
2017-11-27 21:00
211 查看
一。scrapy结构数据
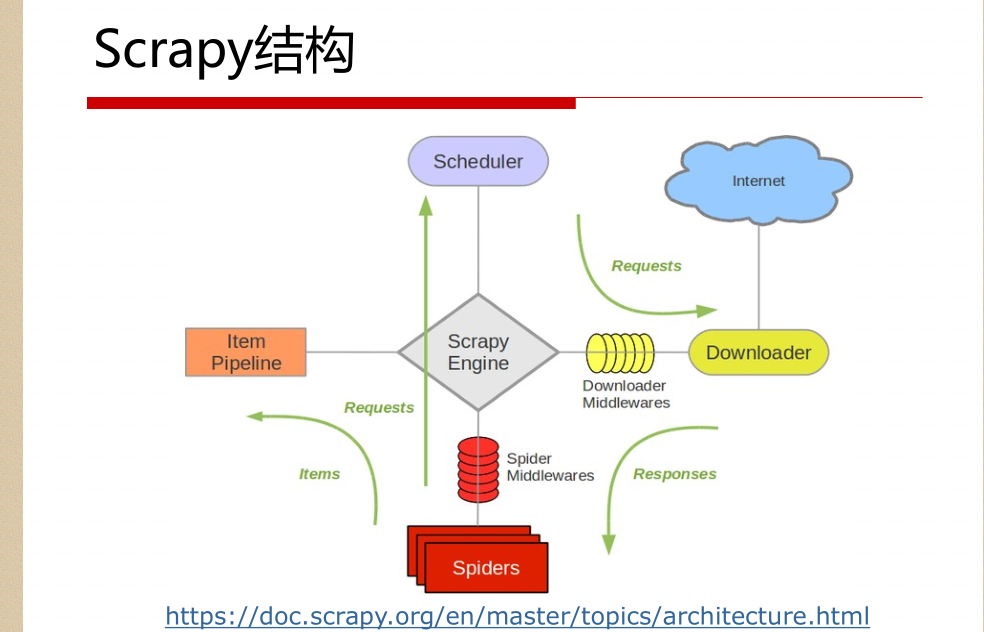
解释:
1.名词解析:
o 引擎(Scrapy Engine)
o 调度器(Scheduler)
o 下载器(Downloader)
o 蜘蛛(Spiders)
o 项目管道(Item Pipeline)
o 下载器中间件(Downloader Middlewares)
o 蜘蛛中间件(Spider Middlewares)
o 调度中间件(Scheduler Middlewares)
2.具体解析
绿线是数据流向
从初始URL开始,Scheduler会将其交给Downloader进
行下载
下载之后会交给Spider进行分析
Spider分析出来的结果有两种
一种是需要进一步抓取的链接,如 “下一页”的链接,它们
会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline里,进行
后期处理(详细分析、过滤、存储等)。
在数据流动的通道里还可以安装各种中间件,进行必
要的处理。
二。初始化爬虫框架 Scrapy
命令: scrapy startproject qqnews
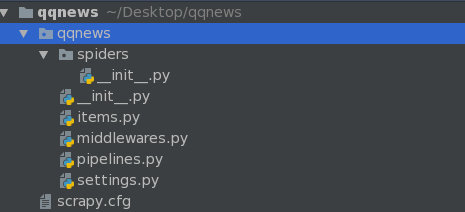
ps:真正的项目是在spiders里面写入的
三。scrapy组件spider
爬取流程
1. 先初始化请求URL列表,并指定下载后处
理response的回调函数。
2. 在parse回调中解析response并返回字典,Item
对象,Request对象或它们的迭代对象。
3 .在回调函数里面,使用选择器解析页面内容
,并生成解析后的结果Item。
4. 最后返回的这些Item通常会被持久化到数据库
中(使用Item Pipeline)或者使用Feed exports将
其保存到文件中。
标准项目结构实例:
1.items结构:定义变量,根据不同种数据结构定义
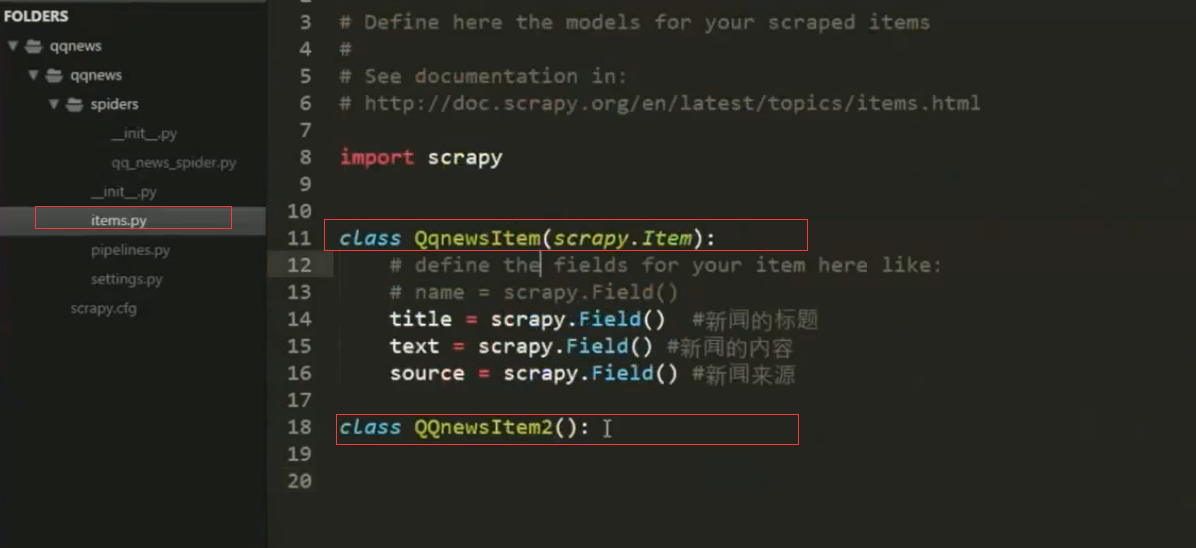
2.spider结构中引入item里面,并作填充item
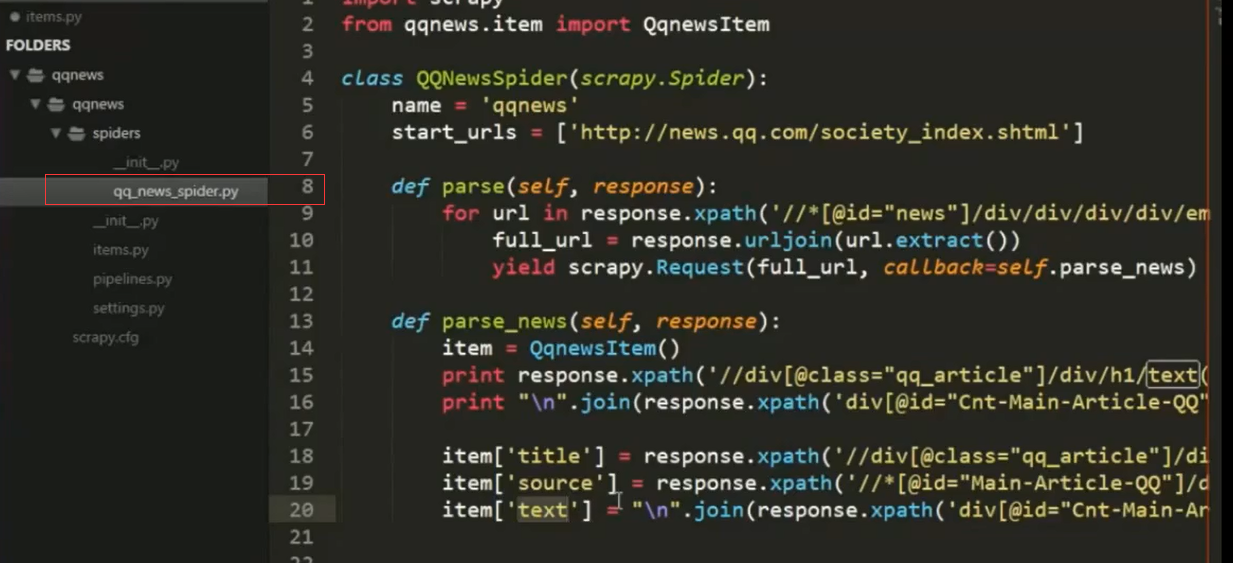
3。pipline去清洗,验证,存入数据库,过滤等等 后续处理
Item Pipeline常用场景
清理HTML数据
验证被抓取的数据(检查item是否包含某些字段)
重复性检查(然后丢弃)
将抓取的数据存储到数据库中
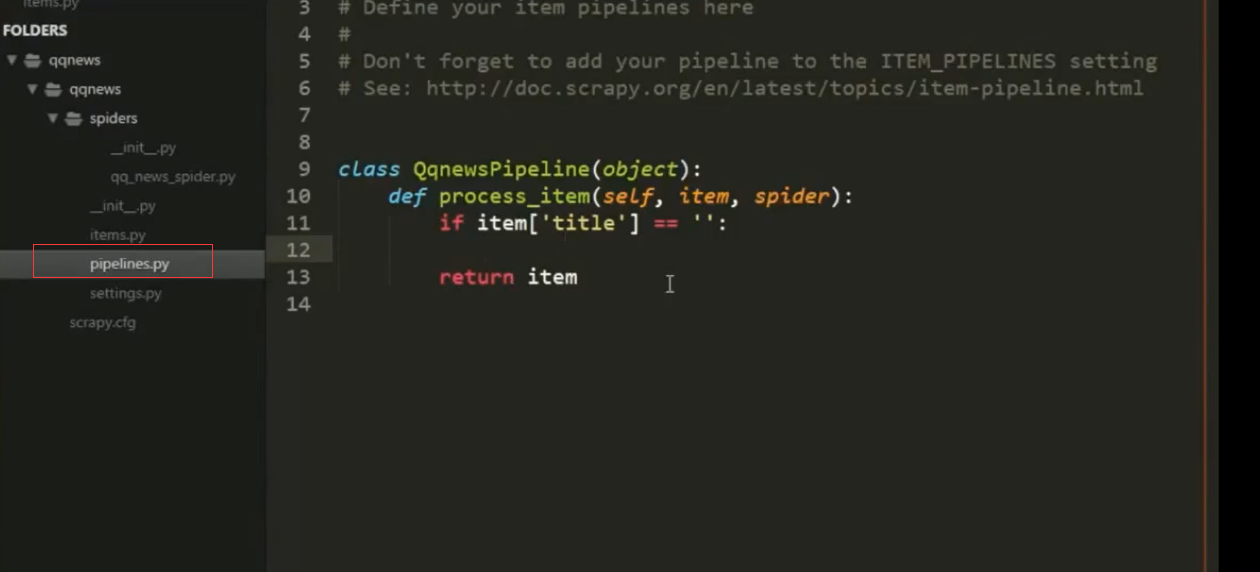
4.Scrapy组件Item Pipeline
经常会实现以下的方法:
open_spider(self, spider) 蜘蛛打开的时执行
close_spider(self, spider) 蜘蛛关闭时执行
from_crawler(cls, crawler) 可访问核心组件比如配置和
信号,并注册钩子函数到Scrapy中
pipeline真正处理逻辑
定义一个Python类,实现方法process_item(self, item,
spider)即可,返回一个字典或Item,或者抛出DropItem
异常丢弃这个Item。
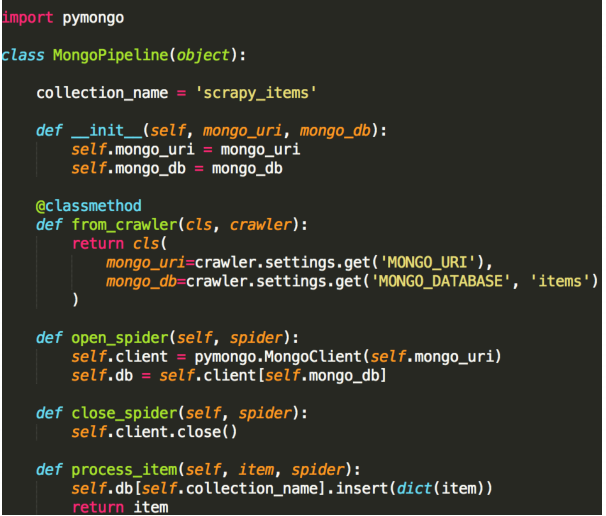
5.settings中定义哪种类型的pipeline
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

解释:
1.名词解析:
o 引擎(Scrapy Engine)
o 调度器(Scheduler)
o 下载器(Downloader)
o 蜘蛛(Spiders)
o 项目管道(Item Pipeline)
o 下载器中间件(Downloader Middlewares)
o 蜘蛛中间件(Spider Middlewares)
o 调度中间件(Scheduler Middlewares)
2.具体解析
绿线是数据流向
从初始URL开始,Scheduler会将其交给Downloader进
行下载
下载之后会交给Spider进行分析
Spider分析出来的结果有两种
一种是需要进一步抓取的链接,如 “下一页”的链接,它们
会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline里,进行
后期处理(详细分析、过滤、存储等)。
在数据流动的通道里还可以安装各种中间件,进行必
要的处理。
二。初始化爬虫框架 Scrapy
命令: scrapy startproject qqnews
ps:真正的项目是在spiders里面写入的
三。scrapy组件spider
爬取流程
1. 先初始化请求URL列表,并指定下载后处
理response的回调函数。
2. 在parse回调中解析response并返回字典,Item
对象,Request对象或它们的迭代对象。
3 .在回调函数里面,使用选择器解析页面内容
,并生成解析后的结果Item。
4. 最后返回的这些Item通常会被持久化到数据库
中(使用Item Pipeline)或者使用Feed exports将
其保存到文件中。
标准项目结构实例:
1.items结构:定义变量,根据不同种数据结构定义
2.spider结构中引入item里面,并作填充item
3。pipline去清洗,验证,存入数据库,过滤等等 后续处理
Item Pipeline常用场景
清理HTML数据
验证被抓取的数据(检查item是否包含某些字段)
重复性检查(然后丢弃)
将抓取的数据存储到数据库中
4.Scrapy组件Item Pipeline
经常会实现以下的方法:
open_spider(self, spider) 蜘蛛打开的时执行
close_spider(self, spider) 蜘蛛关闭时执行
from_crawler(cls, crawler) 可访问核心组件比如配置和
信号,并注册钩子函数到Scrapy中
pipeline真正处理逻辑
定义一个Python类,实现方法process_item(self, item,
spider)即可,返回一个字典或Item,或者抛出DropItem
异常丢弃这个Item。
5.settings中定义哪种类型的pipeline
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

相关文章推荐
- Python爬虫框架Scrapy学习三记—让虫子爬
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(1)
- python爬虫(16)使用scrapy框架爬取顶点小说网
- python爬虫框架-Scrapy安装详细教程
- Python3环境安装Scrapy爬虫框架过程及常见错误
- 在linux和windows下安装python爬虫框架scrapy
- Python爬虫框架之Scrapy详解
- Python网络爬虫框架scrapy的学习
- Python爬虫学习(七)----Scrapy框架实践
- python爬虫框架之scrapy安装与当当网爬虫实战
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- 讲解Python的Scrapy爬虫框架使用代理进行采集的方法
- 开源python网络爬虫框架Scrapy
- 教你分分钟学会用python爬虫框架Scrapy
- python爬虫人门(10)Scrapy框架之Downloader Middlewares
- python爬虫笔记 --------scrapy框架(2)
- python爬虫框架scrapy实例详解
- python爬虫框架scrapy实例详解
- Python 爬虫框架 Scrapy 快速使用
- Python爬虫框架Scrapy获得定向打击批量招聘信息