svm的loss和梯度推导及代码
2017-09-27 09:41
316 查看
svm的loss和梯度推导及代码

这个是svm的计算方式的数学实现,相信大家应该已经很熟悉了,svm算法就是对于每一个样本,计算其他不正确分类与正确分类之间的差距,如果差距大于delta那就说明差距大,需要进行进一步优化,所以对于每个样本,把这些差距加起来,让他们尽量小,这个就是svm的核心思想。
loss就很简单了,还是直接求和。
而梯度,求导相对于softmax就简单了很多,没有复杂的指数求导,我们发现对于w来说,还是一共有wj和wyi两个参数,分别对其求导,其中max函数在括号里面小于0的时候,梯度肯定等于0。接下来就是看大于0的时候,如下,很简单易懂。
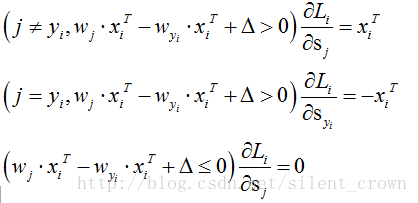
代码块
对于naive算法,assignment上很友善的直接给出了,事实上应该先做svm在做softmax的,还是太年轻哈哈哈,可以看出代码大概跟我们的公式结果一样,如下:def svm_loss_naive(W, X, y, reg): """ Structured SVM loss function, naive implementation (with loops). Inputs have dimension D, there are C classes, and we operate on minibatches of N examples. Inputs: - W: A numpy array of shape (D, C) containing weights. - X: A numpy array of shape (N, D) containing a minibatch of data. - y: A numpy array of shape (N,) containing training labels; y[i] = c means that X[i] has label c, where 0 <= c < C. - reg: (float) regularization strength Returns a tuple of: - loss as single float - gradient with respect to weights W; an array of same shape as W """ dW = np.zeros(W.shape) # initialize the gradient as zero # compute the loss and the gradient num_classes = W.shape[1] num_train = X.shape[0] loss = 0.0 final_result = [] for i in range(num_train): scores = (X[i]).dot(W) correct_class_score = scores[y[i]] for j in range(num_classes): if j == y[i]: continue margin = scores[j] - correct_class_score + 1 # note delta = 1 if margin > 0: loss += margin dW[:,y[i]] += -X[i].T dW[:,j] += X[i].T loss /= num_train dW /= num_train loss += 0.5*reg * np.sum(W * W) dW += reg * W return loss, dW
对于向量化,需要说的就多一点了。我喜欢把W与X的点乘结果叫做得分矩阵,也有人不这么叫。根据公式,需要和正确类做差,所以我们另外声明一个和的分矩阵一个维度的正确矩阵,那这个矩阵首先在每个样本对应的正确类别处对应的元素得是1,其实我们的目的,就是把correct矩阵变成每一行都是正确类别分数的结果,这样做差的时候才能是公式那样的结果。correct的第一步赋值先变成了只有样本的正确类别有效,然后reshape首先压缩成一个【样本数,1】的矩阵,然后做差的时候,根据broadcast属性,会自动延展成【样本数,类别数】的矩阵,numpy在做这种事情的时候真的是很方便,小白感觉很神奇啊。。。
求Loss的时候,直观上看是把每一行的结果相加,先和0取最大值,小于0的无效。然后把矩阵整个求和,做归一化和regularization就行。
求梯度的话,公式是xi的转置,加的次数是j次,这个j就是没有正确分类的情况,所以我们看这种情况有多少个,就是把每一行之前求loss有效的结果先置1,再加起来的个数,由于每次修正错误列的时候还会修正一次正确类别的列,所以直接把这个加和结果rowsum取相反数就是正确类列的导数,乘以X的转置,归一化,regularization。
def svm_loss_vectorized(W, X, y, reg): """ Structured SVM loss function, vectorized implementation. Inputs and outputs are the same as svm_loss_naive. """ loss = 0.0 dW = np.zeros(W.shape) # initialize the gradient as zero scores = X.dot(W) correct = scores[np.arange(X.shape[0]),y] correct = np.reshape(correct,(X.shape[0],1)) s_l = scores - correct + 1.0 s_l[np.arange(X.shape[0]),y] = 0.0 s_l[s_l<=0] =0.0 loss += np.sum(s_l)/X.shape[0] + 0.5*reg*np.sum(W*W) s_l[s_l>0] = 1.0 row_sum = np.sum(s_l,axis = 1) s_l[np.arange(X.shape[0]),y] = -row_sum dW += np.dot(X.T,s_l)/X.shape[0] + reg*W return loss, dW

相关文章推荐
- cs231n assignment1 关于svm_loss_vectorized中代码的梯度部分
- triplet loss 原理以及梯度推导
- xbgoost svm 逻辑回归 梯度下降等推导过程
- 支持向量机(SVM)公式推导及代码对应解释1
- triplet loss 原理以及梯度推导
- Java应用梯度下降求解线性SVM模型参考代码
- triplet loss 原理以及梯度推导
- cs231n - assignment1 - linear-svm 梯度推导
- cs231n - assignment1 - linear-svm 梯度推导
- triplet loss原理推导及其代码实现
- triplet loss 原理以及梯度推导
- 支持向量机 SVM 算法推导优缺点 代码实现 in Python
- SVM原理---公式推导以及核函数
- SVM 中 geometric margin 的推导问题
- 随机梯度下降和批量梯度下降的简单代码实现
- 梯度下降推导过程资料整理
- SVM原理以及Tensorflow 实现SVM分类(附代码)
- 梯度下降法Python代码
- svm理论与实验之17: 两行Java代码尝试LibSVM
- 1.线性回归的推导--梯度下降法