论文笔记——Deep Residual Learning for Image Recognition(论文及相关代码)
2017-12-27 11:50
501 查看
啊先说一些题外话,在刚刚进入深度学习的时候就在知乎上看到关于何恺明大神的phd的传奇经历。大概就是何大牛顶着光环选手的称号进的MSRA,peer的到第1-2年就已经各种论文刷到飞起,但是何大牛到第三年什么都没有,甚至准备拿了毕业证回高中母校当老师,然而就在最后一年大牛爆发的神来之笔也就是熟知的dark channel prior的cvpr paper,何大牛的第一篇论文就成为了亚洲第一篇cvpr best paper。
现在每每看到说在AI领域开挂一般的人都会提到何大牛,Dark Channel去雾、Faster R-CNN、ResNet、Mask R-CNN,各种conference的best paper,还是难得的到现在都自己亲力亲为的做research,也才会有井喷式的高质量的论文,革新式的思维和思路(所以说能成为省状元的人在思维模式上是一定有去我等常人不同之处的)。
还有一点儿废话就是,做CV或者往大了说学CS的人实在是需要有一个更加灵活创新的思维。感觉自己对于学习路线的规划实在是非常欠缺,没有条理和深度,不能专一到某一个方向,这对于做CV是相当不利的,毕竟现在AI的发展势头是朝令夕改,不能保持足够的热情和效率很快就会被甩得远远的。
(这篇论文早就该看了,接下来会继续更新何大牛的其他论文,先占个坑~)
勉励勉励。
论文地址:http://arxiv.org/abs/1512.03385
Abstract:
网络越深训练就越难,作者根据输入将层表示为学习残差函数。
ResNet优点在于:实验表明,残差网络更容易优化,并且能够通过增加相当的深度来提高准确率。
实验证明:
1、在ImageNet 测试集上使用了一个152层(VGG的8倍深度)的网络,尽管层数增加但是复杂度反而比VGG低,取得了3.57%的错误率。
2、网络的深度对很多视觉识别任务都非常重要,仅使用非常深的网络就能在COCO物体识别数据集上取得28%的提升效果。
Introduction:
深度的网络能够汇集低/中/高的特征,并且特征级别的丰富度也会随着网
4000
络层数的增加而增加。最近也证实网络的深度是非常重要的,导致ImageNet数据集挑战赛都是创造的越来越深的网络,一些难度高的识别任务也是由深层模型来得到解决。
这就引出了一个值得思考的问题:Is learning better networks as easy as stacking more layers?
为网络增添层是十分容易的,但是对于网络训练来说却存在着以下几个问题:
Problem:vanishing/exploding gradients(梯度弥散/爆炸问题)
Solution:初始正则化(normalized initialization)和中间层的正则化(intermediate normalization layers)
Result:可是使用SGD的BP算法训练几十层网络。
Problem:degradation(退化)
随着网络深度的增加准确度会趋于饱和,进而梯度消失。并且这个问题不是由过拟合(overfitting)导致(过拟合的话在训练集上应该准确率会更高)。在一个深度合适的模型中增加层反而会提高训练集的错误率,实验结果证实如下:
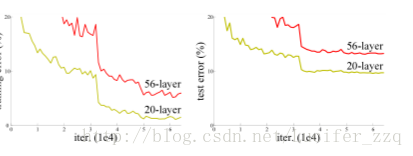
这个问题的出现说明了不是所有的系统都同样简单的可以被优化。
Solution:构造同等映射(identity mapping),实验证明一个浅层的网络和通过浅层网络等同映射构造的深层模型相比,生成模型并没有比浅层网络有更低的准确率。引入ResNet,将原始所需要学的函数H(x)转换成F(x)+x,假设F(x)的优化会比H(x)简单的多。只需要学习残差函数F(x)=H(x)-x,只要让F(x)=0,就构成了恒等映射(即:H(x)=x)。
这种残差学习的block由forward CNN和shortcut相结合来实现,如下图所示,优点在于:
1、不会产生额外的参数和增加训练计算度。
2、网络仍然可以通过端到端的反向传播的SGD优化方法来训练。
3、仅需要常见的库,而不需要修改优化方法。
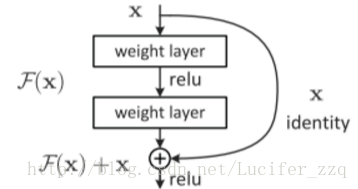
文章展示了ResNet解决的几个问题:
1、easy to optimize
2、easily enjoy accuracy gains from greatly increased depth
Result:ResNet在CIFAR-10数据集上取得了相似的结果,并获得了一系列大赛的第一名,证明ResNet是一个通用的方法,而不是针对于某一个数据集。
Related work:
1、Residual Representations:
用VLAD使用残差向量来对图像进行编码,Fisher Vector是VLAD一种版本,它们在图像检索和分类上都是一个很强大的浅层表示,并且优于原始编码。
在low-level的识别和图形计算上,为了解决偏分求导问题(PDEs)广泛的使用Multigrid方法,把系统看成是不同尺度上的子问题,每一个子问题都负责一个更粗糙或者更精细的残差分辨率。层次化的预处理可以用于替换Multigrid,层次化的预处理依赖于两种尺度的残差向量表示。实验表明,这些求解器比对残差不敏感的求解器收敛更快。这些理论都表明一个好的改善和预处理能够简化优化过程。
2、Shortcut Connections:
Shortcut connection已经被研究了很久,早期的对于多层感知层(MLPs)的训练只是在输入和输出之间添加线性连接,少量的中间层直接与auxiliary classificiers(?)相连接来处理梯度消失/爆炸的问题。
“highway network”用门函数(gating functions)表达shortcut connections,这些门函数依赖于数据(data-dependent并且具有参数,而此方法的恒等映射/捷径(identity shortcuts)是不具有参数的。并且当highway network”一个门的捷径路线关闭的时候,这一层相当于一个没有学习残差函数。本文的方法与“highway network”相对比,总是在学习残差函数、恒等映射(identity shortcuts)不会关闭、所有的信息都会使用到。此外,“highway networks”并不能通过增加层数来提高准确率。
Deep Residual Learning:
1、Residual Learing:
H(x):an underlying mapping to be fit by a few stacked layers (not necessarily the entire net)
X:denoting the inputs to the first of these layers
假设多个非线信层能够渐步近似于复杂的函数,同样的假设非线信层能够渐步近似于残差函数。传统的是期望能够通过网络中的一部分几层来拟合映射函数H(x),ResNet的思想在于让这几层拟合残差函数F(x)=H(x)-x,而用shortcut传递x,在output输出进行累加后得到恒等映射。尽管这两种形式都应该能够逐步的逼近想要得到的期望函数,但是学习得到这个函数的难易度并不一样。
想解决这个问题是由于出现的有关于退化这个有悖于常理的现象的出现,如果添加层能够被构建成为恒等映射的结构,那么理论上网络越深错误率应该不会更大(然而这与实际情况相悖)。退化问题的出现可能说明了用多个非线性层来拟合映射函数的优化方法存在一定的困难。在ResNet的结构下,如果恒等映射达到最佳,那么优化方法能够让多层非线性层的权值矩阵从零到接近于恒等映射。
在实际情况下,恒等映射不太可能达到最佳状态,但重组后的网络结构能够预先处理这里问题。如果期望函数比起零映射更接近于恒等映射,优化方法比起学习一个全新的函数,更易在找出一个与恒等映射函数有关的扰动映射。(在图7表示了学习得的残差函数通常只具有很小的响应,表示恒等映射能够提供合理的预处理)
2、Identity Mapping by Shortcuts:
根据ResNet的block结构得到输入(x)输出(y)间公式:

即输出=残差映射+输入
其中残差映射具体为:
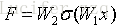
其中σ表示激活函数ReLU,W是两层layer的权值矩阵
需要注意的是:
残差映射与输入相加时,如果维度相同直接逐元素相加,否则需要给x执行一个线性映射Ws来匹配维度:
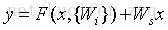
用于实现残差函数F的网络block结构需要至少有2-3层,如果只有一层则类似于线性结构(即),无法体现ResNet的优势所在。
上述公式为了简化是使用的全连接层,但实际上使用卷积层也是可行的。F可以表示多卷积层的卷积过程,与输入的加法则变为channel之间对应的两个feature-map的对应元素点相加。
3、Network Architectures:
Plain Network:
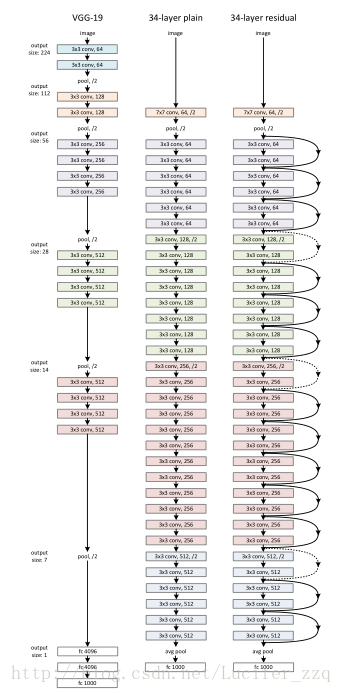
由VGG设计成的一个34层的网络,卷积核的大小基本上都为3*3的大小,设计规则如下:
对于相同大小的feature map的输出层,它们具有相同数量的卷积核(filter/channel)
当feature map大小减半(例如经过pooling层),卷积核的大小需要加倍(维持每一层的复杂度相当)
步长为2,网络以average pppling层作为(卷积层)结束,最后输出为一个1000个结点的全连接层+softmax,总共带权值的层数为34,具体结构如下图中间网络。
Residual Network:
在plain network的基础上加上shorcuts,当输入输出的维度(即feature map的大小)相同的情况下,identity shortcut连接可以直接使用(网络结构中的实线shortcut),当维度增加时(网络结构中的虚线shortcut),考虑以下两种选择:
仍然用shortcut表示恒等映射,对前面size更小的的层添加zero-padding来匹配,这样还不会增加额外的参数。
使用1*1的卷积核Ws与x相卷积,通过卷积核的数目来达到匹配,但这样会增加额外的参数。
两种选择下shorcut都能够在两种不同size的层中通过,步长设置为2,具体结构如下图右侧网络。
4、Implementation
图片预处理:
图片大小由它本身最短的边随机从[256,480]中选择数字来进行resize,作为sacle
augmentation(即为了扩充数据集)。对图片或者它的水平翻转进行224*224大小的裁剪并且减去图片的像素均值(图片训练的预处理方式),使用标准颜色增强(standard
color augmentation)。
训练细节:
每一个卷积层在经过激活层之前都对其进行BN(batch normalization)。 初始化权值,plain/residual
network从头开始对每一层训练。 Solver使用SGD(设置mini-batch为256)。
学习率初始值为0.1,error趋于稳定则除10,总共迭代次数为600000。 权值衰减系数(weight
decay)为0.0001,动量(momentum)为0.9。 本实验不使用dropout。
测试细节:
采用标准的10-crop测试,并且使用multiple scales的均值作为测试结果。
Key point:multi-scale、crop、mean subtract、standard color augmentation、BN、SGD、standard 10-crop testing
Experiments
1、ImageNet Classification
使用ImageNet千分类数据集,模型训练图片为1.28*106张,验证图片5*104张,测试集图片为1*105张,评估top-1、top-5的错误率。
Plain Network:
评估18和34层的plain network来展示网络的退化问题。两种网络都加入了BN但是仍然出现了退化现象,说明了退化问题不是由梯度弥散引起的。(另外也不能简单地增加迭代次数来使其收敛,增加迭代次数仍然会出现退化问题。)
Residual Networks:
Residual Networks评估18 和34层的ResNets:
(i)34层的ResNet比18层的ResNet的top-1的错误率小(2.8%),说明退化现象在ResNet的结构下被处理得更好,可以通过增加网络的深度来获得更高的准确率。
(ii)与plain networks相比,34层的ResNet比plain的top-1的错误率小(3.5%),说明了残差学习在深度网络系统中是十分有效的。
(iii)同等深度ResNet比起plain network收敛更快,网络更易被优化。
恒等 VS 映射 Shortcut:
在上面的实验中已经验证了恒等shortcut对训练是有所帮助的,接下来研究映射shortcut,比较三种选项:
(A)增加的维度使用0填充,shortcuts无参数
(B)增加的维度使用映射shortcut,其他使用恒等shortcut
(C)所有的shortcut都是映射

表3表明了这三种选择都比plain network结构好,总结如下:
(i)效果C>B>A,即zero-padding没有进行残差学习,引入的参数越多效果越好。
(ii)ABC的效果差距细微,说明映射shortcut并不是必需的,为了减少模型的复杂度和尺寸而不选择使用模型C。恒等shortcut则不会引入额外的复杂度因此下面接着介绍的深度瓶颈结构更为重要。
Deeper Bottleneck Architectures:
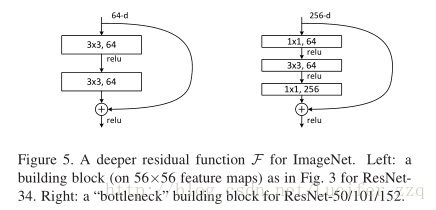
上图表示对于每一个残差函数F使用三层结构代替之前的两层,kernel大小为1*1、3*3、1*1,(1*1用于减少再恢复/增加维度,3*3用于减少维度),这两种的结构复杂程度相似。无参数的恒等shortcut对于瓶颈结构十分重要,映射shortcut的时间复杂度和模型尺寸会增加一倍(因为shortcut连接了两个高维端)。使用更深的瓶颈结构代替原本ResNet的残差学习结构,同时也可以增加结构的数量,网络深度得以增加。生成了ResNet-50,ResNet-101,ResNet-152. 随着深度增加,没有出现退化问题,性能不断提升。
2、CIFAR-10 and Analysis
作者创建了一个1202层的网络,与110浅层网络的训练误差相当,但测试误差却大1.5%,认为是出现了过拟合。
在CIFAR-10数据上是应用了强大的正则化方法(maxout或者dropout)才获得了最好的结果,本实验加上正则化方法或许能提高实验结果。
3、Object Detection on PASCAL and MS COCO
大概就是各种获奖各种优秀各种碾压。
相关代码:
Github地址:https://github.com/KaimingHe/deep-residual-networks
此地址下包含ResNet的Caffe代码,关于网络的具体在定义在prototxt中可直接使用。
现在每每看到说在AI领域开挂一般的人都会提到何大牛,Dark Channel去雾、Faster R-CNN、ResNet、Mask R-CNN,各种conference的best paper,还是难得的到现在都自己亲力亲为的做research,也才会有井喷式的高质量的论文,革新式的思维和思路(所以说能成为省状元的人在思维模式上是一定有去我等常人不同之处的)。
还有一点儿废话就是,做CV或者往大了说学CS的人实在是需要有一个更加灵活创新的思维。感觉自己对于学习路线的规划实在是非常欠缺,没有条理和深度,不能专一到某一个方向,这对于做CV是相当不利的,毕竟现在AI的发展势头是朝令夕改,不能保持足够的热情和效率很快就会被甩得远远的。
(这篇论文早就该看了,接下来会继续更新何大牛的其他论文,先占个坑~)
勉励勉励。
论文地址:http://arxiv.org/abs/1512.03385
Abstract:
网络越深训练就越难,作者根据输入将层表示为学习残差函数。
ResNet优点在于:实验表明,残差网络更容易优化,并且能够通过增加相当的深度来提高准确率。
实验证明:
1、在ImageNet 测试集上使用了一个152层(VGG的8倍深度)的网络,尽管层数增加但是复杂度反而比VGG低,取得了3.57%的错误率。
2、网络的深度对很多视觉识别任务都非常重要,仅使用非常深的网络就能在COCO物体识别数据集上取得28%的提升效果。
Introduction:
深度的网络能够汇集低/中/高的特征,并且特征级别的丰富度也会随着网
4000
络层数的增加而增加。最近也证实网络的深度是非常重要的,导致ImageNet数据集挑战赛都是创造的越来越深的网络,一些难度高的识别任务也是由深层模型来得到解决。
这就引出了一个值得思考的问题:Is learning better networks as easy as stacking more layers?
为网络增添层是十分容易的,但是对于网络训练来说却存在着以下几个问题:
Problem:vanishing/exploding gradients(梯度弥散/爆炸问题)
Solution:初始正则化(normalized initialization)和中间层的正则化(intermediate normalization layers)
Result:可是使用SGD的BP算法训练几十层网络。
Problem:degradation(退化)
随着网络深度的增加准确度会趋于饱和,进而梯度消失。并且这个问题不是由过拟合(overfitting)导致(过拟合的话在训练集上应该准确率会更高)。在一个深度合适的模型中增加层反而会提高训练集的错误率,实验结果证实如下:
这个问题的出现说明了不是所有的系统都同样简单的可以被优化。
Solution:构造同等映射(identity mapping),实验证明一个浅层的网络和通过浅层网络等同映射构造的深层模型相比,生成模型并没有比浅层网络有更低的准确率。引入ResNet,将原始所需要学的函数H(x)转换成F(x)+x,假设F(x)的优化会比H(x)简单的多。只需要学习残差函数F(x)=H(x)-x,只要让F(x)=0,就构成了恒等映射(即:H(x)=x)。
这种残差学习的block由forward CNN和shortcut相结合来实现,如下图所示,优点在于:
1、不会产生额外的参数和增加训练计算度。
2、网络仍然可以通过端到端的反向传播的SGD优化方法来训练。
3、仅需要常见的库,而不需要修改优化方法。
文章展示了ResNet解决的几个问题:
1、easy to optimize
2、easily enjoy accuracy gains from greatly increased depth
Result:ResNet在CIFAR-10数据集上取得了相似的结果,并获得了一系列大赛的第一名,证明ResNet是一个通用的方法,而不是针对于某一个数据集。
Related work:
1、Residual Representations:
用VLAD使用残差向量来对图像进行编码,Fisher Vector是VLAD一种版本,它们在图像检索和分类上都是一个很强大的浅层表示,并且优于原始编码。
在low-level的识别和图形计算上,为了解决偏分求导问题(PDEs)广泛的使用Multigrid方法,把系统看成是不同尺度上的子问题,每一个子问题都负责一个更粗糙或者更精细的残差分辨率。层次化的预处理可以用于替换Multigrid,层次化的预处理依赖于两种尺度的残差向量表示。实验表明,这些求解器比对残差不敏感的求解器收敛更快。这些理论都表明一个好的改善和预处理能够简化优化过程。
2、Shortcut Connections:
Shortcut connection已经被研究了很久,早期的对于多层感知层(MLPs)的训练只是在输入和输出之间添加线性连接,少量的中间层直接与auxiliary classificiers(?)相连接来处理梯度消失/爆炸的问题。
“highway network”用门函数(gating functions)表达shortcut connections,这些门函数依赖于数据(data-dependent并且具有参数,而此方法的恒等映射/捷径(identity shortcuts)是不具有参数的。并且当highway network”一个门的捷径路线关闭的时候,这一层相当于一个没有学习残差函数。本文的方法与“highway network”相对比,总是在学习残差函数、恒等映射(identity shortcuts)不会关闭、所有的信息都会使用到。此外,“highway networks”并不能通过增加层数来提高准确率。
Deep Residual Learning:
1、Residual Learing:
H(x):an underlying mapping to be fit by a few stacked layers (not necessarily the entire net)
X:denoting the inputs to the first of these layers
假设多个非线信层能够渐步近似于复杂的函数,同样的假设非线信层能够渐步近似于残差函数。传统的是期望能够通过网络中的一部分几层来拟合映射函数H(x),ResNet的思想在于让这几层拟合残差函数F(x)=H(x)-x,而用shortcut传递x,在output输出进行累加后得到恒等映射。尽管这两种形式都应该能够逐步的逼近想要得到的期望函数,但是学习得到这个函数的难易度并不一样。
想解决这个问题是由于出现的有关于退化这个有悖于常理的现象的出现,如果添加层能够被构建成为恒等映射的结构,那么理论上网络越深错误率应该不会更大(然而这与实际情况相悖)。退化问题的出现可能说明了用多个非线性层来拟合映射函数的优化方法存在一定的困难。在ResNet的结构下,如果恒等映射达到最佳,那么优化方法能够让多层非线性层的权值矩阵从零到接近于恒等映射。
在实际情况下,恒等映射不太可能达到最佳状态,但重组后的网络结构能够预先处理这里问题。如果期望函数比起零映射更接近于恒等映射,优化方法比起学习一个全新的函数,更易在找出一个与恒等映射函数有关的扰动映射。(在图7表示了学习得的残差函数通常只具有很小的响应,表示恒等映射能够提供合理的预处理)
2、Identity Mapping by Shortcuts:
根据ResNet的block结构得到输入(x)输出(y)间公式:
即输出=残差映射+输入
其中残差映射具体为:
其中σ表示激活函数ReLU,W是两层layer的权值矩阵
需要注意的是:
残差映射与输入相加时,如果维度相同直接逐元素相加,否则需要给x执行一个线性映射Ws来匹配维度:
用于实现残差函数F的网络block结构需要至少有2-3层,如果只有一层则类似于线性结构(即),无法体现ResNet的优势所在。
上述公式为了简化是使用的全连接层,但实际上使用卷积层也是可行的。F可以表示多卷积层的卷积过程,与输入的加法则变为channel之间对应的两个feature-map的对应元素点相加。
3、Network Architectures:
Plain Network:
由VGG设计成的一个34层的网络,卷积核的大小基本上都为3*3的大小,设计规则如下:
对于相同大小的feature map的输出层,它们具有相同数量的卷积核(filter/channel)
当feature map大小减半(例如经过pooling层),卷积核的大小需要加倍(维持每一层的复杂度相当)
步长为2,网络以average pppling层作为(卷积层)结束,最后输出为一个1000个结点的全连接层+softmax,总共带权值的层数为34,具体结构如下图中间网络。
Residual Network:
在plain network的基础上加上shorcuts,当输入输出的维度(即feature map的大小)相同的情况下,identity shortcut连接可以直接使用(网络结构中的实线shortcut),当维度增加时(网络结构中的虚线shortcut),考虑以下两种选择:
仍然用shortcut表示恒等映射,对前面size更小的的层添加zero-padding来匹配,这样还不会增加额外的参数。
使用1*1的卷积核Ws与x相卷积,通过卷积核的数目来达到匹配,但这样会增加额外的参数。
两种选择下shorcut都能够在两种不同size的层中通过,步长设置为2,具体结构如下图右侧网络。
4、Implementation
图片预处理:
图片大小由它本身最短的边随机从[256,480]中选择数字来进行resize,作为sacle
augmentation(即为了扩充数据集)。对图片或者它的水平翻转进行224*224大小的裁剪并且减去图片的像素均值(图片训练的预处理方式),使用标准颜色增强(standard
color augmentation)。
训练细节:
每一个卷积层在经过激活层之前都对其进行BN(batch normalization)。 初始化权值,plain/residual
network从头开始对每一层训练。 Solver使用SGD(设置mini-batch为256)。
学习率初始值为0.1,error趋于稳定则除10,总共迭代次数为600000。 权值衰减系数(weight
decay)为0.0001,动量(momentum)为0.9。 本实验不使用dropout。
测试细节:
采用标准的10-crop测试,并且使用multiple scales的均值作为测试结果。
Key point:multi-scale、crop、mean subtract、standard color augmentation、BN、SGD、standard 10-crop testing
Experiments
1、ImageNet Classification
使用ImageNet千分类数据集,模型训练图片为1.28*106张,验证图片5*104张,测试集图片为1*105张,评估top-1、top-5的错误率。
Plain Network:
评估18和34层的plain network来展示网络的退化问题。两种网络都加入了BN但是仍然出现了退化现象,说明了退化问题不是由梯度弥散引起的。(另外也不能简单地增加迭代次数来使其收敛,增加迭代次数仍然会出现退化问题。)
Residual Networks:
Residual Networks评估18 和34层的ResNets:
(i)34层的ResNet比18层的ResNet的top-1的错误率小(2.8%),说明退化现象在ResNet的结构下被处理得更好,可以通过增加网络的深度来获得更高的准确率。
(ii)与plain networks相比,34层的ResNet比plain的top-1的错误率小(3.5%),说明了残差学习在深度网络系统中是十分有效的。
(iii)同等深度ResNet比起plain network收敛更快,网络更易被优化。
恒等 VS 映射 Shortcut:
在上面的实验中已经验证了恒等shortcut对训练是有所帮助的,接下来研究映射shortcut,比较三种选项:
(A)增加的维度使用0填充,shortcuts无参数
(B)增加的维度使用映射shortcut,其他使用恒等shortcut
(C)所有的shortcut都是映射
表3表明了这三种选择都比plain network结构好,总结如下:
(i)效果C>B>A,即zero-padding没有进行残差学习,引入的参数越多效果越好。
(ii)ABC的效果差距细微,说明映射shortcut并不是必需的,为了减少模型的复杂度和尺寸而不选择使用模型C。恒等shortcut则不会引入额外的复杂度因此下面接着介绍的深度瓶颈结构更为重要。
Deeper Bottleneck Architectures:
上图表示对于每一个残差函数F使用三层结构代替之前的两层,kernel大小为1*1、3*3、1*1,(1*1用于减少再恢复/增加维度,3*3用于减少维度),这两种的结构复杂程度相似。无参数的恒等shortcut对于瓶颈结构十分重要,映射shortcut的时间复杂度和模型尺寸会增加一倍(因为shortcut连接了两个高维端)。使用更深的瓶颈结构代替原本ResNet的残差学习结构,同时也可以增加结构的数量,网络深度得以增加。生成了ResNet-50,ResNet-101,ResNet-152. 随着深度增加,没有出现退化问题,性能不断提升。
2、CIFAR-10 and Analysis
作者创建了一个1202层的网络,与110浅层网络的训练误差相当,但测试误差却大1.5%,认为是出现了过拟合。
在CIFAR-10数据上是应用了强大的正则化方法(maxout或者dropout)才获得了最好的结果,本实验加上正则化方法或许能提高实验结果。
3、Object Detection on PASCAL and MS COCO
大概就是各种获奖各种优秀各种碾压。
相关代码:
Github地址:https://github.com/KaimingHe/deep-residual-networks
此地址下包含ResNet的Caffe代码,关于网络的具体在定义在prototxt中可直接使用。

相关文章推荐
- 论文笔记: Deep Residual Learning for Image Recognition
- 论文笔记 | Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition(ResNet)论文笔记
- 论文笔记:Deep Residual Learning for Image Recognition
- 深度学习论文笔记 [图像处理] Deep Residual Learning for Image Recognition
- 论文笔记——Deep Residual Learning for Image Recognition
- [深度学习论文笔记][Image Classification] Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition--ResNet论文阅读笔记
- 深度学习论文随记(四)ResNet 残差网络-2015年Deep Residual Learning for Image Recognition
- 【深度学习】论文导读:图像识别中的深度残差网络(Deep Residual Learning for Image Recognition)
- ResNet 《Deep Residual Learning for Image Recognition》 阅读笔记
- 【那些年我们一起看过的论文】之《Deep Residual Learning for Image Recognition》
- [深度学习]Deep Residual Learning for Image Recognition(ResNet,残差网络)阅读笔记
- ResNet: Deep Residual Learning for Image Recognition 论文阅读
- 经典文章系列: (ResNet) Deep Residual Learning for Image Recognition 论文阅读
- ResNet论文阅读---《Deep Residual Learning for Image Recognition》
- 论文阅读学习 - ResNet - Deep Residual Learning for Image Recognition
- Deep Residual Learning for Image Recognition 笔记
- Deep Residual Learning for Image Recognition 笔记
- Deep Residual Learning for Image Recognition笔记