搜索算法--线性搜索、二分搜索、内插搜索、剪枝搜索
2017-07-28 20:59
447 查看
1. 线性搜索
理论解释引自此处。Linear search is a very simple search algorithm. In this type of search, a sequential search is made over all items one by one. Every item is checked and if a match is found then that particular item is returned, otherwise the search continues till the end of the data collection.
线性搜索:最简单的搜索策略,顺序遍历数组元素,如果找到目标元素则退出。
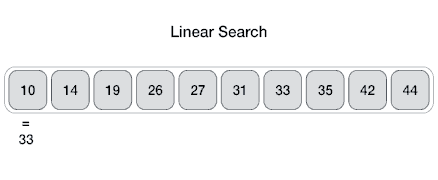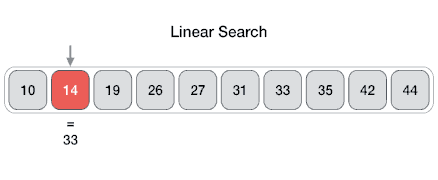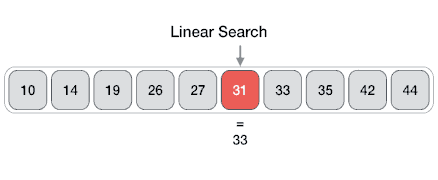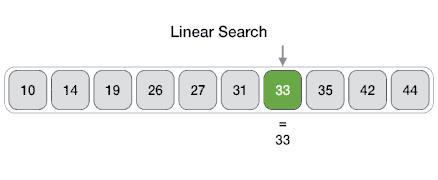
package com.fqyuan.search;
import java.util.Random;
import org.junit.Test;
public class LinearSearch {
public static int linearch(int[] arr, int target) {
int index = -1;
for (int i = 0; i < arr.length; i++) {
if (target == arr[i]) {
index = i;
break;
}
}
return index;
}
@Test
public void test() {
int[] arr = new int[100];
Random random = new Random();
for (int i = 0; i < arr.length; i++)
arr[i] = random.nextInt(arr.length);
SearchUtils.printArr(arr);
if (linearch(arr, 50) != -1)
System.out.println("Found 50 at: " + linearch(arr, 50));
else
System.out.println("Not found.");
}
}2. 二分搜索
Binary search is a fast search algorithm with run-time complexity of Ο(log n). This search algorithm works on the principle of divide and conquer. For this algorithm to work properly, the data collection should be in the sorted form.Binary search looks for a particular item by comparing the middle most item of the collection. If a match occurs, then the index of item is returned. If the middle item is greater than the item, then the item is searched in the sub-array to the left of the middle item. Otherwise, the item is searched for in the sub-array to the right of the middle item. This process continues on the sub-array as well until the size of the subarray reduces to zero.
二分搜索的要求及思想:二分搜索是采取divide and conquer分而治之思想,时间复杂度为(Ologn)的算法,在进行搜索之前,必须保证待搜索的的数组是有序的。
package com.fqyuan.search;
import java.util.Arrays;
import java.util.Random;
import org.junit.Test;
public class BinarySearch {
public static int binarySearchNonRec(int[] arr, int target) {
int low = 0;
int high = arr.length - 1;
int mid;
while (low <= high) {
mid = low + (high - low) / 2;
if (arr[mid] == target)
return mid;
else if (target < arr[mid])
high = mid - 1;
else {
low = mid + 1;
}
}
return -1;
}
public static int binarySearchRec(int[] arr, int target) {
return binarySearchRec(arr, target, 0, arr.length - 1);
}
private static int binarySearchRec(int[] arr, int target, int low, int high) {
if (low > high)
return -1;
int mid = low + (high - low) / 2;
if (arr[mid] == target)
return mid;
else if (target < arr[mid])
return binarySearchRec(arr, target, low, mid - 1);
else {
return binarySearchRec(arr, target, mid + 1, high);
}
}
@Test
public void test() {
int[] arr = new int[100];
Random random = new Random();
for (int i = 0; i < arr.length; i++)
arr[i] = random.nextInt(arr.length);
Arrays.sort(arr);
SearchUtils.printArr(arr);
if (binarySearchRec(arr, 50) != -1)
System.out.println("Found 50 at: " + binarySearchRec(arr, 50));
else
System.out.println("Not found.");
}
}//Running result: 7 53 89 52 5 93 33 75 75 75 34 63 2 89 30 59 20 46 54 29 33 14 66 80 5 50 73 70 30 82 39 89 48 27 76 62 58 17 50 1 19 41 36 33 83 53 23 57 73 61 21 10 86 15 28 3 80 46 41 87 81 83 27 65 14 56 56 45 84 30 79 52 82 25 2 22 25 47 3 61 58 86 70 93 50 5 71 47 80 5 36 59 15 11 93 46 62 6 20 18 Found 50 at: 25
3. 内插搜索
理论内容引自这里。Interpolation search is an improved variant of binary search. This search algorithm works on the probing position of the required value. For this algorithm to work properly, the data collection should be in a sorted form and equally distributed.
Binary search has a huge advantage of time complexity over linear search. Linear search has worst-case complexity of Ο(n) whereas binary search has Ο(log n).
There are cases where the location of target data may be known in advance. For example, in case of a telephone directory, if we want to search the telephone number of Morphius. Here, linear search and even binary search will seem slow as we can directly jump to memory space where the names start from ‘M’ are stored.
插值搜索:也有翻译为内插搜索的,是一种二分搜索的变形。为何有二分搜索而不是3分搜索、四分、n分搜索?这里部分解决了这个问题。如果数据不是均匀分的的情形,可以使用插值搜索快速逼近待搜索区域,从而提高效率。
package com.fqyuan.search;
import java.util.Arrays;
import java.util.Random;
import org.junit.Test;
public class InterpolateSearch {
public static int interpolateSearchNonRec(int[] arr, int target) {
int low = 0;
int high = arr.length - 1;
int mid;
while (target >= arr[low] && target <= arr[high]) {
if (arr[low] == arr[high])
return (low + high) / 2;
mid = low + (high - low) / (arr[high] - arr[low]) * (target - arr[low]);
if (target == arr[mid])
return mid;
else if (target < arr[mid])
high = mid - 1;
else
low = mid + 1;
}
return -1;
}
public static int interpolateSearchRec(int[] arr, int target) {
return interpolateSearchRec(arr, target, 0, arr.length - 1);
}
private static int interpolateSearchRec(int[] arr, int target, int low, int high) {
if (target == arr[low])
return low;
else if (low == high || arr[low] == arr[high])
return -1;
int mid = low + (high - low) / (arr[high] - arr[low]) * (target - arr[low]);
if (arr[mid] == target)
return mid;
else if (target < arr[mid])
return interpolateSearchRec(arr, target, low, mid - 1);
else
return interpolateSearchRec(arr, target, mid + 1, high);
}
@Test
public void test() {
int[] arr = new int[100];
Random random = new Random();
for (int i = 0; i < arr.length; i++)
arr[i] = random.nextInt(arr.length);
Arrays.sort(arr);
SearchUtils.printArr(arr);
if (interpolateSearchNonRec(arr, 50) != -1)
System.out.println("Found 50 at: " + interpolateSearchNonRec(arr, 50));
else
System.out.println("Not found.");
}
}//Running result: 0 0 0 0 0 0 1 1 3 4 4 5 5 6 10 11 15 16 19 21 23 24 24 26 27 27 29 29 29 30 36 38 38 40 40 40 41 41 41 41 43 44 45 46 47 49 50 51 51 52 52 52 53 54 54 55 56 56 58 59 60 61 63 64 65 66 66 67 68 72 74 74 76 78 79 83 84 84 84 85 85 86 87 88 89 89 89 91 91 91 93 93 93 94 95 95 96 96 98 98 Found 50 at: 46
4. 剪枝搜索
该部分内容引自此处,感兴趣可以自行查看。Prune and search is a method for finding an optimal value by iteratively dividing a search space into two parts – the promising one, which contains the optimal value and is recursively searched and the second part without optimal value, which is pruned (thrown away). This paradigm is very similar to well know divide and conquer algorithms.
A naive approach to find the n-th largest number in the given array would sort the whole array (using some O(n \cdot \log(n)) algorithm) and then it would return the n-th value. But this solution is very ineffective.
A better solution is to employ a modified prune-and-search version of quicksort algorithm. The original quicksort algorithm in the first phase divides the array into three parts – the first contains only elements higher than the pivot, the second part is the pivot itself, and the third part contains elements with less or equal value in comparison to the pivot. In the second phase quicksort recursively calls itself to sort part one and part three (pivot is already placed at its final position).
Modified prune-and-search algorithm advances similarly, in the first phase the array is divided exactly as in original algorithm, but in phase 2 only the part, which contains the n-th index, gets sorted. The two parts remaining are pruned, because they cannot contain a solution.
剪枝搜索:是一种搜索最大数字的性能较好的算法。修改自快速排序算法,大概是O(cn)的时间复杂度。
package com.fqyuan.search;
import java.util.Arrays;
import java.util.Random;
import org.junit.Test;
public class PruneSearch {
public static int pruneAndSearch(int[] arr, int targetIndex) {
return pruneAndSearch(arr, targetIndex, 0, arr.length - 1);
}
private static int pruneAndSearch(int[] arr, int targetIndex, int low, int high) {
int pivotIndex = partitionInc(arr, low, high);
if (pivotIndex == targetIndex)
return arr[pivotIndex];
else if (pivotIndex < targetIndex)
return pruneAndSearch(arr, targetIndex, pivotIndex + 1, high);
else
return pruneAndSearch(arr, targetIndex, low, pivotIndex - 1);
}
private static int partitionInc(int[] arr, int low, int high) {
int pivotIndex = low;
int pivotValue = arr[high];
for (int i = low; i < high; i++) {
if (arr[i] < pivotValue)
swap(arr, i, pivotIndex++);
}
swap(arr, pivotIndex, high);
return pivotIndex;
}
private static int partitionDec(int[] arr, int low, int high) {
int pivotIndex = low;
int pivotValue = arr[low];
for (int i = low + 1; i <= high; i++) {
if (arr[i] > pivotValue)
swap(arr, i, ++pivotIndex);
}
swap(arr, low, pivotIndex);
return pivotIndex;
}
private static void swap(int[] arr, int start, int end) {
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
}
@Test
public void test() {
int[] arr = new int[100];
Random random = new Random();
for (int i = 0; i < arr.length; i++)
arr[i] = random.nextInt(arr.length);
Arrays.sort(arr);
SearchUtils.printArr(arr);
System.out.println("Found 0th value: " + pruneAndSearch(arr, 6));
}
}//Running result: 0 0 1 1 3 3 6 6 7 8 9 11 12 13 13 14 14 14 15 16 17 19 19 21 21 22 22 23 24 26 27 29 30 30 30 31 32 32 37 39 40 40 40 41 43 44 45 47 48 49 50 51 52 52 54 55 56 59 60 60 62 63 65 65 65 66 66 66 70 71 73 75 75 75 76 77 77 77 78 80 81 83 83 84 84 86 86 88 90 93 93 93 93 94 95 97 97 98 98 99 Found 0th value: 6

相关文章推荐
- (1)线性查找和二分搜索
- 搜索算法-二分搜索-方程解问题(problem 1002)
- hihocoder hiho第38周: 二分·二分答案 (二分搜索算法应用:二分搜索值+bfs判断可行性 )
- 搜索算法:顺序搜索和二分搜索
- 搜索算法----线性搜索、二叉搜索
- 搜索之线性搜索和二分搜索
- 【总结】搜索的剪枝二分预处理和离散化等优化
- 算法设计技巧与分析(1)二分搜索的前提——线性搜索
- 搜索算法-二分搜索(折半查找)
- BZOJ 1082 栅栏 (二分 剪枝搜索)
- 搜索算法-二分搜索-方程解问题(problem 1001)
- [折半搜索 剪枝 随机化染色] 2015 计蒜之道 复赛 腾讯的星钻增值服务
- 搜索_Poj 1465_剪枝_余数判重
- POJ 3111 K Best(二分搜索,最大化平均值)
- poj 3258 River Hopscotch 二分搜索
- 算法笔记——【分治法】分治法与二分搜索
- Luogu P1092 虫食算【搜索/剪枝】 By cellur925
- UVALive2678 UVA1121 Subsequence【前缀和+二分搜索+尺取法】
- 5-4 二分搜索数的查找