深度学习在图像识别中的应用--学习笔记1
2015-07-14 13:28
344 查看
机器学习以及模式识别均属于人工智能范畴,机器学习源自于计算机科学,
模式识别源自于工程学,尽管这两者源自于不同的背景,但这两者可以认为是同一个领域下的不同描述。
从上世纪九十年代,统计机器学习开始成为主流
统计机器学习的形象解释:如果说一个事物背后有一个函数决定了它的特性,那么我们不再需要研究这个函数究竟是什么形式,只要有足够多的数据,通过统计方法,选取恰当的模型,我们便可以在一定程度上拟合出这个函数,尽管我们拟合出的函数在大多数情况下都不等价于事物的本质函数,但如果它能在可允许的误差范围内正常工作,这就足够了。
统计机器学习的本质:统计学习使得工作重心转为寻找合适的模型上,其本质是"经验风险最小化"。也就是说,我们应该如何寻找一个合适的模型,使得测试误差最小化?
模型分为两种:
1、简单函数---线性函数--容易引起数据不可分---为了可分,又从低纬度转高纬度,又带来计算困难,简称“维数灾难”。
2、复杂函数---例如高斯函数--但问题是选择何种复杂函数,需要结合数据的分 布形式,而高维数据又不可观察。
核函数:为了解决维数灾难,在低维空间中直接计算高维空间返回的结果,避开了高维空间的运算。---例如支持向量机(kernel-SVM)就是一种使用了核方法的分类器。
神经网络:避开复杂函数选取,只需选取激活函数,然后训练网络的连接权值,从而跳过函数选取步骤。
柯尔莫格洛夫(Kolmogorov)证明了:
只要给予足够多的神经元、合适的激活函数以及恰当的权值,任何从输入到输出的连续映射函数都可以用三层神经网络实现。
如果从傅里叶理论上看,则相当于:任何连续函数都可以用足够多的谐波来逼近。
柯尔莫格洛夫的定理说明了神经网络的表达能力与神经网络的层数无关, 只与神经元的数目有关, 似乎我们没有必要加深网络的深度。
Hastad与Goldmann在1991年提出的定理表明:
深度为k的神经网络所能表达的函数,深度为k − 1的神经网络为了达到同样的效果至少需要引入指数级规模的节点。
神经网络和深度学习的发展
受Warren McCulloch与Walter Pitts两人工作的启发下,Frank Rosenblatt提出了第一
个神经元模型—-感知器。标志着神经网络进入第一次浪潮。
感知器
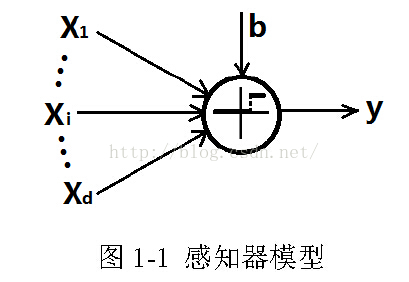
如图1-1 所示,在感知器中,含有d个输入和1个输出,其中非线性激活函数为
阶跃函数,即
式中b为偏置项,有时也称之为阈值。如果从神经科学的角度上解释,在感知
器中,向量x相当于神经元接收到的刺激,而θT x相当于刺激的叠加。当总的刺
激量到达一定阈值b时,神经元被激活,即y = 1,否则神经元对刺激不作反应,
即y = 0。
神经网络第二次浪潮:80-90年代
反向传播:通过链式求导,将偏导数从高层传送回低层,使得多层感知器
网络中可以使用简单的梯度下降方法进行训练,尤其是在三层感知器网络中效果
显著。
九十年代人们开始尝试建立深度神经网络,但随着网络深度的加大,局部最
优解增多,在参数没有被恰当地初始化的情况下,使用反向传播算法进行简单的
梯度下降容易陷入局部极小值,人们难以找到一种较好的方法来训练深度网络。
该时期的模型:1、Hebb规则全连接的反馈网络Hopfield网络
2、将Hopfield网络随机化后的玻尔兹曼机
3.具备模式变换不变性的卷积网络等
第二次浪潮的困局:但随着网络深度的加大,局部最优解增多,在参数没有被恰当地初始化的情况下,使用反向传播算法进行简单的梯度下降容易陷入局部极小值,人们难以找到一种较好的方法来训练深度网络。
神经网络第三次浪潮:06至今
无监督---深度置信网络:Hinton与Osindero在深度置信网络中使用一种无监督的逐层贪婪预训练受限玻尔兹曼机,使得权值被初始化到一个合适的位置,随后对整个网络使用全局的反向传播进行有监督的微调。深度置信网络是一种无监督学习。
无监督---深度卷积网络:由LeCun等人提出的深度卷积网络实现了在深度结构下的有监督学习,成为第一个真正意义上的深度结构。
深度学习在人工智能上的应用
语音识别
(1)传统方法:使用混合高斯模型(GMM)或隐马尔可夫模型(HMM)
(2)深度学习方法:
图像识别
自然语言处理
自然语言处理一个难点在于上下文,尽管深度学习被认为是一种特征学习,但这种特征学习似乎并没有实现可以联系上下文的功能。下一个突破口将会出现在自然语言处理上。
模式识别源自于工程学,尽管这两者源自于不同的背景,但这两者可以认为是同一个领域下的不同描述。
从上世纪九十年代,统计机器学习开始成为主流
统计机器学习的形象解释:如果说一个事物背后有一个函数决定了它的特性,那么我们不再需要研究这个函数究竟是什么形式,只要有足够多的数据,通过统计方法,选取恰当的模型,我们便可以在一定程度上拟合出这个函数,尽管我们拟合出的函数在大多数情况下都不等价于事物的本质函数,但如果它能在可允许的误差范围内正常工作,这就足够了。
统计机器学习的本质:统计学习使得工作重心转为寻找合适的模型上,其本质是"经验风险最小化"。也就是说,我们应该如何寻找一个合适的模型,使得测试误差最小化?
模型分为两种:
1、简单函数---线性函数--容易引起数据不可分---为了可分,又从低纬度转高纬度,又带来计算困难,简称“维数灾难”。
2、复杂函数---例如高斯函数--但问题是选择何种复杂函数,需要结合数据的分 布形式,而高维数据又不可观察。
核函数:为了解决维数灾难,在低维空间中直接计算高维空间返回的结果,避开了高维空间的运算。---例如支持向量机(kernel-SVM)就是一种使用了核方法的分类器。
神经网络:避开复杂函数选取,只需选取激活函数,然后训练网络的连接权值,从而跳过函数选取步骤。
柯尔莫格洛夫(Kolmogorov)证明了:
只要给予足够多的神经元、合适的激活函数以及恰当的权值,任何从输入到输出的连续映射函数都可以用三层神经网络实现。
如果从傅里叶理论上看,则相当于:任何连续函数都可以用足够多的谐波来逼近。
柯尔莫格洛夫的定理说明了神经网络的表达能力与神经网络的层数无关, 只与神经元的数目有关, 似乎我们没有必要加深网络的深度。
Hastad与Goldmann在1991年提出的定理表明:
深度为k的神经网络所能表达的函数,深度为k − 1的神经网络为了达到同样的效果至少需要引入指数级规模的节点。
神经网络和深度学习的发展
受Warren McCulloch与Walter Pitts两人工作的启发下,Frank Rosenblatt提出了第一
个神经元模型—-感知器。标志着神经网络进入第一次浪潮。
感知器
如图1-1 所示,在感知器中,含有d个输入和1个输出,其中非线性激活函数为
阶跃函数,即
式中b为偏置项,有时也称之为阈值。如果从神经科学的角度上解释,在感知
器中,向量x相当于神经元接收到的刺激,而θT x相当于刺激的叠加。当总的刺
激量到达一定阈值b时,神经元被激活,即y = 1,否则神经元对刺激不作反应,
即y = 0。
神经网络第二次浪潮:80-90年代
反向传播:通过链式求导,将偏导数从高层传送回低层,使得多层感知器
网络中可以使用简单的梯度下降方法进行训练,尤其是在三层感知器网络中效果
显著。
九十年代人们开始尝试建立深度神经网络,但随着网络深度的加大,局部最
优解增多,在参数没有被恰当地初始化的情况下,使用反向传播算法进行简单的
梯度下降容易陷入局部极小值,人们难以找到一种较好的方法来训练深度网络。
该时期的模型:1、Hebb规则全连接的反馈网络Hopfield网络
2、将Hopfield网络随机化后的玻尔兹曼机
3.具备模式变换不变性的卷积网络等
第二次浪潮的困局:但随着网络深度的加大,局部最优解增多,在参数没有被恰当地初始化的情况下,使用反向传播算法进行简单的梯度下降容易陷入局部极小值,人们难以找到一种较好的方法来训练深度网络。
神经网络第三次浪潮:06至今
无监督---深度置信网络:Hinton与Osindero在深度置信网络中使用一种无监督的逐层贪婪预训练受限玻尔兹曼机,使得权值被初始化到一个合适的位置,随后对整个网络使用全局的反向传播进行有监督的微调。深度置信网络是一种无监督学习。
无监督---深度卷积网络:由LeCun等人提出的深度卷积网络实现了在深度结构下的有监督学习,成为第一个真正意义上的深度结构。
深度学习在人工智能上的应用
语音识别
(1)传统方法:使用混合高斯模型(GMM)或隐马尔可夫模型(HMM)
(2)深度学习方法:
图像识别
自然语言处理
自然语言处理一个难点在于上下文,尽管深度学习被认为是一种特征学习,但这种特征学习似乎并没有实现可以联系上下文的功能。下一个突破口将会出现在自然语言处理上。

相关文章推荐
- 如何选择MySQL存储引擎
- 日期差
- Sqoop2的安装与使用
- java字符串分割问题
- SQLserver提示数据库中已存在名为 'fk_mxq_Cno' 的对象”
- C多线程编程
- linux下svn修改用户名和密码
- php的优缺点(转)
- 个人规划
- CentOS系统优化系列之“修改时区和时间”
- 文章标题
- windows下统计某ip的指定端口的连接数
- Java日期时间格式
- C++虚函数
- 设置firebug自动启动
- Java身份证验证方法
- poj 2155 二维树状数组 poj 1195 二维树状数组
- svn中的Trunk,branches,tags深度理解
- 阿里云 centos 安装apache和php
- 支付宝支付