关于PCA降维原理的几点思考
2017-11-10 11:24
309 查看
在多变量分析及数据挖掘中,Principal Component Analysis(PCA)降维原理估计是最古老也是最著名的。PCA降维原理分别在三个领域中被发现:Pearson在研究生物结构时发现,Hotelling在心理测定领域发现该原理,Karhunen 在随机过程的框架下发现PCA原理,随后Lo`eve对其进行了归纳总结,故PCA变换也被称为K-L变换。由此可以看出,PCA原理分别在三个领域中被独立发现,可见PCA原理应用之广泛。PCA原理的公式化表达如下:
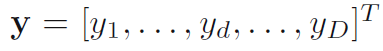
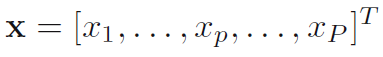
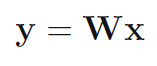
在上式中,y为变换后的特征矢量,x为原始特征矢量,W是变换矩阵。现在来分析一下PCA原理存在的局限性,供有识之士对其作出进一步改进:
1. 在对x进行预处理时,第一步需要对其中心化。中心化后,如果数据的尺度不统一,还需要标准化。通常的标准化方式是除以标准差。这里可能就出出现一个问题,比如标准差很小,接近于零,尤其是被噪声污染的数据,噪声的标准差对数据的放大作用更显著,而没被噪声污染的数据其在标准化的过程中放大作用较小。所以在对数据完全无知的情况下,PCA变换并不能得到较好的保留数据信息。
2. 变换矩阵是被限制为随轴心(维度)变化的,如变换矩阵W是各列之间归一化正交的,各行不是正交的。
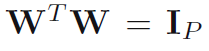
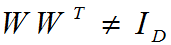
3. 对降维最终得到的数目,也就是潜在的隐变量的数目,不能很好的估计。对潜在的因变量不能很好的估计这一点,对PCA降维的结果将产生重大影响。
4. PCA原理主要是为了消除变量之间的相关性,并且假设这种相关性是线性的,对于非线性的依赖关系则不能得到很好的结果。
5. PCA假设变量服从高斯分布,当变量不服从高斯分布(如均匀分布)时,会发生尺度缩放与旋转。
6. PCA变换是保距型的,拓扑结构不能保持。
可见PCA变换并不是最有效的数据降维方法,根本原因就是它假设数据变量之间是线性相关的并且服从高斯分布,下面来看一个具体的示例:
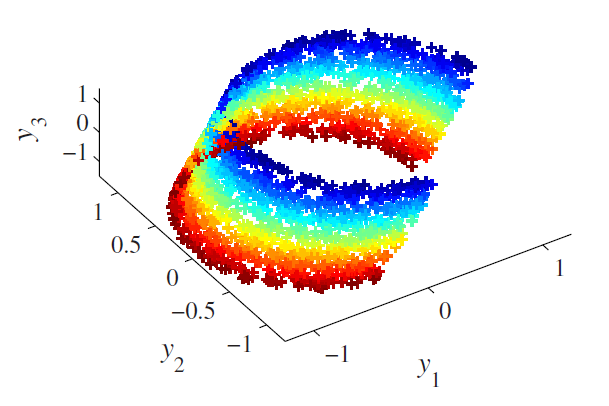
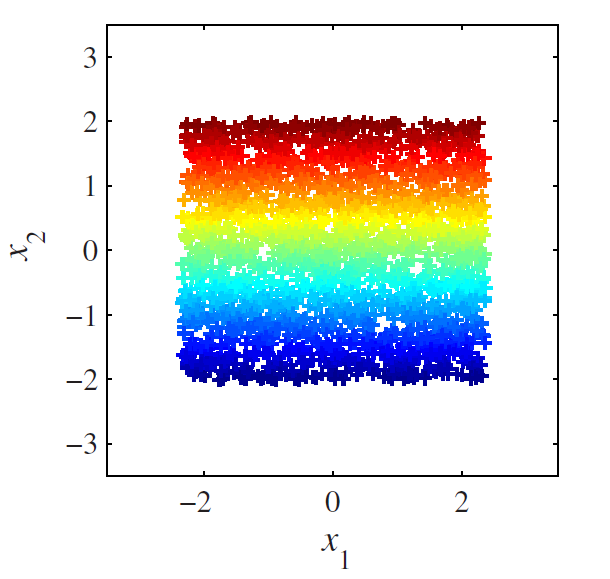
上图显示的是一个二维数据嵌入在一个三维空间里,其真实的潜在的二维数据如下图所示:
用PCA变换降维后的二维数据如下图所示:
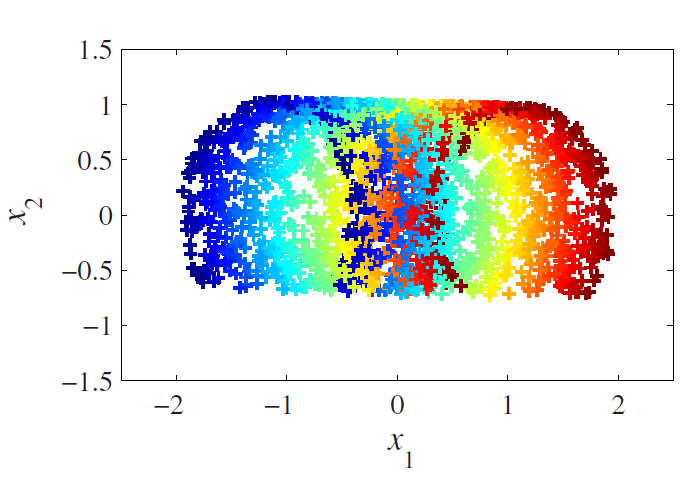
可见,PCA降维后的二维数据与实际二维数据分布差距很大,根源就在于图一三维数据是非线性相关的,怎样把PCA原理扩展到非线性相关领域,一直是一个研究热点。
在上式中,y为变换后的特征矢量,x为原始特征矢量,W是变换矩阵。现在来分析一下PCA原理存在的局限性,供有识之士对其作出进一步改进:
1. 在对x进行预处理时,第一步需要对其中心化。中心化后,如果数据的尺度不统一,还需要标准化。通常的标准化方式是除以标准差。这里可能就出出现一个问题,比如标准差很小,接近于零,尤其是被噪声污染的数据,噪声的标准差对数据的放大作用更显著,而没被噪声污染的数据其在标准化的过程中放大作用较小。所以在对数据完全无知的情况下,PCA变换并不能得到较好的保留数据信息。
2. 变换矩阵是被限制为随轴心(维度)变化的,如变换矩阵W是各列之间归一化正交的,各行不是正交的。
3. 对降维最终得到的数目,也就是潜在的隐变量的数目,不能很好的估计。对潜在的因变量不能很好的估计这一点,对PCA降维的结果将产生重大影响。
4. PCA原理主要是为了消除变量之间的相关性,并且假设这种相关性是线性的,对于非线性的依赖关系则不能得到很好的结果。
5. PCA假设变量服从高斯分布,当变量不服从高斯分布(如均匀分布)时,会发生尺度缩放与旋转。
6. PCA变换是保距型的,拓扑结构不能保持。
可见PCA变换并不是最有效的数据降维方法,根本原因就是它假设数据变量之间是线性相关的并且服从高斯分布,下面来看一个具体的示例:
上图显示的是一个二维数据嵌入在一个三维空间里,其真实的潜在的二维数据如下图所示:
用PCA变换降维后的二维数据如下图所示:
可见,PCA降维后的二维数据与实际二维数据分布差距很大,根源就在于图一三维数据是非线性相关的,怎样把PCA原理扩展到非线性相关领域,一直是一个研究热点。

相关文章推荐
- 关于卷积神经网络原理以及代码实现应用的几点思考
- 关于极光推送技术原理的几点思考
- 关于系统运维监控规范的几点建议和思考
- 关于的网站高性能的几点思考
- 关于自然语言计算机处理的几点思考
- 关于即将到来的软件行业的降维打击的几点想法
- PCA降维原理以及举例
- 关于Random,ThreadLocalRandom,SecureRandom的几点思考
- 关于Android数据库orm工具库对比的几点思考(三)
- 几点关于C/C++开发的思考
- 关于分治和递归的几点思考 有关全排序问题
- 关于微软停止移植 Android 应用的几点思考
- 0909 关于编译原理的思考
- 关于对故障和事故的几点思考 推荐
- 关于项目团队管理的几点思考
- 关于servlet处理http请求和响应原理的前序和思考
- 关于Java中的HashMap的深浅拷贝的测试与几点思考
- 一篇关于PCA数学原理的文章
- 关于.bashrc文件的几点思考
- 关于计算机专业的几点思考