Elasticsearch实战——全文检索架构设计
2017-07-02 09:22
260 查看
1、题记
近几年,Elasticsearch(以下简称ES)作为开源的搜索引擎已经在国内得到越来越多的应用推广,在日志分析领域应用场景尤为广泛。传统的数据库Mysql、Oracle或者非关系型数据库Mongo作为基础存储的企业要想实现业务数据的全文检索,该如何实现呢?本文给出架构设计和实现原理。
2、理清楚使用ES的初衷
2.1 大数据背景下数据量的积累与数据应用疲软矛盾一直存在。
大数据的风已经刮了几年,西安交大徐宗本院士也强调“推动大数据产业必须解决好定位、规划、切入点、数据标准、开发共享等问题,互联互通是基础、定制化服务是中心、懂数据会分析是关键”。可见,数据分析的重要性。传统企业的数据存储存在以下问题:
问题1:由于模型受限,传统企业的数据大多存储在关系型数据库Mysql、Oracle,非结构化数据存储在Mongo中。数据量也能积累到TB甚至PB级。
只能进行结构化的检索类似”select * from table where col like ‘%xxx%’显然不能满足纷繁复杂的业务需求。
问题2:数据是死数据,数据的BI可视化展示需要专业团队开发,但不能得到很好的分析效果。
以上问题形成了数据量累计到一定的量,但数据得不到很好的应用分析之间的矛盾。
2.2 在保持基础数据库不动的同时,新增全文检索,更好、更快的从亿万数据中获取检索服务。
不想抛弃原有的数据存储结构,想在原有数据存储的基础上新增全文检索。3、传统存储模型上的ES全文检索架构
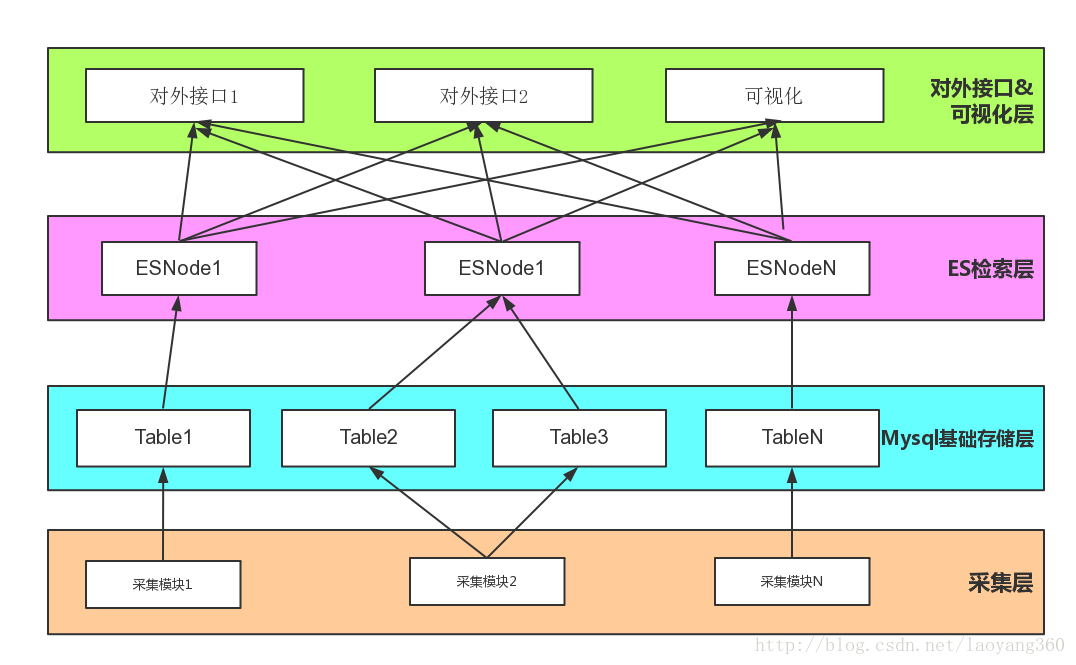
3.1 采集层
解决数据源头问题。业务模型的不同,有的数据是机器设备(软件、硬件)产生的,有的则需要自己开发爬虫(如:python的scrapy)进行互联网全网爬取或者定向网站爬取。
3.2 Mysql基础存储层
基础数据的存储。定义好库表结构、关联关系、主键、外键结构来存储结构化数据。
或者非结构化数据,采用Mongo键值对的方式存储。
3.3 ES检索层
实现基础数据的同步。这里是关键,传统的业务模型会在Mysql基础层的基础上,开展业务数据分析通常是以下步骤:步骤1:后台数据——库表分散的建立视图,对数据做分门别类的统计(基于order by, group by等操作)。
步骤2:前端可视化——通过 Angularjs 进行数据渲染,并通过百度的Echart模型进行可视化展示。
ES检索层的准备如下:
方式1.数据同步——基础业务数据由基础库Mysql、Oracle或Mongolia同步到ES中,大多需要借助logstash实现。
同步策略参见:http://blog.csdn.net/laoyang360/article/details/72792865
方式2.数据同步——数据存成json格式文件,然后借助阿里的fastjson解析,以bulk方式批量导入ES。
3.4 对外接口及可视化层
实现ES全文检索、Tag检索等对外服务、数据的分类统计、排序等可视化展示。java接口可以参考jest实现。
可视化可以借助kibana实现。这里就体现出elkstack的优势,logstash完成基础数据同步,es完成数据存储和检索,kibana完成数据可视化。
4.架构小结
以上是我研究ES近一年时间的实战总结。其中,ES检索、kibana可视化的深入应用还有很长的路要走。欢迎就架构问题深入留言探讨!
——————————————————————————————————
更多ES相关实战干货经验分享,请扫描下方【铭毅天下】微信公众号二维码关注。
(每周至少更新一篇!)

和你一起,死磕Elasticsearch!
——————————————————————————————————
2017-07-02 09:23 思于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
http://blog.csdn.net/laoyang360/article/details/74090398
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!

相关文章推荐
- 【Lucene】Apache Lucene全文检索引擎架构之入门实战
- Elasticsearch全文检索实战小结
- 我心中的核心组件(可插拔的AOP)~第十四回 全文检索架构~终于设计了一个自己满意的Lucene架构
- 【Lucene】Apache Lucene全文检索引擎架构之入门实战
- 【Lucene】Apache Lucene全文检索引擎架构之入门实战1
- [置顶] 《从Lucene到Elasticsearch:全文检索实战》已出版!
- Elasticsearch全文检索实战小结——复盘我带的第二个项目
- 基于Sphinx+MySQL全文检索架构设计
- Elasticsearch全文检索企业开发记录总结(一):整体架构
- 基于.NET平台的分层架构实战(六)——依赖注入机制及IoC的设计与实现
- 实战CRM系统项目:3.系统架构设计
- 基于.NET平台的分层架构实战(五)接口的设计与实现
- 基于.NET平台的分层架构实战(四)——实体类的设计与实现
- 基于.NET平台的分层架构实战(五)——接口的设计与实现
- [原创].NET 分布式架构开发实战之二 草稿设计.NET 分布式架构开发实战之二 草稿设计
- 基于.NET平台的分层架构实战(六)——依赖注入机制及IoC的设计与实现
- [原创].NET 分布式架构开发实战之二 草稿设计
- 基于.NET平台的分层架构实战(二)——需求分析与数据库设计
- 网站全文检索设计
- 【架构设计】需求分析 实战