论文笔记:Deep Residual Learning for Image Recognition
2017-09-01 14:25
796 查看
一.简介
论文一开始就强调了网络深度非常重要。
但是实验证实通过简单的叠加网络来增加深度并不能提高效果。
原因有两点:
1.梯度消失和梯度爆炸,阻碍了网络的收敛。这个问题现在已经通过(normalized initialization 和 intermediate normalization layers方法)得到了很大的解决,10层左右的网络通过随机梯度下降可以很好的收敛。
2.当网络开始收敛,新的问题暴露出来:随着网络深度的增加,准确率开始饱和了,然后迅速下降。这种下降并不是由过拟合导致的。(Fig.1 shows a typical example.)
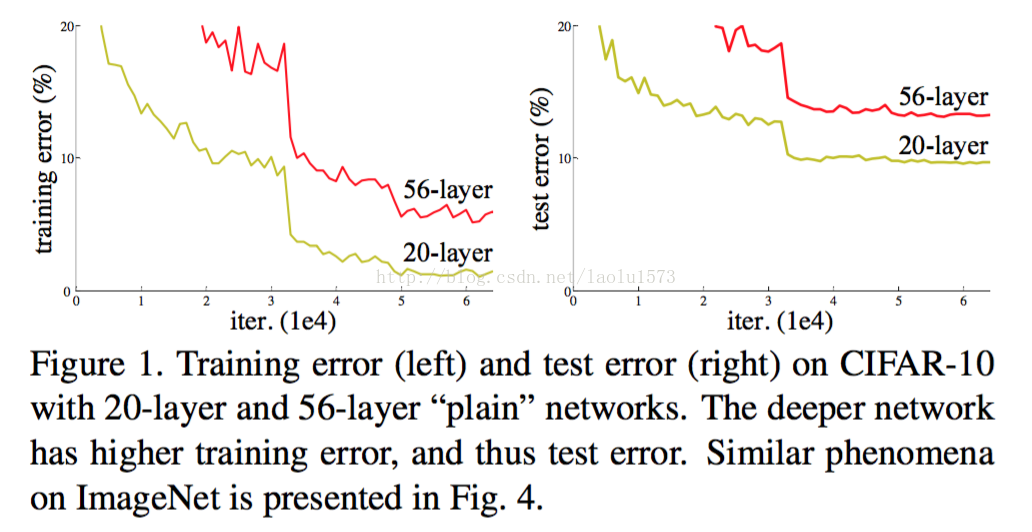
考虑一种结构:浅层网络后面增加identity mapping(恒等映射)的层,其它层直接从浅层模型中复制而来。这种解决方案表明深
度网络的训练误差不应该比浅层网络更高。我们目前无法找到一个与这种构建的解决方案相当或者更好的方案(或者说无法在可行
的时间内实现)。
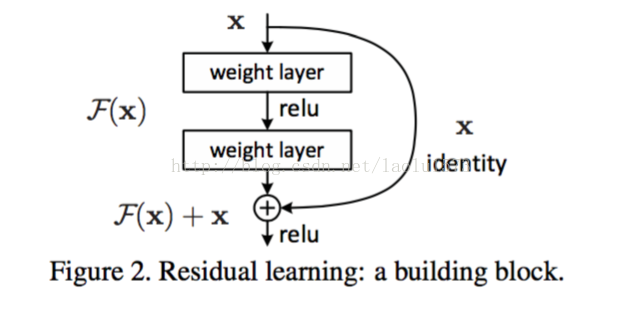
论文提出了一种深度残差网络,来解决退化问题。它不期望堆叠的层能直接拟合期望的映射,而是明确的让这些层去拟合残差
映射。用H(x)表示期望的映射,我们让堆叠的非线性层去拟合另一个映射F(x)
:= H(x) - x。原始的映射就被转换成F(x) + x。我们假设
残差映射比原映射更容易优化。极端情况下,如果一致性映射是最优的,那么把残差推至0比用非线性堆叠层来拟合一致性映射要容
易的多。
F(x)+x的公式可以通过在前馈网络中做一个“快捷连接”来实现(图2)。快捷连接跳过一个或多个层。在我们的例子中,快捷连接简
单的执行一致性映射,它们的输出被添加到叠加层的输出中。自身快捷连接既不会添加额外的参数也不会增加计算复杂度。整个网络
依然可以用SGD+反向传播来做端到端的训练。
二.相关工作
残差表示:
快捷连接:早期训练多层神经网络时的一个实现就是从输入添加一个线性连接层到输出。
三.深度残差学习
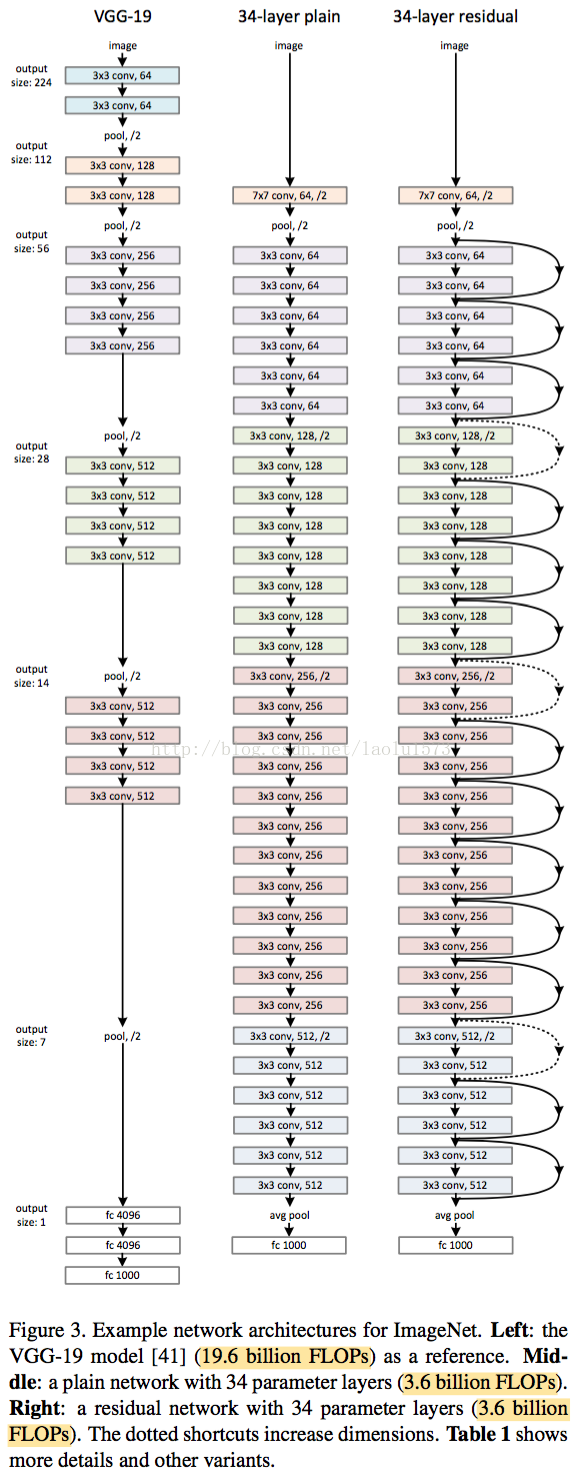
网络结构:
四.实验
实验结果:使用ResNet,不加深网络的时候可以提升收敛速度,加深网络的时候可以降低错误率。
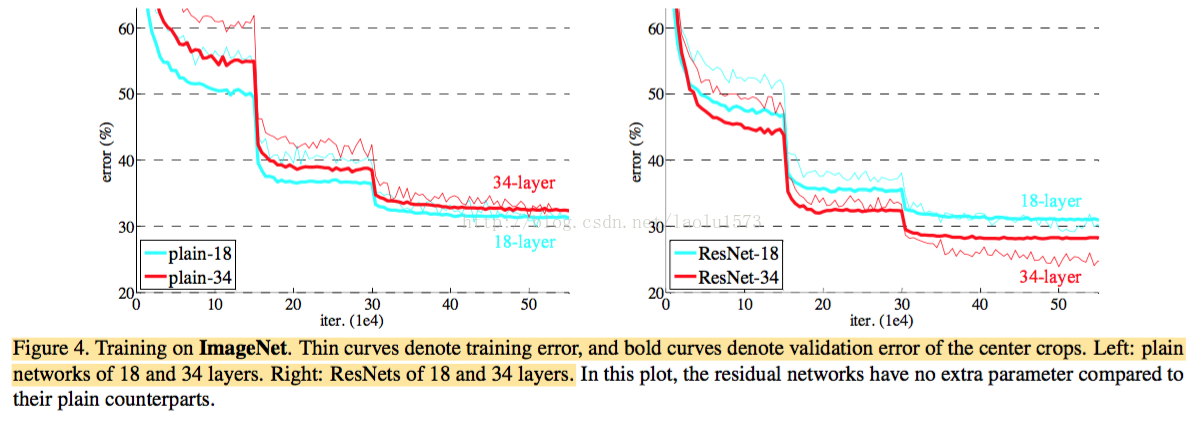
恒等和投影shortcuts :论文比较了三个选项(A) 零填充shortcuts用来增加维度,所有的shortcuts是没有参数的;(B)投影shortcuts用来增加维度,其它的shortcuts是恒等的;(C)所有的shortcuts都是投影。
效果C>B>A,但是不明显,所以用A就可以了,减少内存、时间复杂度和模型大小。
论文一开始就强调了网络深度非常重要。
但是实验证实通过简单的叠加网络来增加深度并不能提高效果。
原因有两点:
1.梯度消失和梯度爆炸,阻碍了网络的收敛。这个问题现在已经通过(normalized initialization 和 intermediate normalization layers方法)得到了很大的解决,10层左右的网络通过随机梯度下降可以很好的收敛。
2.当网络开始收敛,新的问题暴露出来:随着网络深度的增加,准确率开始饱和了,然后迅速下降。这种下降并不是由过拟合导致的。(Fig.1 shows a typical example.)
考虑一种结构:浅层网络后面增加identity mapping(恒等映射)的层,其它层直接从浅层模型中复制而来。这种解决方案表明深
度网络的训练误差不应该比浅层网络更高。我们目前无法找到一个与这种构建的解决方案相当或者更好的方案(或者说无法在可行
的时间内实现)。
论文提出了一种深度残差网络,来解决退化问题。它不期望堆叠的层能直接拟合期望的映射,而是明确的让这些层去拟合残差
映射。用H(x)表示期望的映射,我们让堆叠的非线性层去拟合另一个映射F(x)
:= H(x) - x。原始的映射就被转换成F(x) + x。我们假设
残差映射比原映射更容易优化。极端情况下,如果一致性映射是最优的,那么把残差推至0比用非线性堆叠层来拟合一致性映射要容
易的多。
F(x)+x的公式可以通过在前馈网络中做一个“快捷连接”来实现(图2)。快捷连接跳过一个或多个层。在我们的例子中,快捷连接简
单的执行一致性映射,它们的输出被添加到叠加层的输出中。自身快捷连接既不会添加额外的参数也不会增加计算复杂度。整个网络
依然可以用SGD+反向传播来做端到端的训练。
二.相关工作
残差表示:
快捷连接:早期训练多层神经网络时的一个实现就是从输入添加一个线性连接层到输出。
三.深度残差学习
网络结构:
四.实验
实验结果:使用ResNet,不加深网络的时候可以提升收敛速度,加深网络的时候可以降低错误率。
恒等和投影shortcuts :论文比较了三个选项(A) 零填充shortcuts用来增加维度,所有的shortcuts是没有参数的;(B)投影shortcuts用来增加维度,其它的shortcuts是恒等的;(C)所有的shortcuts都是投影。
效果C>B>A,但是不明显,所以用A就可以了,减少内存、时间复杂度和模型大小。

相关文章推荐
- Deep Residual Learning for Image Recognition--ResNet论文阅读笔记
- 论文笔记 | Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition(ResNet)论文笔记
- 论文笔记: Deep Residual Learning for Image Recognition
- 论文笔记——Deep Residual Learning for Image Recognition
- 论文笔记——Deep Residual Learning for Image Recognition(论文及相关代码)
- [深度学习论文笔记][Image Classification] Deep Residual Learning for Image Recognition
- 深度学习论文笔记 [图像处理] Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition 笔记
- Deep Residual Learning for Image Recognition 笔记
- [深度学习]Deep Residual Learning for Image Recognition(ResNet,残差网络)阅读笔记
- ResNet 《Deep Residual Learning for Image Recognition》 阅读笔记
- Deep Residual Learning for Image Recognition 笔记
- 【那些年我们一起看过的论文】之《Deep Residual Learning for Image Recognition》
- 【深度学习】论文导读:图像识别中的深度残差网络(Deep Residual Learning for Image Recognition)
- ResNet: Deep Residual Learning for Image Recognition 论文阅读
- Deep Residual Learning for Image Recognition 笔记
- 论文阅读学习 - ResNet - Deep Residual Learning for Image Recognition
- 经典文章系列: (ResNet) Deep Residual Learning for Image Recognition 论文阅读
- ResNet论文阅读---《Deep Residual Learning for Image Recognition》