特征工程:数据处理,模型训练集锦(二)
2017-11-27 02:34
423 查看
本文是长期学习总结笔记,文中图片摘自寒小阳老师上课讲义。
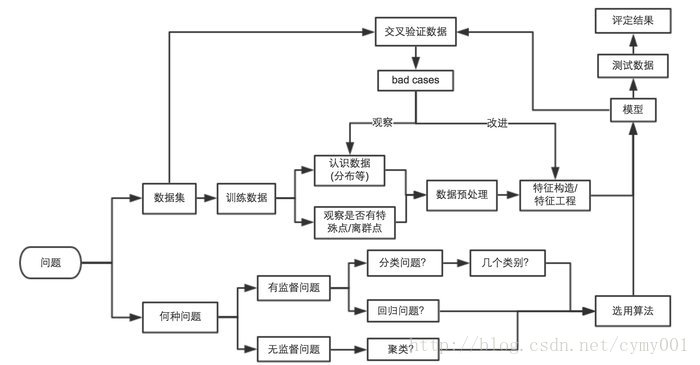
数据格式化
数据量不大,可以存文本,数据库
数据量大,放集群hadoop上:hive表,hdfs文件
数据清洗

数据缺省
如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
某一特征列缺省值少:填充
某一特征列缺省值多:去掉该特征列
某一特征列缺省值中等:类别型特征列,当成一类
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中
正负样本不均衡
树模型对样本不均衡问题敏感度比LR模型(GD)的敏感度低。
1.)欠采样:当数据量比较大时,对训练集中较多样本抽样,即去掉一部分该类样本,采样原则——分层抽样,随机抽样
选用Random Forest策略训练模型
可视化考察其分布(e.g. 金融风控比赛)
2.)过采样:当数据量不大时,增加一些训练集中较少的样本,使正负样本数相当
k近邻查找近邻点,进行插值
3.)阈值移动:不改变样本数量,对预测结果类别判定的阈值设定加入缩放因子(修改损失函数,破坏损失函数的凹凸性)
e.g.:m+表示正例数目,m−表示反例数目,根据模型的某样本的整理可能性为y,则预测类别时需要考虑的是y1−y/m+m−=y1−y⋅m−m+和1的关系,1表示正负样本数目相当时的阈值
数据与特征处理
数值型/类别型/文本型/时间型/统计型/组合型特征处理
统计值max、min、mean、std
离散化:等距、等频,连续值one-hot成向量(pd.cut)
Hash分桶:K-means聚类分组
试试 数值型 => 类别型
Hash技巧:文本——>bag of words——>Hash技巧分桶向量降维


bag-of-word
n-gram
TF-IDF:

word2vec:映射到固定维度向量后,原空间向量的关系被保留
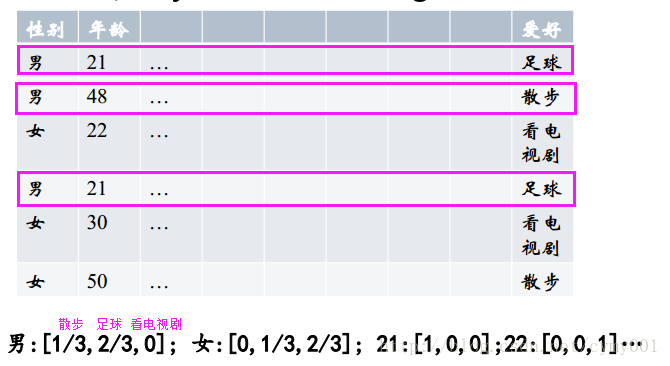
用GBDT产出特征组合路径:GBDT的主树一条路径上包含的特征
组合特征和原始特征一起放进LR训练


特征选择的方式
原因:冗余——部分特征的相关度太高了, 消耗计算性能。噪声——部分特征是对预测结果有负影响
特征选择 VS 降维:前者只踢掉原本特征里和结果预测关系不大的, 后者做特征的计算组合构成新特征。SVD或者PCA确实也能解决一定的高维度问题
过滤型Filter:评估每个特征和结果值的相关程度,排序留下top相关的n个特征(Pearson相关系数、互信息、距离相关度等去判定,缺点是没有考虑特征之间的关联作用,比如特征1和特征6分别对结果作用不大,但是特征1和特征6关联在一起后的特征对结果作用大)(sklearn里SelectKBest,SelectPercentile)
包裹型Wrapper:把特征选择看做一个特征子集搜索问题,递归地删除特征

(sklearn里RFE)
嵌入型Embedded:根据模型分析特征的重要性,L1正则化方式做特征选择
(维度较高时使用)
模型参数选择
网格搜索,交叉验证(sklearn里GridSearchCV)
过拟合v.s.欠拟合
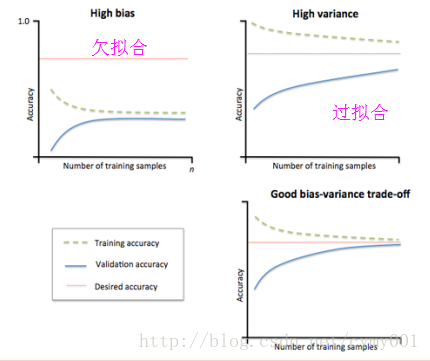
解决过拟合方法
1.增大训练数据集
2.early stopping:记录验证集的accuracy,连续k(自己设定)个Epoch都没提升
3.Dropout:每次训练随机关闭若干神经元(不参数本次迭代训练)
4.正则化L1,L2
解决欠拟合方法
1.找更多特征
2.减小正则化系数
线性模型的权重分析
根据特征系数分许特征重要性
Bad-case分析

模型融合
Bagging:RF

Boosting:
Adaboost(分类树,残差分类器,针对分错的有问题的那部分样本进行训练)
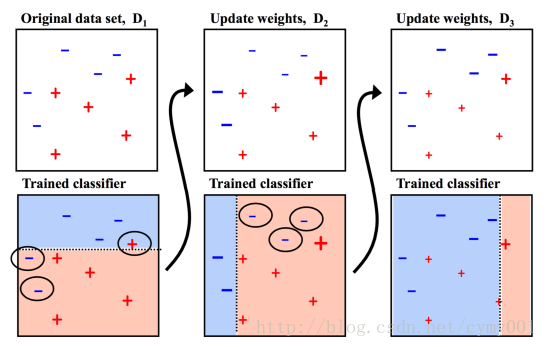
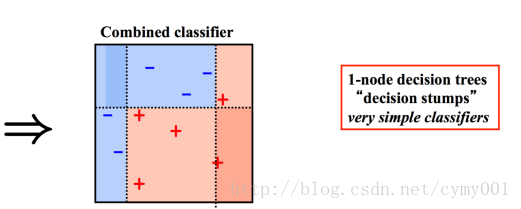
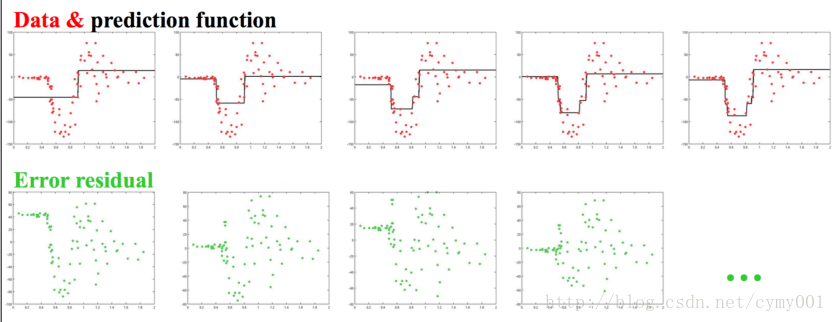
GBDT(回归树,对差值用回归树拟合)
数据格式化
数据量不大,可以存文本,数据库数据量大,放集群hadoop上:hive表,hdfs文件
数据清洗
数据缺省
如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
某一特征列缺省值少:填充
某一特征列缺省值多:去掉该特征列
某一特征列缺省值中等:类别型特征列,当成一类
如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中
正负样本不均衡
树模型对样本不均衡问题敏感度比LR模型(GD)的敏感度低。1.)欠采样:当数据量比较大时,对训练集中较多样本抽样,即去掉一部分该类样本,采样原则——分层抽样,随机抽样
选用Random Forest策略训练模型
可视化考察其分布(e.g. 金融风控比赛)
2.)过采样:当数据量不大时,增加一些训练集中较少的样本,使正负样本数相当
k近邻查找近邻点,进行插值
3.)阈值移动:不改变样本数量,对预测结果类别判定的阈值设定加入缩放因子(修改损失函数,破坏损失函数的凹凸性)
e.g.:m+表示正例数目,m−表示反例数目,根据模型的某样本的整理可能性为y,则预测类别时需要考虑的是y1−y/m+m−=y1−y⋅m−m+和1的关系,1表示正负样本数目相当时的阈值
数据与特征处理
数值型/类别型/文本型/时间型/统计型/组合型特征处理数值型:
幅度调整、归一化normalization(sklearn里MinMaxScaler,StandardScaler)统计值max、min、mean、std
离散化:等距、等频,连续值one-hot成向量(pd.cut)
Hash分桶:K-means聚类分组
试试 数值型 => 类别型
类别型:
one-hot编码(get-dummies)Hash技巧:文本——>bag of words——>Hash技巧分桶向量降维
时间型:
既可以看做连续值, 也可以看做离散值文本型:
文本数据预处理后, 去掉停用词, 剩下的词组成的list,在词库中的映射稀疏向量。bag-of-word
n-gram
TF-IDF:
word2vec:映射到固定维度向量后,原空间向量的关系被保留
组合型:
组合特征下对应的变量统计值histogram(分布状况),用笛卡尔积组织新组合特征,获得两个特征维度的交叉关系(在组合特征上出现是1,否则是0,使用组合特征会导致组合特征维度暴增,可以先对用户或者商品聚类,再进行组合)用GBDT产出特征组合路径:GBDT的主树一条路径上包含的特征
组合特征和原始特征一起放进LR训练
特征选择的方式
原因:冗余——部分特征的相关度太高了, 消耗计算性能。噪声——部分特征是对预测结果有负影响特征选择 VS 降维:前者只踢掉原本特征里和结果预测关系不大的, 后者做特征的计算组合构成新特征。SVD或者PCA确实也能解决一定的高维度问题
过滤型Filter:评估每个特征和结果值的相关程度,排序留下top相关的n个特征(Pearson相关系数、互信息、距离相关度等去判定,缺点是没有考虑特征之间的关联作用,比如特征1和特征6分别对结果作用不大,但是特征1和特征6关联在一起后的特征对结果作用大)(sklearn里SelectKBest,SelectPercentile)
包裹型Wrapper:把特征选择看做一个特征子集搜索问题,递归地删除特征
(sklearn里RFE)
嵌入型Embedded:根据模型分析特征的重要性,L1正则化方式做特征选择
(维度较高时使用)
模型参数选择
网格搜索,交叉验证(sklearn里GridSearchCV)过拟合v.s.欠拟合
解决过拟合方法
1.增大训练数据集2.early stopping:记录验证集的accuracy,连续k(自己设定)个Epoch都没提升
3.Dropout:每次训练随机关闭若干神经元(不参数本次迭代训练)
4.正则化L1,L2
解决欠拟合方法
1.找更多特征2.减小正则化系数
线性模型的权重分析
根据特征系数分许特征重要性Bad-case分析
模型融合
Bagging:RFBoosting:
Adaboost(分类树,残差分类器,针对分错的有问题的那部分样本进行训练)
GBDT(回归树,对差值用回归树拟合)

相关文章推荐
- 不会做特征工程的 AI 研究员不是好数据科学家!上篇 - 连续数据的处理方法 本文作者:s5248 编辑:杨晓凡 2018-01-19 11:32 导语:即便现代机器学习模型已经很先进了,也别
- 机器学习处理流程、特征工程,模型设计实例
- 数据挖掘sklearn中的的特征工程处理
- 【特征工程系列2】如何获得训练数据的标签?
- 【数据平台】sklearn库特征工程之数据预处理
- 从数据预处理到特征工程
- 大数据:“人工特征工程+线性模型”的尽头
- 大数据:“人工特征工程+线性模型”的尽头
- CIFAR_10处理数据——搭建模型——训练模型
- 大数据:“人工特征工程+线性模型”的尽头
- 【特征工程】2 机器学习中的数据清洗与特征处理综述
- 大数据:“人工特征工程+线性模型”的尽头
- 特征工程探索之数据预处理
- 机器学习——特征工程之数据预处理
- 大数据:“人工特征工程+线性模型”的尽头
- 大数据:“人工特征工程+线性模型”的尽头
- 【转载】大数据:“人工特征工程+线性模型”的尽头
- 简单的特征工程:数据处理
- 大数据:“人工特征工程+线性模型”的尽头
- SpringMVC处理模型数据