深度学习在图像识别中的应用--学习笔记5
2015-07-19 16:02
489 查看
神经网络的反馈
准则函数是对误差的度量,在反馈过程中,实际就是准则函数最优化的过程。
假设函数f(θ)是凸函数,即Hessian矩阵为正定,凸函数的最优问题容易解决。
实际中函数f(θ)为非凸函数,解决的方法之一就是梯度下降法。
梯度下降法的原理:每次的迭代,我们都在当前的θ下计算f(θ)的梯度
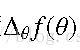
。再让θ加上这个梯度,这就朝着梯度下降的方向迭代了。
问题:每一步是基于当前参数θ,因此这是一个贪婪算法。并不能保证收敛到全局最优。
注意事项:收敛到全局最小值是没有意义的,因为这个全局最小值是基于训练集的最小值,一旦收敛到此处,意味着网络可以很好地刻画训练集,但并不意味它同样可以很
好地泛化到测试集。,这个时候往往会伴随着较高的过拟合风险,我们不应一味地最求全局最小,而应在训练集与测试集两者之间进行一个权衡。梯度下降,因其简单有效的特点,成为优化问题中一个很常用的策略。
softmax分类器的参数校正

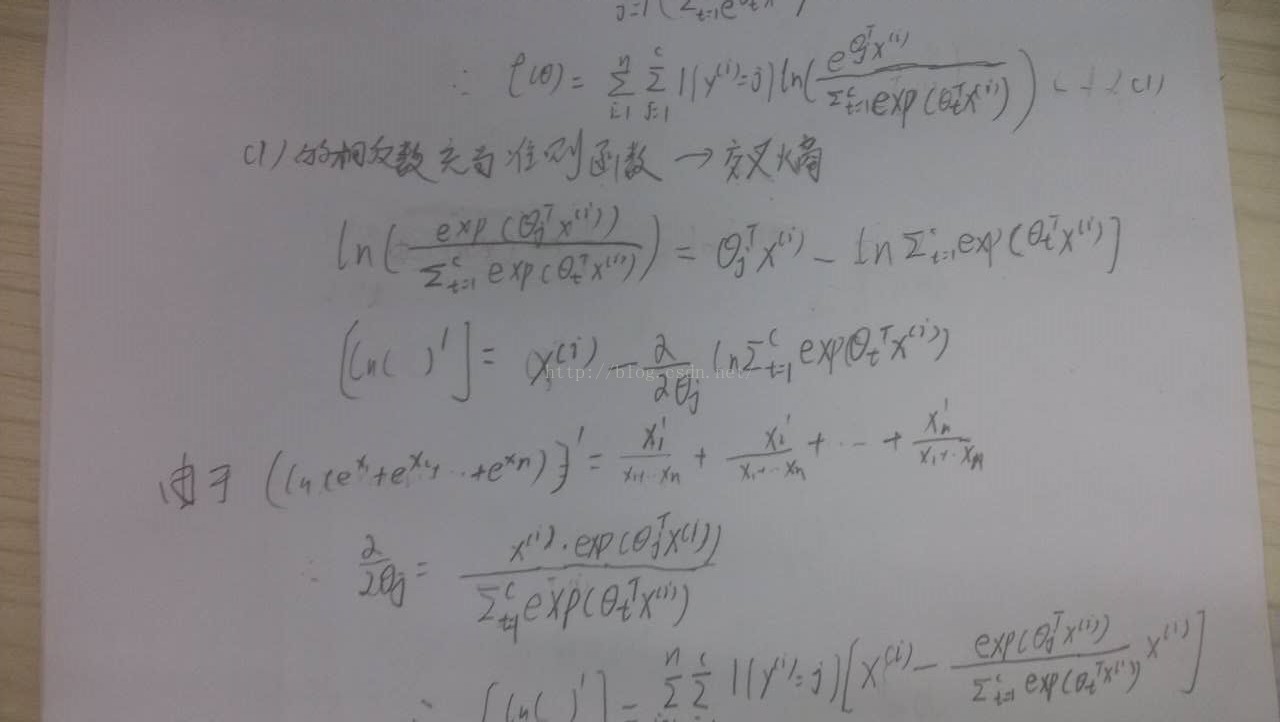
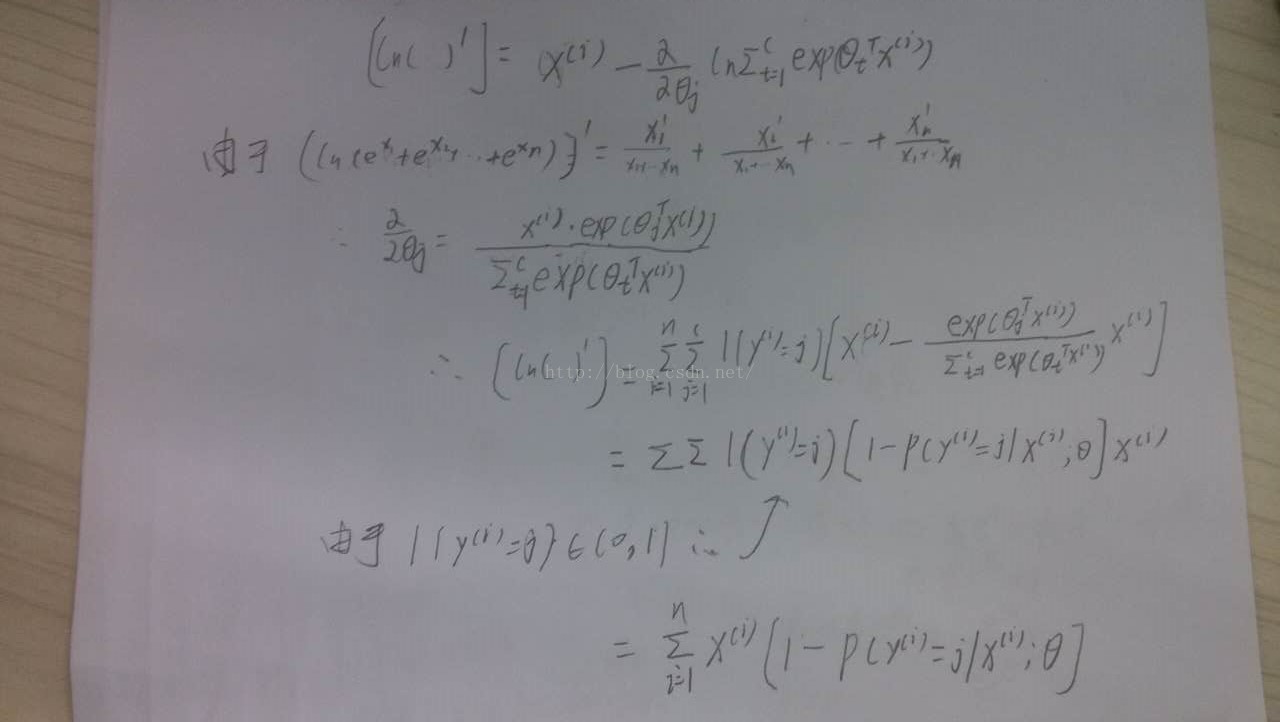
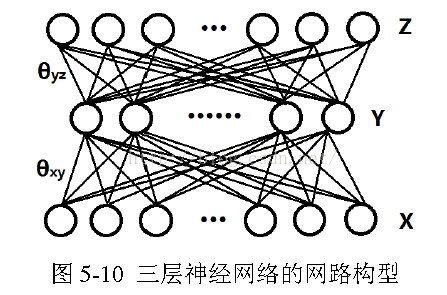
以三层为例,



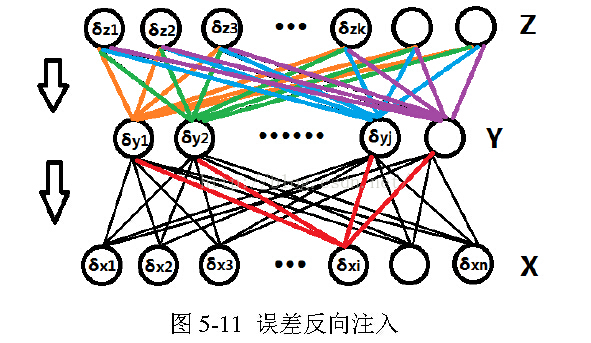
反向传播也是一种贪婪算法,这将会导致一些问题。因为每一次误差传播都是更新参数后再将误差注入回前一层,这并不能保证计算得到的梯度就是真实的梯度,一旦网络的层数过深,将会导致前面层的真实导数与利用反向传播计算得到的导数相差过大。
另外,如果使用sigmoid函数作为激活函数,它将很容易进入饱和状态,前面层的梯度接近于0,从而参数无法更新,这种现象我们称之为梯度消失。一种对抗梯度消失的方法是将sigmoid函数换成ReLU激活函数,关于ReLU为什么可以抵抗梯度消失的原理目前尚未研究出来,但是实验现象表明它确实能抑制梯度消失。
区别是:1、他是一种深层的神经网络。2、以受限玻尔兹曼机为基础。
为何采用深度结构?
答:在神经元总数不变的前提下,深度结构的表达能力比浅结构的表达能力更强。
为何引入受限玻尔兹曼机?
答:因为传统的深度结构无法训练。例如,传统的深层结构会出现梯度消失现。或者传统的神经网络初始值会很大程度地影响网络的收敛性能,而受限玻尔兹曼机一个重要的贡献在于,将深度神经网络的参数初始化到一个较好的值。
深度置信网络的训练分为两个阶段,分别是预训练阶段和参数微调阶段。
预训练阶段:在DBN的预训练阶段中,将相邻两层看做一个受限玻尔兹曼机,采用受限玻尔兹曼机的训练方法,将原始数据作为最底层的输入,每层RBM隐含层的输出作为后一层的输入,然后进行逐层贪婪的无监督训练。
参数微调阶段:在参数微调阶段,接着执行全局的反向传播算法进行有监督的权值微调。通过这样的方法,可以避免单纯地使用反向传播方法中会出现的陷入局部最优问题,由于识别的过程中,数据是逐层地进行维度变化,所以DBN也可以认为是一种特征提取方法,对应的,深度学习有时候也称之为“特征学习。
准则函数是对误差的度量,在反馈过程中,实际就是准则函数最优化的过程。
假设函数f(θ)是凸函数,即Hessian矩阵为正定,凸函数的最优问题容易解决。
实际中函数f(θ)为非凸函数,解决的方法之一就是梯度下降法。
梯度下降法的原理:每次的迭代,我们都在当前的θ下计算f(θ)的梯度
。再让θ加上这个梯度,这就朝着梯度下降的方向迭代了。
问题:每一步是基于当前参数θ,因此这是一个贪婪算法。并不能保证收敛到全局最优。
注意事项:收敛到全局最小值是没有意义的,因为这个全局最小值是基于训练集的最小值,一旦收敛到此处,意味着网络可以很好地刻画训练集,但并不意味它同样可以很
好地泛化到测试集。,这个时候往往会伴随着较高的过拟合风险,我们不应一味地最求全局最小,而应在训练集与测试集两者之间进行一个权衡。梯度下降,因其简单有效的特点,成为优化问题中一个很常用的策略。
softmax分类器的参数校正
误差传播
以三层为例,
反向传播也是一种贪婪算法,这将会导致一些问题。因为每一次误差传播都是更新参数后再将误差注入回前一层,这并不能保证计算得到的梯度就是真实的梯度,一旦网络的层数过深,将会导致前面层的真实导数与利用反向传播计算得到的导数相差过大。
另外,如果使用sigmoid函数作为激活函数,它将很容易进入饱和状态,前面层的梯度接近于0,从而参数无法更新,这种现象我们称之为梯度消失。一种对抗梯度消失的方法是将sigmoid函数换成ReLU激活函数,关于ReLU为什么可以抵抗梯度消失的原理目前尚未研究出来,但是实验现象表明它确实能抑制梯度消失。
深度置信网络
深度置信网路(Deep Belief Networks,简写为DBN)本质就是一种传统的神经网络。区别是:1、他是一种深层的神经网络。2、以受限玻尔兹曼机为基础。
为何采用深度结构?
答:在神经元总数不变的前提下,深度结构的表达能力比浅结构的表达能力更强。
为何引入受限玻尔兹曼机?
答:因为传统的深度结构无法训练。例如,传统的深层结构会出现梯度消失现。或者传统的神经网络初始值会很大程度地影响网络的收敛性能,而受限玻尔兹曼机一个重要的贡献在于,将深度神经网络的参数初始化到一个较好的值。
深度置信网络的训练分为两个阶段,分别是预训练阶段和参数微调阶段。
预训练阶段:在DBN的预训练阶段中,将相邻两层看做一个受限玻尔兹曼机,采用受限玻尔兹曼机的训练方法,将原始数据作为最底层的输入,每层RBM隐含层的输出作为后一层的输入,然后进行逐层贪婪的无监督训练。
参数微调阶段:在参数微调阶段,接着执行全局的反向传播算法进行有监督的权值微调。通过这样的方法,可以避免单纯地使用反向传播方法中会出现的陷入局部最优问题,由于识别的过程中,数据是逐层地进行维度变化,所以DBN也可以认为是一种特征提取方法,对应的,深度学习有时候也称之为“特征学习。

相关文章推荐
- JS高级程序设计13-事件
- 9. Javascript 表达式
- [LeetCode]Rotate the image(在位操作!!)
- vmware centOS 开机进度条 卡死 Determining IP Information for eth0...
- Android实现推送方式解决方案
- linux中运行一个二进制的文件
- java 内存泄露小测试
- NOI 2015 DAY1 T1 程序自动分析 并查集+离散化
- Java Swing编程接口(30)---列表框:JList
- realm simple
- realm tableview
- Objective C中数组排序几种情况的总结
- SQL脚本积累之三-----case....when...的使用示例
- 陈力:传智播客古代 珍宝币 泡泡龙游戏开发第九讲:块元素、行内元素、标准流、盒子模型
- 黑马程序员 About Me
- php实现网站顶踩功能的完整前端代码
- leetcode239:Sliding Window Maximum
- 欢迎使用CSDN-markdown编辑器
- 百度,360 你们谁是骗子?
- 编程中应注意的细节