spark的独立模式集群部署
2014-07-08 20:09
471 查看
spark有三种集群部署方式:
1、独立部署模式standalone,spark自身有一套完整的资源管理方式
2、架构于hadoop之上的spark集群
3、架构于mesos之上的spark集群
尝试了下搭建第一种独立部署模式集群,将安装方式记录如下:
环境ubuntu 12.04 (两台),部署方式是和hadoop类似,先在一台机器上部署成功后直接将文件打包拷贝到其他机器上,这里假设现在A机器上部署,并且A为master,最后B为slave机器
A和B均上创建用户spark
保证A能无密码登陆到B上的spark用户,在ssh里面设置
这部分是如无特别说明均在master机器(A)上配置
0 首先保证A能无密码方式ssh至 localhost和B,具体方式参见:点击打开链接
0.0 这里假设机器A的IP是192.168.1.131,机器B的IP地址是192.168.1.139,且机器A的hostname就是A,机器B的hostname是B
在A上执行gedit /etc/hosts后,末尾添加192.168.1.139 B
在B上执行gedit /etc/hosts后,末尾添加192.168.1.131 A
这样可以使得A和B机器可以用过彼此的hostname访问,而不是一长串IP
0.1 (机器A上:)在A机器上执行
那么A可以实现无密码登陆localhost
0.2 (机器B上:)在B机器上执行
695 ? 00:00:00 sshd
1754 ? 00:00:00 ssh-agent
若没有sshd那么在B上执行
0.3 (机器B上:)在B上执行:
第二句是将A的公钥拷贝到B上,从而实现A无密码访问B
0.4(机器A上:)执行gedit ~/.ssh/config添加
这里是为了A以默认用户spark无密码登陆B,其实这一步没有必要,因为A和B机器上都是在spark用户下操作的,那么机器A的saprk执行ssh B也是以spark用户登陆的
(机器A上:) 在A上执行ssh B可以无密码登陆至spark@B则成功
1 (机器A、B上:)每台机器确保有java,一个简单的方式:
2 (机器A上:)需要maven编译spark源码,下载maven点击打开链接,随便下载一个版本
简单的方式:
复杂的方式:
3 (机器A上:)下载spark,点击打开链接,注意不要下载带有hadoop之类字样的版本,而是source package比如spark-1.0.0.tgz
4 (机器A上:)配置spark
4.1 gedit ./conf/spark-env.sh在spark-env.sh末尾添加如下:
SPARK_WORKER_INSTANCES表示slave机器的数目,这里只有B一台故设为1
4.2 gedit ./conf/slaves添加B的hostname,这里B机器的hostname假设就为B故在文件中追加一个B即可。文件里原来有一个localhost如果你想要master同时也为worker机器那么可保留该行,否则可以删除
5 (机器A上:)验证master机器A能否单机启动spark
(机器A上:)关闭master:
集群部署:
至此spark的master部署完成,此时还是单机版的,接下来部署集群
1 (机器A上:)在master机器A上打包刚才成功启动的spark文件,然后拷贝至slave机器B上
2 (机器B上:)在slave机器上解压从master机器上拷贝spark.tgz
集群启动:
1 (机器A上:)在master机器上执行start-all.sh
2 通过jps命令查看集群启动情况,master机器上jps查看的master进程,slave机器上jps查看所有的worker进程
(机器A上:)spark-shell启动时就启动集群,在conf/spark-env.sh下添加
主要参考:
点击打开链接http://mbonaci.github.io/mbo-spark/
点击打开链接http://database.51cto.com/art/201404/435674.htm
点击打开链接http://www.oschina.net/translate/spark-standalone?cmp
1、独立部署模式standalone,spark自身有一套完整的资源管理方式
2、架构于hadoop之上的spark集群
3、架构于mesos之上的spark集群
尝试了下搭建第一种独立部署模式集群,将安装方式记录如下:
环境ubuntu 12.04 (两台),部署方式是和hadoop类似,先在一台机器上部署成功后直接将文件打包拷贝到其他机器上,这里假设现在A机器上部署,并且A为master,最后B为slave机器
A和B均上创建用户spark
sudo useradd spark以后spark的目录在集群所有机器的/home/spark/spark下(第一个spark是用户名,第二个spark是spark文件目录名)
保证A能无密码登陆到B上的spark用户,在ssh里面设置
这部分是如无特别说明均在master机器(A)上配置
0 首先保证A能无密码方式ssh至 localhost和B,具体方式参见:点击打开链接
0.0 这里假设机器A的IP是192.168.1.131,机器B的IP地址是192.168.1.139,且机器A的hostname就是A,机器B的hostname是B
在A上执行gedit /etc/hosts后,末尾添加192.168.1.139 B
在B上执行gedit /etc/hosts后,末尾添加192.168.1.131 A
这样可以使得A和B机器可以用过彼此的hostname访问,而不是一长串IP
0.1 (机器A上:)在A机器上执行
ssh-keygen -t rsa cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys ssh localhost
那么A可以实现无密码登陆localhost
0.2 (机器B上:)在B机器上执行
ps -e|grep ssh如果出现:
695 ? 00:00:00 sshd
1754 ? 00:00:00 ssh-agent
若没有sshd那么在B上执行
sudo apt-get install openssh-server在B上安装ssh服务端(ubuntu有可能默认只有agent端)
0.3 (机器B上:)在B上执行:
ssh-keygen -t rsa scp spark@A:~/.ssh/authorized_keys ~/.ssh第一句是为了保证在B上有.ssh目录
第二句是将A的公钥拷贝到B上,从而实现A无密码访问B
0.4(机器A上:)执行gedit ~/.ssh/config添加
user spark
这里是为了A以默认用户spark无密码登陆B,其实这一步没有必要,因为A和B机器上都是在spark用户下操作的,那么机器A的saprk执行ssh B也是以spark用户登陆的
(机器A上:) 在A上执行ssh B可以无密码登陆至spark@B则成功
1 (机器A、B上:)每台机器确保有java,一个简单的方式:
sudo apt-get install eclipse
2 (机器A上:)需要maven编译spark源码,下载maven点击打开链接,随便下载一个版本
简单的方式:
sudo apt-get install maven
复杂的方式:
wget http://mirrors.cnnic.cn/apache/maven/maven-3/3.2.2/binaries/apache-maven-3.2.2-bin.tar.gz tar -zxvf apache-maven-3.2.2-bin.tar.gz mv apache-maven-3.2.2-bin.tar.gz maven sudo mv maven /usr/local然后gedit /etc/profile末尾添加如下:
#set maven environment M2_HOME=/usr/local/maven export MAVEN_OPTS="-Xms256m -Xmx512m" export PATH=$M2_HOME/bin:$PATH(机器A上:)验证maven安装成功:
source /etc/profile mvn -v出现类似语句:Apache Maven 3.2.2 (45f7c06d68e745d05611f7fd14efb6594181933e; 2014-06-17T21:51:42+08:00)
3 (机器A上:)下载spark,点击打开链接,注意不要下载带有hadoop之类字样的版本,而是source package比如spark-1.0.0.tgz
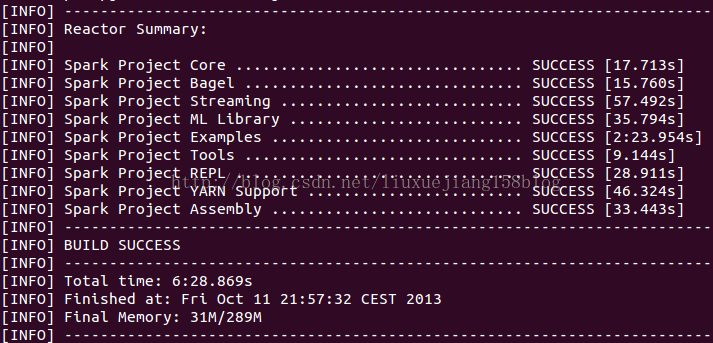
tar -zxvf spark-1.0.0.tgz mv spark-1.0.0 spark cd spark sh make-distribution.sh(机器A上:)最后一步会编译spark源码,过程可能有点长,取决于网络和机器配置,我的用了19min,编译成功类似如下图(图来自网上):
4 (机器A上:)配置spark
4.1 gedit ./conf/spark-env.sh在spark-env.sh末尾添加如下:
export SPARK_MASTER_IP=A
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT} 注意这里的SPARK_MASTER_IP我觉得还是设置为master机器的IP地址比较好,这里我假设master的hostname是ASPARK_WORKER_INSTANCES表示slave机器的数目,这里只有B一台故设为1
4.2 gedit ./conf/slaves添加B的hostname,这里B机器的hostname假设就为B故在文件中追加一个B即可。文件里原来有一个localhost如果你想要master同时也为worker机器那么可保留该行,否则可以删除
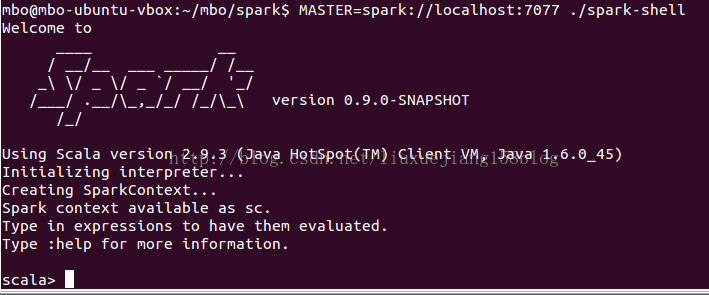
5 (机器A上:)验证master机器A能否单机启动spark
./sbin/start-master.sh启动成功类似如下图(图来自网上):
(机器A上:)关闭master:
./sbin/stop-master.sh
集群部署:
至此spark的master部署完成,此时还是单机版的,接下来部署集群
1 (机器A上:)在master机器A上打包刚才成功启动的spark文件,然后拷贝至slave机器B上
tar -zcvf spark.tgz spark scp spark.tgz spark@B:/home/spark/#注意scp后面的spark@B那一块内容改为你自己在slave机器上的目标位置
2 (机器B上:)在slave机器上解压从master机器上拷贝spark.tgz
tar -zxvf spark.tgz
集群启动:
1 (机器A上:)在master机器上执行start-all.sh
./sbin/start-all.sh
2 通过jps命令查看集群启动情况,master机器上jps查看的master进程,slave机器上jps查看所有的worker进程
(机器A上:)spark-shell启动时就启动集群,在conf/spark-env.sh下添加
export SPARK_MASTER_IP=192.168.1.171
export SPARK_MASTER_PORT=7077
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT} 这里这里将192.168.1.171替换master机器的IP地址主要参考:
点击打开链接http://mbonaci.github.io/mbo-spark/
点击打开链接http://database.51cto.com/art/201404/435674.htm
点击打开链接http://www.oschina.net/translate/spark-standalone?cmp

相关文章推荐
- Spark独立部署模式
- Spark 独立部署模式
- 安装部署Spark 1.x Standalone模式集群
- Maven安装编译Spark,搭建Spark独立集群模式(Hadoop架构之上)
- Spark 独立部署模式
- spark学习笔记:spark独立集群模式配置及FIFO调度
- Spark集群三种部署模式的区别
- Spark2.1.0 + CarbonData1.0.0+hadoop2.7.2集群模式部署及使用入门
- Spark中文手册10:spark部署:提交应用程序及独立部署模式
- Spark Tachyon编译部署(含单机和集群模式安装)
- Spark中文手册10:spark部署:提交应用程序及独立部署模式
- Spark集群三种部署模式的区别
- Spark中文手册10:spark部署:提交应用程序及独立部署模式
- Spark官方文档——独立集群模式(Standalone Mode)
- Launching Applications with spark-submit【使用脚本提交作业到集群5种部署模式--】
- Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门
- Spark集群三种部署模式的区别
- Spark单机模式独立部署
- spark集群部署模式概览
- Spark集群三种部署模式的区别