简单的特征工程:数据处理
2018-02-04 11:19
267 查看
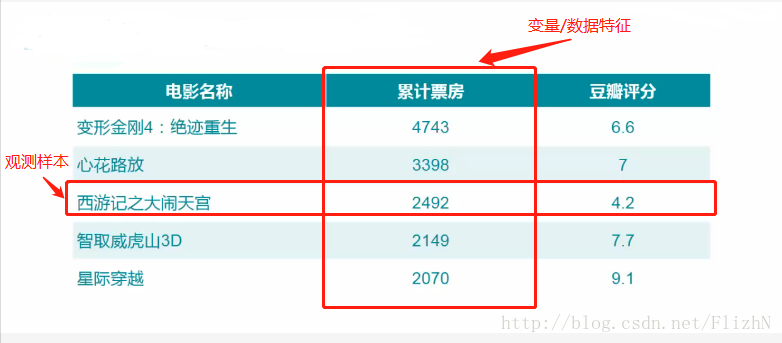
图:小蚊子数据挖掘实战
特征工程:从 原始数据中提取特征以供
算法和模型 使用。
数据和特征决定着机器学习的上限
算法和模型逼近着机器学习的上限。
特征工程的三个基本内容:
1、数据处理 2、特征选择 3、维度压缩
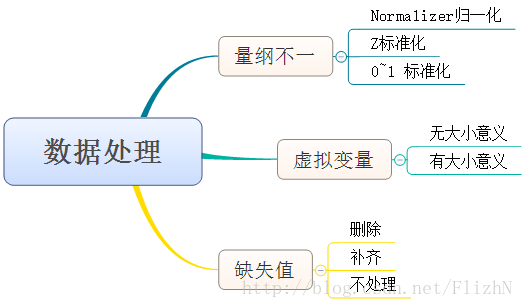
一、数据处理
①量纲不一 ②虚拟变量 ③缺失值填充1、量纲不一
三种标准化方法:①0~1 标准化 ②Z标准化 ③Normalizer归一化
(具体算法见文末)
量纲不一的处理方法:sklearn.preprocessing
from sklearn.preprocessing import *
函数实现:
0~1标准化的MinMaxScaler()
#Min-Max标准化 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() data['标准化column'] = scaler.fit_transform(data['column'].reshape(-1,1))
Normalizer归一化的Normalizer()
#Normalizer归一化 from sklearn.preprocessing import Normalizer scaler = Normalizer() data['归一化累计票房'] = scaler.fit_transform(data['累计票房'].reshape(1,-1),
z标准化
#Z-Score标准化 from sklearn.preprocessing import scale data['标准化column'] = scale(data['column'])
2、虚拟变量
两种虚拟变量类型①有大小的虚拟变量: ②无大小的虚拟变量
虚拟变量的处理方法:pandas的map和get_dummies方法
函数实现:
有大小的虚拟变量
mydict = {'博士':3,'研究生':2,'本科生':1} #定义大小的字典
pandas.Series.map(dict) #将字典作为map方法的参数无大小的虚拟变量
pandas.get_dummies(data,prefix=None,prefix_sep='_',dummy_na=False,columns=None,drop_first=False)
参数解析:
①data 要处理的DataFrame
②prefix 列名的前缀,在多个列有相同的离散项时候使用
③prefix_sep 前缀和离散值的分隔符,默认为下划线,默认即可
④dummy_na 是否把NA值,作为一个离散值进行处理,默认不处理
⑤columns 要处理的列名,如果不指定该列,那么默认处理所有列
⑥drop_first 是否从备选项中删除第一个,建模的是否为避免共线性使用
get_dummies使用中的坑。。
要进行虚拟变量转换的列要先用.astype('category')转换为数据转换成‘category’类型;
data['症状'] = data['症状'].astype('category')多个数据源的时候,可能虚拟变量字段无法统一,所以要将标准字段的数据类型复制过来,用cat方法.
newdata['症状'] = newdata['症状'].astype('category',categories=data['症状'].cat.categories)3、缺失值
三种缺失值的处理方法①数据补齐 ②数据删除 ③数据不处理
缺失值补齐的方法:sklearn.preprocessing
from sklearn.preprocessing import Imputer; #'mean', 'median', 'most_frequent' #三种可选的参数 imputer = Imputer(strategy='mean') imputer.fit_transform(data[['累计票房']])
二、简单的特征工程:特征选择
三、简单的特征工程:维度压缩
附:几个统计学方法的计算原理0~1 标准化

Z标准化

Normalizer归一化
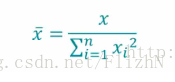
虚拟变量的处理方法:pandas的map和get_dummies方法

相关文章推荐
- 不会做特征工程的 AI 研究员不是好数据科学家!上篇 - 连续数据的处理方法 本文作者:s5248 编辑:杨晓凡 2018-01-19 11:32 导语:即便现代机器学习模型已经很先进了,也别
- 【数据平台】sklearn库特征工程之数据预处理
- 从数据预处理到特征工程
- 特征工程探索之数据预处理
- 【特征工程】2 机器学习中的数据清洗与特征处理综述
- 机器学习——特征工程之数据预处理
- 特征工程:数据处理,模型训练集锦(二)
- 数据挖掘sklearn中的的特征工程处理
- Vue.js实现简单动态数据处理
- 图像处理之特征提取(二)之LBP特征简单梳理
- 简单处理BarTender中的数据合并问题
- 处理IOT中纷繁的数据与消息_从未如此简单
- 简单处理音频输入数据的类
- 数据预处理 | 机器学习之特征工程
- 实时计算,流数据处理系统简介与简单分析
- 数据降维处理:PCA之特征值分解法例子解析
- 机器学习中的数据清洗与特征处理综述
- 【利用perl的基因数据处理】1.基础的的DNA文件读写和碱基特征统计
- 机器学习中的数据清洗与特征处理综述(转)
- Kaggle_news_stock简单文本特征处理