【深度学习】笔记10:Ubuntu16.04环境下配置caffe的步骤(无GPU版本)
2017-07-30 20:30
856 查看
/********************************************************************************************** *文件说明: * Ubuntu14.04+caffe+python接口的配置+无GPU *时间地点: * 陕西师范大学----2016.10.25 **********************************************************************************************/ 1. 安装【build-essentials】 1---安装开发所需要的一些基本的包, 2---sudo apt-get install build-essential 1---如果上面的命令运行不了的话,那么请执行下面的命令,更新本地的数据库: 2---sudo apt-get update 2--安装[git] sudo apt-get install git 3--安装[vim] sudo apt-get install vim 4. 安装【BLAS】(Basic Linear Algebar Subprograms)(基本线性代数子程序) 1---卷积神经网络中用到的数学计算主要是:矩阵,向量的计算,Caffe中调用了BLAS中相应的方法. 2---最常用的BLAS实现方法有:ATLAS,MKL,OpenBLAS等,Caffe可以选择其中的任何一种 3---本文选择安装ATLAS,然后你要将caffe根目录下的Makefile.config中的配置改为相应的atlas 4---sudo apt-get install libatlas-base-dev 5---对应的Makefile.confi配置如下所示: # BLAS choice: # atlas for ATLAS (default) # mkl for MKL # open for OpenBlas BLAS := atlas 4. 安装【OpenCV】 1---OPenCv,我想就不用我多介绍了,学计算机视觉的同学都应该知道,世界上最流行的计算机视觉库,包含大量的 图像处理函数.Caffe使用OpenCv中的函数完成一些图像存取和预处理功能 2---先下载Github的安装版本(https://github.com/jayrambhia/Install-OpenCV),下载之后由于是zip格式的 文件,需要使用shell的解压命令unzip,解压的格式如下所示: unzip -d UNZIP_PATH FILENAME.zip 1---unzip----shell的解压指令 2----d UNZIP_PATH---解压到指定的目录下,UNZIP_PATH就是你解压的路径名(绝对路径名) 3---FILENAME.zip----者当然就是你将要解压的文件了 4---这里,我建议安装OpenCv2.4.9,我已经安装成功(https://github.com/bearpaw/Install-OpenCV, 5---下载成功后,进行解压 6---切换到OPenCv的目录下----cd Install-OpenCV/Ubuntu/2.4/ 7---给当前目录下的所有.sh脚本添加可执行权限:chmod a+x *.sh 8---安装OpenCv2.4.9:sudo ./opencv2_4_9.sh 5. 安装【dependencies】 1--sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler 2--Boost库(libboost-all-dev): 1--Boost库是一个功能强大,跨平台,开源且免费的库,被称为"C++的标准库",使用了很多现代的编程技术 2--Boost库的内容包含: 1--字符串处理 2--正则表达式 3--容器 4--数据结构 5--并发编程,函数式编程,泛型编程,设计模式等 3--Caffe中主要使用了: 1--Boost中的只能指针 2--Boost实现了C/C++和python的交互编程 3---HDF5(Hierarchical Data File) 1--HDF5是美国国家高级计算机应用中心(NCSA)为了满足各种领域研发的一种高效存储和分发科学数据的 新型数据格式 2--它可以存储不同类型的图像和数据文件 3--Caffe的训练模型可以保存为HDF5格式或者ProtoBuffer格式(默认) 4--ProtoBuffer是一种和硬盘文件读取的协议接口,Caffe中使用它权值和模型参数的载体 5--LMDB和LevelDB库 1---LMDB(Lightning Memory-Mapped Database Manger)(闪电般的内存映射行数据库管理器) 2---LMDB在caffe中的主要作用就是就是提供数据管理,它可以将形形色色的原始数据(JPEG图片,二进制 数据)转换为统一的Key-Value存储,以便Caffe的DataLayer获取这些数据 3---LevelDB是caffe的早起数据库管理器,现在已经被LMDB逐渐替代 6--GLOG库 1---GLOG库主要是Google开发的用于记录[应用程序日志的实用库] 2---GLOG提供基于C++标准输入输出流形式的接口,记录时可以选择不同的日志级别 3---方便将重要日志和普通的日志分开 1---GLOG在caffe中主要起到记录日志的作用,便于开发者查看Caffe训练中产生的中间输出 2---并根据这些信息决定如何调整参数来[控制收敛] 3---从日志文件,我们能够非常方便的看到程序运行的流程,边缘跟踪源码,定位问题 4---GLOG的使用方法可以参考Caffe源码中的tools/caffe.cpp 6. 配置和编译【Caffe】 1--下载Caffe源代码:git clone https://github.com/bvlc/caffe 2---切换到caffe目录下: cd ./caffe 3---给caffe的配置文件重命名: mv Makefile.config.example Makefile.config 4---如果你的电脑没有GPU,请修改配置文件 vim Makefile.config # CPU-only switch (uncomment to build without GPU support). CPU_ONLY := 1 5---编译caffe: make -j 主要修改的部分为: 1. 将# CPU_ONLY = 1前面的#去掉 并按“tab”键,(默认从tab处执行),因为这里没有安装GPU, 需要使用CPU运行。 2. BLAS := atlas, 这是默认设置,如果不是安装的这个,则需要修改。具体修改,该语句上面 有注释提示。 3. 设置MATLAB_DIR的路径:如我的是/usr/local/MATLAB/R2014a /************************************************************************************************************** *注意: *需要说明的一点是: * 全程的所有软件和库的安装,最好在(登陆用户下进行),不要在root权限下安装,不然后面有可能出现一系列的问题 **************************************************************************************************************/ /************************************************************************************************************** *(一)第一部分:caffe框架及其依赖库请具体参照以下博客: *http://m.blog.csdn.net/article/details?id=51803797 *http://www.cnblogs.com/sunshineatnoon/p/4535329.html *http://caffe.berkeleyvision.org/installation.html *http://www.cnblogs.com/empty16/p/4828476.html **************************************************************************************************************/ /************************************************************************************************************** *(二)第二部分:caffe的python可视化接口使用下面博客的安装方法 *http://www.cnblogs.com/sunshineatnoon/p/4535329.html **************************************************************************************************************/ /************************************************************************************************************** *(三)依照上面的教程安装之后,会有一个bug,可以参考下面的博客进行解决 * 1--遇见的bug为:No module named google.protobuf.internal * 2--错误原因:说明你没有添加goole.protobuf,internal的位置 * 3--解决方法: * 首先,在你的登陆用户(区别于超级用户root)下,输入python命令,进入python shell * 其次,依次输入以下python代码: import sys sys.path.append("/usr/lib/python2.7/dist-packages") import caffe 4--如果没有错误report,则说明python可视化接口配置成功 * 5--参考博客如下所示: * http://www.cnblogs.com/taokongcn/p/4341290.html **************************************************************************************************************/
1 基本信息
本机安装环境是,VMWare Workstation 10 安装64位的虚拟机Ubuntu 16.04
1.1 Ubuntu 系统信息
charles@charlesubuntuserver:~$ cat /etc/issue Ubuntu 16.04.2 LTS \n \l charles@charlesubuntuserver:~$ uname -a Linux charlesubuntuserver 4.4.0-62-generic #83-Ubuntu SMP Wed Jan 18 14:10:15 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
1.2 Caffe 地址
https://github.com/BVLC/caffe.git
2 安装过程
2.1 安装依赖
安装这些依赖的过程中,一次安装没有全部安装成功,解决方法是:经过sudo apt-get update之后,再继续安装。sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler sudo apt-get install --no-install-recommends libboost-all-dev sudo apt-get install libatlas-base-dev sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
2.2 配置及编译Caffe
从git中clone出源码后,修改Makefile.config:cp Makefile.config.example Makefile.config vi Makefile.config
找到#CPU_ONLY := 1,取消注释(我设置为CPU模式)
找到
# Whatever else you find you need goes here. INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib
修改为
# Whatever else you find you need goes here. INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial
如果是32位的Ubuntu,那么库路径应该是/usr/lib/i386-linux-gnu/hdf5/serial,若不确定,可以find 下libhdf5.a
随后进行编译:
make all make test make runtest安装好以后我们就可以试着在mnist上跑一下lenet了。1.首先获取mnist数据
cd caffe ./data/mnist/get_mnist.sh2.然后创建lenet
./examples/mnist/create_mnist.sh注意一定要在caffe的根目录下运行以下命令,否则会报“ build/examples/mnist/convert_mnist_data.bin: not found”的错误,参见这里。3.训练cnn没有gpu的话要记得把caffe/examples/mnist/lenet_solver.prototxt中的solver_mode设置成solver_mode: CPU。然后在根目录下执行:
./examples/mnist/train_lenet.sh
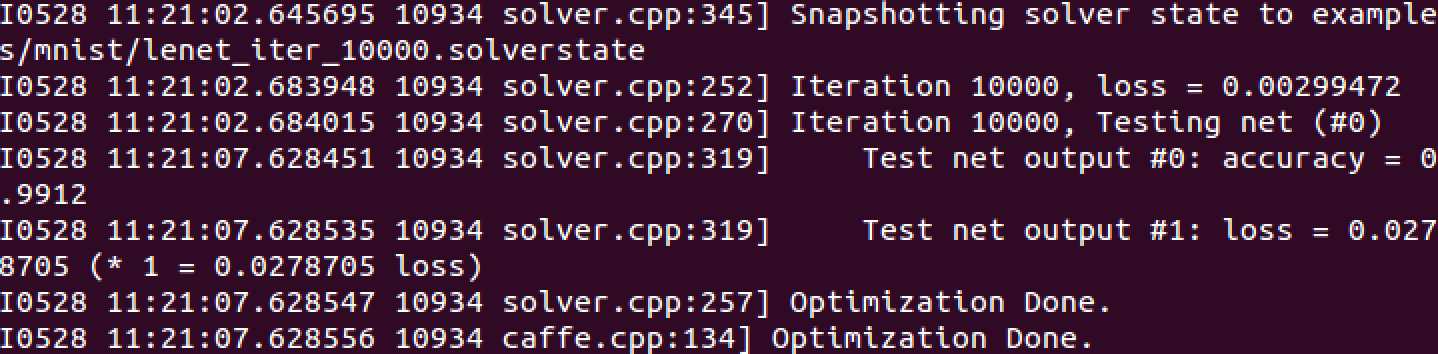
准确率可以达到0.9912因为caffe的tutorial上有很大一部分是python的,所以后来又安装了一下python的接口。 因为caffe的tutorial上有很大一部分是python的,所以后来又安装了一下python的接口。1.首先安装python2.安装pip
sudo apt-get install python-pip python-dev build-essential3.运行以下代码安装必要的依赖项:
sudo pip install -r ./python/requirements.txt4.这里我运行了make clean以及其他编译的caffe的命令,重新编译了一次caffe,但我不确定是不是必须的。5.在caffe的根目录下运行:
make pycaffe这里遇到了一个问题:
virtual memory exhausted: Cannot allocate memory make: *** [python/caffe/_caffe.so] Error 1按照这里的方法增加linux虚拟机的内存就可以解决了。6.把caffe/python的路径加到python路径中:运行python进入python shell,然后运行下列命令:
import sys
sys.path.append("path/to/caffe/python/")
exit()7. 这时候再次进入python shell,运行import caffe就没有报错了。 参考[1]http://blog.csdn.net/fengbingchun/article/details/45535741[2]http://caffe.berkeleyvision.org/install_apt.html

相关文章推荐
- 【深度学习】笔记1_Ubuntu14.04下caffe环境的搭建,无GPU版本以及python可视化环境的配置
- 【深度学习】 Ubuntu16.04 caffe Opencv2.4.13 GPU环境配置
- 深度学习环境配置Ubuntu16.04+CUDA8.0+CuDNN+Anaconda2+openCV2.4.9+caffe(全离线GPU版)
- 深度学习_caffe-ubuntu-GPU 配置环境(0)
- ubuntu16.04下安装配置深度学习环境(Ubuntu 16.04/16.10+ cuda7.5/8+cudnn4/5+caffe)
- 【深度学习】笔记17 windows下SSD网络在caffe中的配置(GPU版本)【笔记3】
- 深度学习笔记1 ——Ubuntu16.04下caffe环境的配置(仅CPU)
- Ubuntu16.04 +Caffe CPU/GPU 深度学习环境
- 【深度学习】笔记13 win10+cuda7.5+caffe+vs2013环境搭建(GPU版本)
- Caffe_Linux学习笔记(一)基于Ubuntu16.04+CPU only+Python2.7环境下的Caffe配置
- Ubuntu16.04+GTX1050ti+CUDA8.0+TensorFlow-gpu+Keras+Pycharm配置深度学习环境
- 深度学习主机环境配置: Ubuntu16.04 + GeForce GTX 1070 + CUDA8.0 + cuDNN5.1 + TensorFlow
- 深度学习环境搭建:linux下 Ubuntu16.04+cuda8.0+cudnn+anaconda+tensorflow并配置远程访问jupyter notebook
- Ubuntu16.04 安装配置GPU版本Caffe
- Ubuntu16.04+GTX1050+CUDA8.0配置深度学习环境
- 深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0
- 深度学习环境配置:ubuntu16.04 + cuda8.0 + cudnn5.1
- Ubuntu16.04配置GPU caffe 加Qt下caffe和opencv环境配置
- 深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0
- ubuntu 16.04 下配置深度学习环境之OpenCV的安装