Spark1.0.0 运行架构基本概念
2016-03-17 10:41
549 查看
Spark1.0.0 运行架构基本概念
1、Spark Application的运行架构有哪些组成?2、Spark on YARN 的运行过程是什么?
前言
Spark Application的运行架构由两部分组成:driver program(SparkContext)和executor。Spark Application一般都是在集群中运行,比如Spark Standalone、YARN、mesos,这些集群给Spark Applicaiton提供了计算资源和这些资源管理,这些资源既可以给executor运行,也可以给driver program 运行。根据Spark Application的driver program是否在资源集群中运行,Spark Application的运行方式又可以分为Cluster模式和Client模式。Spark1.0.0提供了一个Spark
Appliaction的部署工具bin/spark-sumbit,具体用法参见Spark1.0.0
应用程序部署工具spark-submit。下面介绍一下Spark1.0.0 运行架构中的基本概念、Standalone中运行过程、YARN中运行过程。
1:基本术语
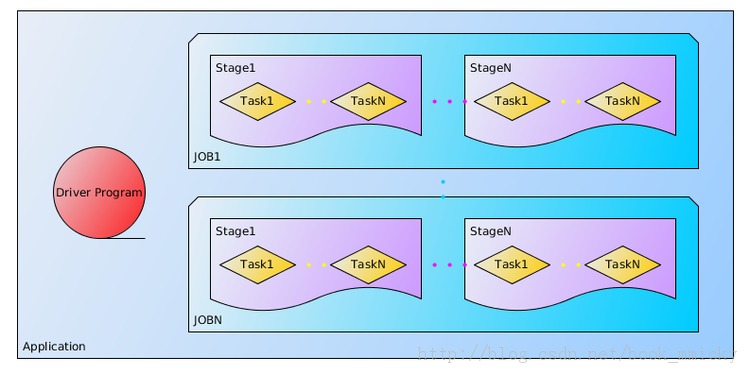
Application: 基于Spark的用户程序,包含了一个driver program 和 集群中多个的executor
Driver Program :运行Application的main()函数并且创建SparkContext,通常用SparkContext代表Driver Program。
Cluster Manager: 在集群上获取资源的外部服务(例如:Standalone、Mesos、Yarn)
Worker Node: 集群中任何可以运行Application代码的节点
Executor: 是为某Application运行在worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个Application都有各自独立的executors。
Task: 被送到某个executor上的工作单元
Job: 包含多个Task组成的并行计算,往往由Spark action催生,该术语可以经常在日志中看到。
Stage: 每个Job会被拆分很多组task,每组任务被称为Stage,也可称TaskSet,该术语可以经常在日志中看到。
RDD:Spark的基本计算单元,可以通过一系列算子进行操作(主要有Transformation和Action操作),详情见RDD 细解、Spark1.0.0 编程模型。
DAG Scheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,详见DAG Scheduler 细解。
TaskScheduler:将Taskset提交给worker(集群)运行并回报结果,详见TaskScheduler 细解。
关于Application中的几个概念可如下图所示:
2:Spark运行架构
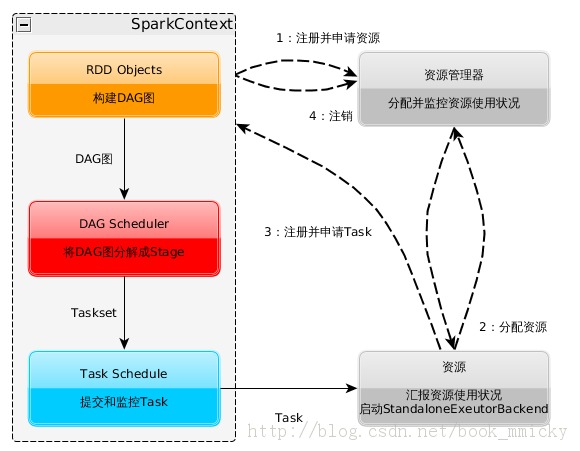
Spark运行架构参见下面示意图:
构建Spark Application的运行环境(启动SparkContext)
SparkContext向资源管理器(可以是Standalone、Mesos、Yarn)申请运行Executor资源,并启动StandaloneExecutorBackend,executor向SparkContext申请Task。
SparkContext将应用程序代码发放给executor
SparkContext构建成DAG图、将DAG图分解成Stage、将Taskset发送给Task Scheduler、最后由Task Scheduler将Task发放给Executor运行。
Task在Executor上运行,运行完毕释放所有资源。
下面简单的描述一下Spark on Standalone和Spark on YARN的运行过程,以后的篇幅中再具体描述。
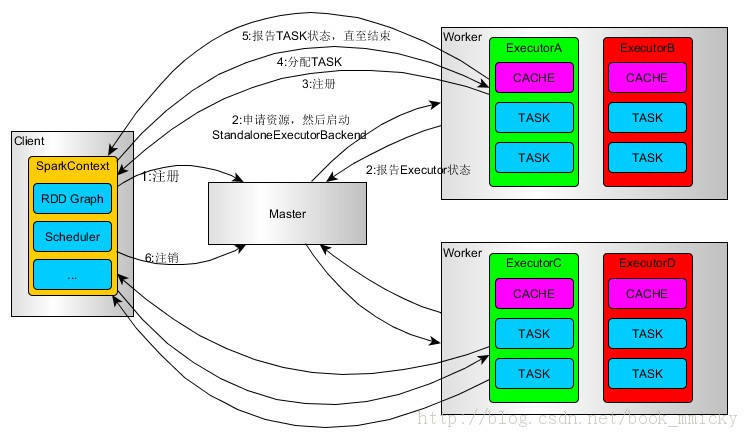
3:Spark on Standalone运行过程(client模式)
SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory)
Master根据SparkContext的资源申请要求和worker心跳周期内报告的信息决定在哪个worker上分配资源,然后在该worker上获取资源,然后启动StandaloneExecutorBackend。
StandaloneExecutorBackend向SparkContext注册
SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析 Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据 和shu f f le之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的worker,最后提交给StandaloneExecutorBackend执行;
StandaloneExecutorBackend会建立executor 线程池,开始执行Task,并向SparkContext报告,直至Task完成。
所有Task完成后,SparkContext向Master注销,释放资源。
关于Spark on Standalone的更详细信息参见Spark1.0.0 on Standalone 运行架构实例解析
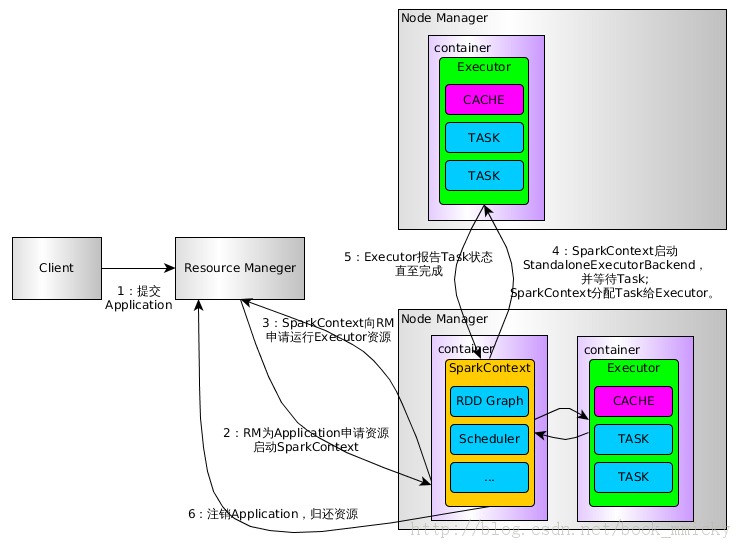
4:Spark on YARN 运行过程(cluster模式)
用户通过bin/spark-submit(
Spark1.0.0 应用程序部署工具spark-submit)或
bin/spark-class 向YARN提交Application
RM为Application分配第一个container,并在指定节点的container上启动SparkContext。
SparkContext向RM申请资源以运行Executor
RM分配Container给SparkContext,SparkContext和相关的NM通讯,在获得的Container上启动 StandaloneExecutorBackend,StandaloneExecutorBackend启动后,开始向SparkContext注册 并申请Task
SparkContext分配Task给StandaloneExecutorBackend执行
StandaloneExecutorBackend执行Task并向SparkContext汇报运行状况
Task运行完毕,SparkContext归还资源给NM,并注销退出。
关于Spark on Standalone的更详细信息参见Spark1.0.0 on YARN 运行架构实例解析
5:Spark运行架构的特点
每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种 Application隔离机制有其优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同 Application的Task运行在不同的JVM中)。当然,这也意味着Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将 SparkContext提交给集群,不要远离Worker运行SparkContext。
Task采用了数据本地性和推测执行的优化机制。详见TaskScheduler 细解。

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Understanding Spark Caching
- ClassNotFoundException:scala.PreDef$
- Windows 下Spark 快速搭建Spark源码阅读环境
- Spark中将对象序列化存储到hdfs
- Spark初探
- Spark Streaming初探
- Spark本地开发环境搭建
- 搭建hadoop/spark集群环境
- Spark HA部署方案
- Spark HA原理架构图
- spark内存概述
- Spark Shuffle之Hash Shuffle
- Spark Shuffle之Sort Shuffle
- Spark Shuffle之Tungsten Sort Shuffle
- 编译Spark 1.5.2