ResNet 《Deep Residual Learning for Image Recognition》 阅读笔记
2017-09-14 14:34
597 查看
1. Introduction
首先作者说明现在很多效果很好的网络都采用了比较深的网络结构,那么想要获得性能更好的网络,是否只需要叠加层数就行了呢?作者的实验结果如下
这个问题的一个阻碍就是臭名昭著的梯度爆炸和梯度消失问题会导致无法收敛,但是这个问题通过标准化的初始化和BN这样的方法基本可以解决。
虽然可以收敛,但是还有一个问题叫degradation,就是当网络变深,准确率会先饱和然后下降。并且这还不是过拟合的问题,因为它是出现在训练集上的:训练误差变大。
有一个解决方案就是增加一个identity的映射,将浅层的模型拷贝到深层模型上(我理解的大意就是浅层模型一样,后面模型全都是1,那么深层模型的结果就应该和浅层一样,所以深层模型应该是包含了浅层模型的),所以浅层的模型不应该比浅层效果差。但是实现结果并不是如此,深层就是效果差,很尴尬!
于是作者就提出了大名鼎鼎的残差神经网络结构(ResNet),思想如下图
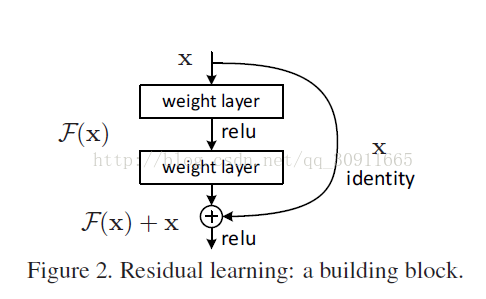
如果图2没有那个identity就是一般的卷积神经网络,假设我们需要学习H(X),如果卷积层学到的映射是F(X),那么这里H(X)就是F(X), 我们要通过卷积层学习从X到F(X)的映射,但是现在我们加入一个identity映射让H(X) = F(X)+X, 我们卷积层学到的还是F(X), 那么我们需要通过卷积层学习的是不是就是 F(X) = H(X) - X 了? 所以F(X) = H(X) -X就是残差!就是这么简单!为啥要这样做,因为作者认为学习残差F(X)比直接学习H(X)简单!
作者将 这种identity叫做 “shortcut connections”,一般会跳过一个或者多个卷积层,极端一点,如果H(X)的最优结果就是X,那残差直接设置成0就行,不需要做复杂的非线性变换了。
作者的实验结果表明这种结构可以解决网络变深后训练误差变大的问题。
2. Related Work
作者说这种残差的形式由来已久,然后说有一种“highway networks”,采用了类似的“shortcut connectionsa395
”结构,不过加入了“gate”(大概和LSTM差不多?),它的“gate”带参数,需要学习。
3. Deep Residual Learning
3.1. Residual Learning
作者认为如果H(X)可以被学习到,那么H(X) -X也一定可以学到,但是作者认为H(X) -X也就是残差学起来更容易。3.2. Identity Mapping by Shortcuts
一个34层的网络结构图
4. Experiments
4.1. ImageNet Classification
左边是简单卷积叠加的网络,右边是ResNet,显然左边18层效果比34层好,而右边则相反Identity vs. Projection Shortcuts.
作者采取了三个方式
(A)为了增加维度,当输入输出不一致的时候用0填充
(B)维度一致用identity,不同则一个进行映射投影
(C)全部进行线性投影
结果C略好于B略好于A,不过会C降低模型的大小,所以文中不使用这种方式。
Deeper Bottleneck Architectures
作者为了使用更深的网络,采用了下图的Bottleneck 结构,不是两层一个shortcut而是三层一个shortcut,1*1是是为了增加维度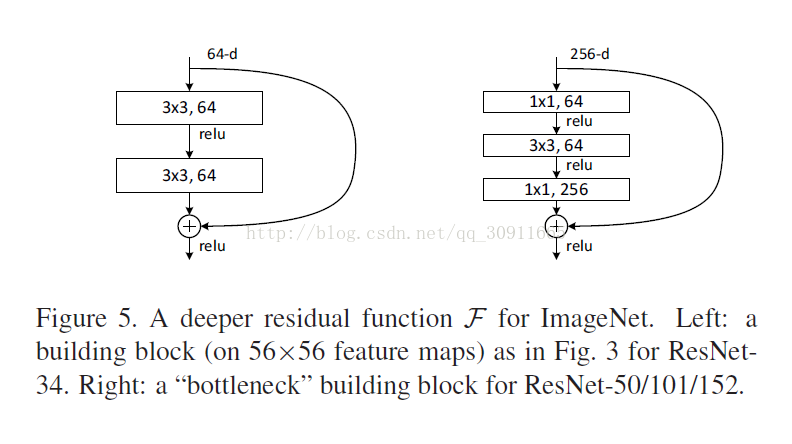
作者用这种结构构造了50层,101层和152层的ResNet,效果很棒。不过1202层的似乎效果不佳。
一些重要的参数设置:
weight decay : 0.0001
momentum : 0.9
使用了《Delving deep into rectifiers:Surpassing human-level performance on imagenet classification》中的weight initialization
使用了Batch Normalization 但是没用DropOut(为啥不用呢?不造)
还有一些别的细节分析我就不贴了

相关文章推荐
- [深度学习]Deep Residual Learning for Image Recognition(ResNet,残差网络)阅读笔记
- Deep Residual Learning for Image Recognition--ResNet论文阅读笔记
- 论文阅读学习 - ResNet - Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition(ResNet)论文笔记
- ResNet论文阅读---《Deep Residual Learning for Image Recognition》
- 经典文章系列: (ResNet) Deep Residual Learning for Image Recognition 论文阅读
- ResNet: Deep Residual Learning for Image Recognition 论文阅读
- 【文献阅读】ResNet-Deep Residual Learning for Image Recognition--CVPR--2016
- Deep Residual Learning for Image Recognition 阅读笔记
- Deep Residual Learning for Image Recognition笔记
- 论文笔记——Deep Residual Learning for Image Recognition(论文及相关代码)
- 深度学习论文随记(四)ResNet 残差网络-2015年Deep Residual Learning for Image Recognition
- 深度学习论文笔记 [图像处理] Deep Residual Learning for Image Recognition
- 论文笔记——Deep Residual Learning for Image Recognition
- 论文笔记: Deep Residual Learning for Image Recognition
- 论文笔记 | Deep Residual Learning for Image Recognition
- ResNet(Deep Residual Learning for Image Recognition)
- Deep Residual Learning for Image Recognition(阅读)
- ResNet--Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition(ResNet)残差网络解读