学习笔记-图像识别(Photo OCR)
2017-10-10 22:01
225 查看
The photo OCR problem
Photo OCR 全称 Photo Optical Character Recognition,即图像识别。例如识别下图中的文字:
文字识别的一般步骤如下:
1. 检测文字所在的区域;
2. 字符拆分;
3. 字符识别。

Sliding windows
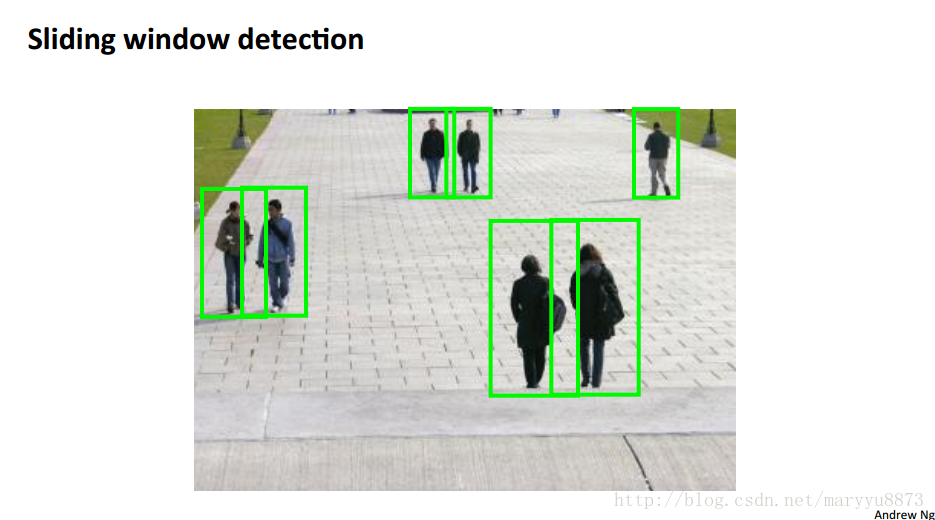
采用滑窗策略来检测目标所在区域。如下图红框均为包含识别目标的滑动框: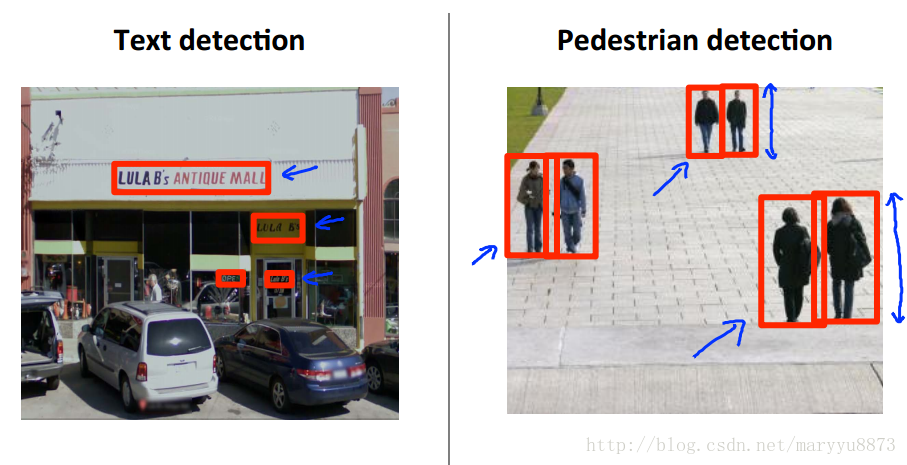
针对每一个选定的窗口,利用监督学习的方法确定该窗口内是否包含待检测目标。

滑框策略的思路:采用比原图像尺寸小的窗口依次检测原图片的每一个区域,判定该区域是否包含待检测目标,如判定窗口内是否包含行人。

由于待检测目标的尺寸并不一致,因此通常需要分别尝试不同大小的窗口。

最终需要实现检测到图片中不同大小的待检测目标。
对于文字识别而言,首先确定每一个包含文字的窗口区域,用白色代表该窗口区域包含文字,用黑色代表该窗口区域不包含有文字;然后将邻近的白色区域连接起来,并过滤掉那些不可能含有文字的形状区域。
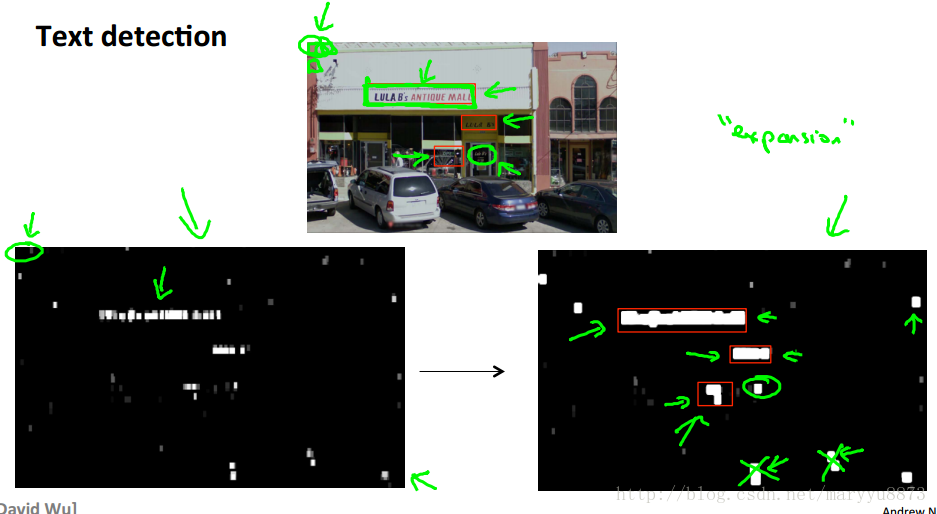
在确定含有文字的区域后,就可以利用监督学习的方法区分一个个字符,即判断是否存在字符间隙。

Getting lots of data: Artificial data synthesis
从之前的学习课程我们了解到,对于很多的机器学习任务,训练集数据集越大越好,然而当已有的数据集大小不足时,我们可以利用已有的训练集数据人工变形转换生成新的训练数据。
例如在训练文字识别器时,可以对原图像增加一些变形获得新的训练样本。
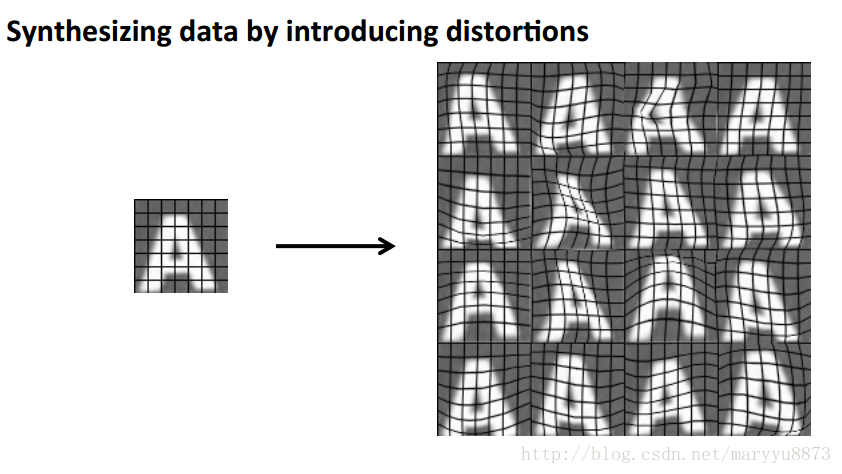
但是也不能任意去增加变形,增加的变形如果在测试集数据里可能会出现才会对模型有帮助,而增加那些毫无意义的背景噪音则很可能对结果不会有任何帮助。

在获取更多数据之前应认真讨论下:
1. 确保增加更多数据对你的模型是有帮助的;
2. 需要花费多少精力才能获得10倍的样本量?

Ceiling analysis: What part of the pipeline to work on next
辛辛苦苦造了一个模型,但结果不尽人意。需要回过头来研究一下整个工作流程的哪个部分改进后对提升结果最有帮助。方法:依次人工帮助工作流的每个部分做到最好,分析验证对结果对提升程度。假如对某个步骤,在人工校正到100%正确后,预测结果获得了很大的提升,则说明该步骤有很大的提升潜力。
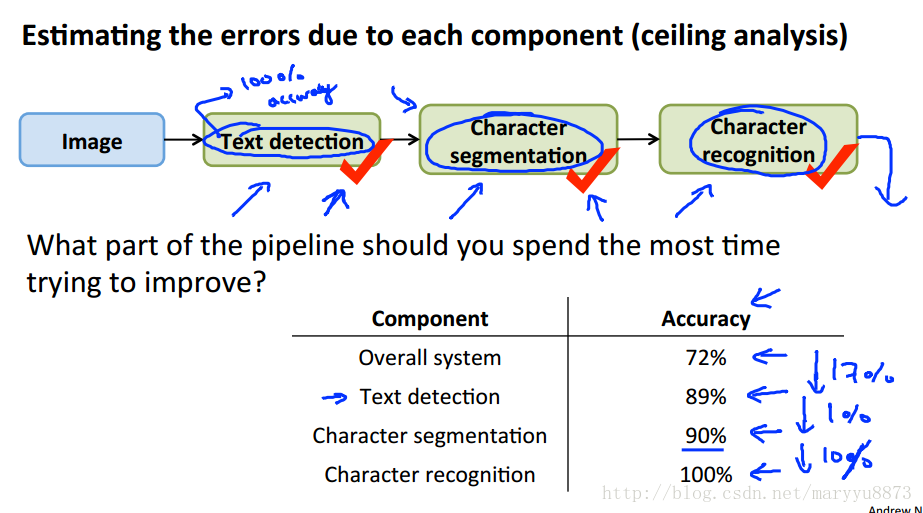
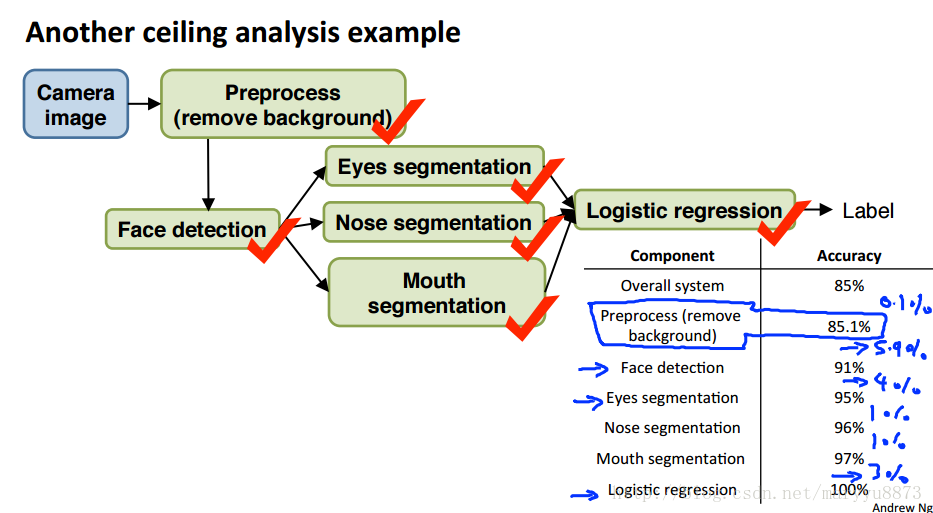
注:如无特殊说明,以上所有图片均截选自吴恩达在Coursera开设的机器学习课程的课件ppt.
虽然已经拿到结业证书一周多了,回想起来依然很激动,很感谢这门课程,我从这门课程中学到了很多。强烈推荐给想入门机器学习的朋友们。


相关文章推荐
- 深度学习在图像识别中的应用--学习笔记1
- 深度学习在图像识别中的应用--学习笔记5
- 【CNTK】CNTK学习笔记之图像识别-树叶识别Train and Test
- Matlab图像处理学习笔记(三):基于匹配的目标识别
- 深度学习在图像识别中的应用--学习笔记4
- 【OpenCV学习笔记】【教程翻译】五 (车牌识别之OCR分割)
- SSD图像识别代码学习笔记
- Andrew Ng机器学习课程笔记--week11(图像识别&总结划重点)
- 深度学习在图像识别中的应用--学习笔记2
- Andrew Ng机器学习课程笔记--week11(图像识别&总结划重点)
- 深度学习在图像识别中的应用--学习笔记3
- Tensorflow学习笔记:CNN篇(9)——Finetuning,复用ImageNet的VGGNet进行图像识别
- Andrew NG 机器学习 笔记-week11-应用实例:图片文字识别(Application Example:Photo OCR)
- 图像识别学习笔记 - 最后一部分非原创
- 深度学习在图像识别中的应用--学习笔记6
- Matlab图像处理学习笔记(三):基于匹配的目标识别
- Matlab图像处理学习笔记(三):基于匹配的目标识别
- Matlab图像处理学习笔记(六):基于sift特征点的人民币识别
- 【笔记】【微信OCR(2):深度序列学习助力文字识别】
- Matlab图像处理学习笔记(六):基于sift特征点的人民币识别