Flume系列一之架构介绍和安装
2017-11-21 11:10
686 查看
Flume架构介绍和安装
写在前面在学习一门新的技术之前,我们得知道了解这个东西有什么用?我们可以使用它来做些什么呢?简单来说,flume是大数据日志分析中不能缺少的一个组件,既可以使用在流处理中,也可以使用在数据的批处理中。
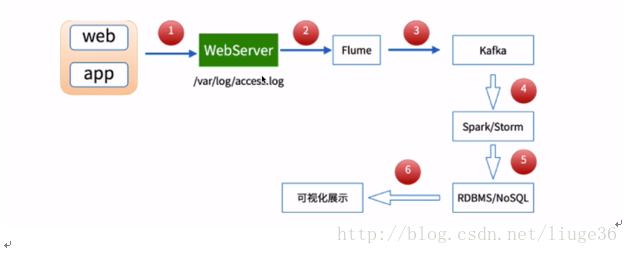
1.流处理:
2.离线批处理:
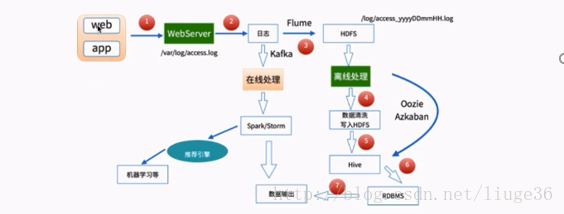
分析:不管你是数据的实时流处理,还是数据的离线批处理,都是会使用flume这个日志收集框架来做日志的收集。因此,学习这个这个组件是很重要的。这个组件的使用也是很简单的。
简单介绍一下Flume
Flume是一种分布式的、可靠的、可用的服务,用于高效地收集、聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调的可靠性机制和许多故障转移和恢复机制,具有健壮性和容错性。它使用一个简单的可扩展的数据模型,允许联机分析应用程序。
一句话总结:Flume就是用来做日志收集的这么一个工具
Flume架构介绍
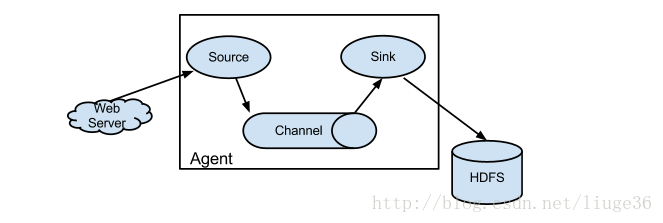
1) Source 收集 (从webserver读取数据到Channel中去)
2) Channel 聚集 (减少直接与磁盘的对接次数(生产环境中一般使用类型为Memory),当channel满了,再写到sink中去。同时,也起到了容错的作用,因为只有当sink接收到了数据,channel才会把原有的数据丢弃)
3) Sink 输出(从channel中读取数据,写到目的地,这里的目的地可以是HDFS、其余的一些文件系统或者作为下一个agent的source等)
顺便说一下
Event的概念
在整个数据的收集聚集传送的过程中,流动的是event,即事务保证是在event级别进行的。
那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。
event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
为了方便大家理解,给出一张event的数据流向图:
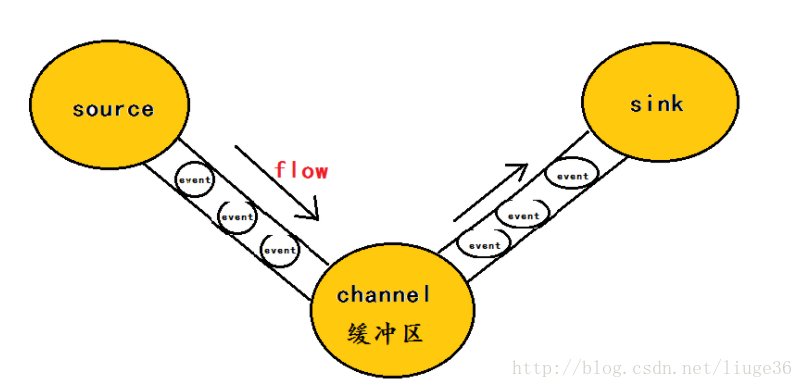
上面这段引用来自大神“安静的技术控”的文章,因为我觉得大神已经解释得很到位了。很好理解,在这里,感谢大神啦
工欲善其事,必先利其器
因为有的小伙伴可能还没有安装flume组件,接下来我们就开始介绍一下flume的安装。
我们也可以去官网看一下,怎么安装。
System Requirements
Java Runtime Environment - Java 1.8 or later
Memory - Sufficient memory for configurations used by sources, channels or sinks
Disk Space - Sufficient disk space for configurations used by channels or sinks
Directory Permissions - Read/Write permissions for directories used by agent
这段话,简单解释:我们必须得安装java1.8或者更高版本,内存要足够(因为我们的Channel一般是写在内存上的),磁盘空间要足够,还有就是对我们代理中的目录要有读写权限
说明:Flume的安装是不需要Hadoop集群的环境的
(一)安装JDK
到官网下载jdk1.8,下载地址
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
或者,也可以使用我分享的链接地址(64位):
链接:http://pan.baidu.com/s/1hsvQmB6 密码:a1gh
解压到自己常用的目录,我一般喜欢解压到~/app/目录下,这个都可以,按照自己的习惯就好
配置java的系统环境变量,把我们解压出来的东西export导出
[hadoop@hadoop000 app]$ vim ~/.bash_profile #新增导出的java环境,JAVA_HOME后面的值为自己的解压目录 export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144 export PATH=$JAVA_HOME/bin:$PATH #:wq 保存退出 [hadoop@hadoop000 app]$ source ~/.bash_profile #回车就好,使得刚刚的导出生效 #验证配置 [hadoop@hadoop000 app]$ java -version java version "1.8.0_144" Java(TM) SE Runtime Environment (build 1.8.0_144-b01) Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode) [hadoop@hadoop000 app]$
(二)安装flume
下载flume,推荐使用cdh5版本的,地址:
http://archive.cloudera.com/cdh5/cdh/5/
这里需要说明一下,虽然我们前面说过不需要hadoop集群环境,但是后面我们肯定是需要结合集群来实现我们的业务情景的,所以在选型的时候就得注意,选择和hadoop集群一致版本的flume,还有就是没有使用官网的版本,是因为cdh已经为我们解决掉了很多的依赖和冲突,这样使用起来会更加方便。不会让我们的开发在困扰在解决没必要的东西上
同样,下载自己合适的版本之后,就是开始解压到指定目录,然后导出我们的解压目录,再source。如果你多操作几次,就会发现,这个操作是大数据里面安装各种组件的一致操作。
[hadoop@hadoop000 app]$ vim ~/.bash_profile # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi # User specific environment and startup programs export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144 export PATH=$JAVA_HOME/bin:$PATH export FLUME_HOME=/home/hadoop/app/flume export PATH=$FLUME_HOME/bin:$PATH #:wq 保存退出
3.来到flume下的conf文件目录下:
[hadoop@hadoop000 conf]$ cp flume-env.sh.template flume-env.sh [hadoop@hadoop000 conf]$ [hadoop@hadoop000 conf]$ vim flume-env.sh #修改这里默认的JAVA_HOME为自己的java目录 export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144 #:wq保存退出
4.测试是否安装成功
[hadoop@hadoop000 conf]$ flume-ng version Flume 1.6.0-cdh5.7.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: 8f5f5143ae30802fe79f9ab96f893e6c54a105d1 Compiled by jenkins on Wed Mar 23 11:38:48 PDT 2016 From source with checksum 50b533f0ffc32db9246405ac4431872e [hadoop@hadoop000 conf]$
到这里我们的环境就搭建成功了,接下来,我们就可以开始我们的Flume之旅啦….
推荐Flume系列二之案例实战
http://blog.csdn.net/liuge36/article/details/78591367
.

相关文章推荐
- Flume系列一之架构介绍和安装
- GoldenGate 12.3 MA架构介绍系列(1) - 安装
- Kafka系列一之架构介绍和安装
- Solr系列一:Solr(Solr介绍、Solr应用架构、Solr安装使用)
- Kafka系列一之架构介绍和安装
- ArcSDE安装介绍系列二
- Linux性能监控工具sysstat系列:介绍与安装
- LNMP架构介绍,MySQL安装,PHP安装,Nginx介绍
- Flume架构以及应用介绍
- Tomcat基础架构的介绍与安装
- Vmware vSphere 5.0系列教程之三 vCenter介绍及安装配置 推荐
- 具体说明 Flume介绍、安装和配置
- percona-toolkit系列之介绍和安装(mysql复制工具)
- Redis系列(一)——介绍及安装配置
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
- LAMP架构和MySQL_MariaDB介绍及MySQL安装
- 【TX1学习与开发系列】(一)介绍与刷机安装、配置
- Trove系列(二)—Trove 的架构和流程介绍
- Hadoop入门进阶课程12--Flume介绍与安装
- Tokyo Tyrant(TTServer)系列-介绍、安装以及应用