spark学习笔记:spark独立集群模式配置及FIFO调度
2017-08-22 17:13
357 查看
将spark文件夹分发给三台slave从机:
在spark的conf目录下修改slaves文件,把从机的hostname加进去:
同样新建shell脚本来分发配置文件:
内容写入:
启动从节点有两种方式:
1.分别进入从机执行start-slave.sh启动从节点。注意启动从节点的命令需要带主节点的URL:
2.在主节点上执行start-slaves.sh, 主节点会自动登录到从节点启动进程。
主节点提供了WEB页面管理,默认地址为:http://master:8080/
进入集群模式下的spark-shell:
在master的web页面上可以看到正在运行的shell程序:

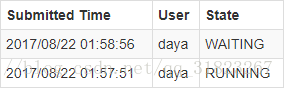
spark-shell是可以同时在多个节点上运行的,但是需要注意的是,后启动的spark-shell是获取不到资源的。举个例子,先在slave3上启动spark-shell,后在slave2上启动spark-shell,web页面中会有如下显示:
在slave2上执行如下命令:
此时它会被阻塞,而在slave 3上执行这两句命令会得到正确的输出:
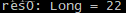
在slave3上推出spark-shell:
可以看到slave2此时也能得到正确的输出。
scp -r /usr/DevProgram/spark-2.2.0-bin-hadoop2.7 daya@slave1:/usr/DevProgram/; scp -r /usr/DevProgram/spark-2.2.0-bin-hadoop2.7 daya@slave2:/usr/DevProgram/; scp -r /usr/DevProgram/spark-2.2.0-bin-hadoop2.7 daya@slave3:/usr/DevProgram
在spark的conf目录下修改slaves文件,把从机的hostname加进去:
同样新建shell脚本来分发配置文件:
touch distribute_spark_conf.sh; chmod a+x distribute_spark_conf.sh; nano distribute_spark_conf.sh
内容写入:
#!/bin/bash
for((i=1;i<=3;i++))
{
scp -r $SPARK_HOME/conf daya@slave$i:$SPARK_HOME/
}启动集群
进入spark下的sbin目录,执行start-master.sh启动主节点。启动从节点有两种方式:
1.分别进入从机执行start-slave.sh启动从节点。注意启动从节点的命令需要带主节点的URL:
./start-slave.sh spark://master:7077
2.在主节点上执行start-slaves.sh, 主节点会自动登录到从节点启动进程。
主节点提供了WEB页面管理,默认地址为:http://master:8080/
进入集群模式下的spark-shell:
spark-shell --master spark://master:7077
在master的web页面上可以看到正在运行的shell程序:
spark-shell是可以同时在多个节点上运行的,但是需要注意的是,后启动的spark-shell是获取不到资源的。举个例子,先在slave3上启动spark-shell,后在slave2上启动spark-shell,web页面中会有如下显示:
在slave2上执行如下命令:
val file=sc.textFile("/home/daya/zookeeper.out");
file.count此时它会被阻塞,而在slave 3上执行这两句命令会得到正确的输出:
在slave3上推出spark-shell:
:quit
可以看到slave2此时也能得到正确的输出。

相关文章推荐
- 蜗龙徒行-Spark学习笔记【五】IDEA中集群运行模式的配置
- Spark学习笔记(30)集群运行模式下的Spark Streaming调试
- spark学习笔记:集群模式下的addFile()操作(存疑)
- Spark1.5.1学习笔记(一)Standalone集群配置
- spark1.6.1学习笔记02-spark集群的作业调度
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- 学习笔记(4)——实验室集群管理结点IP配置
- 学习笔记(2)——实验室集群LVS配置
- 马哥学习笔记二十——集群系列之LVS调度方法及NAT模型
- HBase入门笔记(三)-- 完全分布模式Hadoop集群安装配置
- hadoop学习笔记(2) 伪分布模式配置
- MongoDB 学习笔记(三) MongoDB (replica set) 集群配置
- Spark教程-构建Spark集群-配置Hadoop单机模式并运行Wordcount(2)
- Quartz.NET 2.0 学习笔记(3) :通过配置文件实现任务调度
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop单机模式并运行Wordcount(1)
- 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群-配置Hadoop伪分布模式并运行Wordcount示例(1)
- hadoop学习笔记之-生产环境Hadoop大集群配置安装
- 学习笔记(1)——实验室集群配置
- spark的独立模式集群部署
- hadoop学习笔记之-生产环境Hadoop大集群配置安装